About Authentication Nodes
Authentication trees (also referred to as Intelligent Authentication) provide fine-grained authentication by allowing multiple paths and decision points throughout the authentication flow.
Authentication trees are made up of authentication nodes, which define actions taken during authentication, similar to authentication modules within chains.
You can create complex yet customer-friendly authentication experiences by linking nodes together, creating loops, and nesting nodes within a tree, as follows:
Nodes are designed to be single-responsibility, and where appropriate should be loosely coupled to other nodes, enabling reuse in multiple situations.
For example, if a newly written node requires a username value, it should not collect it itself, but rely on another node, namely the Username Collector Node.
Types of Nodes
- Collector Nodes
Collector nodes capture data from a user during the authentication process. This data is often captured by a callback that is rendered in the UI as a text field, drop-down list, or other form component.
Examples of collector nodes includes the Username Collector Node and Password Collector Node.

Collector nodes may perform some basic processing of the collected data before making it available to subsequent nodes in the authentication tree.
The Choice Collector Node provides a drop-down list populated with options defined when the tree is created, or edited.

Not all collector nodes use callbacks. For example, the Zero Page Login Collector Node retrieves a username and password value from the request headers, if present.
- Decision Nodes
Decision nodes retrieve the state produced by one or more nodes, perform some processing on it, optionally store some derived information in the shared state, and provide one or more outcomes depending on the result.
The simplest decision node returns a boolean outcome -
true, orfalse.Complex nodes may have additional outcomes. For example the LDAP Decision Node offers additional outcomes of Locked and Expired. The tree administrator decides what to do with each outcome; for example, the
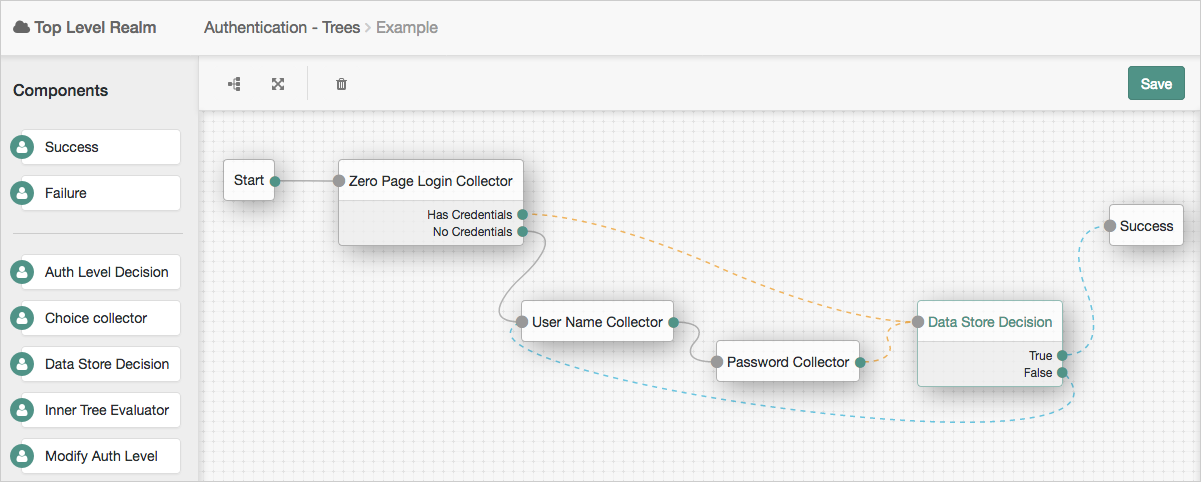
Trueoutcome is often routed to a Success node, or to additional nodes for further authentication.In the following example tree, two collector nodes are connected before a Data Store Decision Node. The node then uses the credentials to authenticate the user against the identity stores configured for the realm. In this instance, an unsuccessful login attempt leads directly to failure; the user must restart the process from scratch.
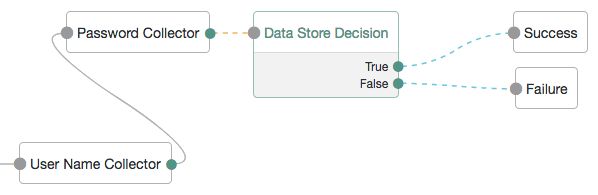
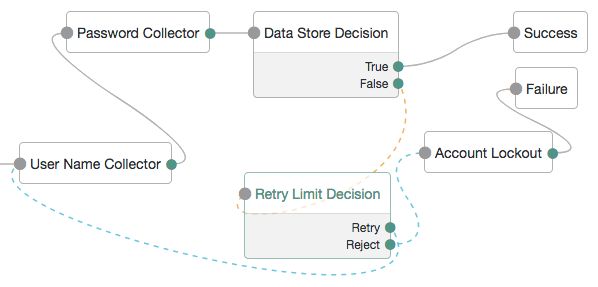
A more user-friendly approach might route unsuccessful attempts to a Retry Limit Decision Node. In the following example, unsuccessful authentication attempts at the Data Store Decision Node stage are routed into a Retry Limit Decision Node. Depending on how many retries have been configured, the node either retries or rejects the new login attempt. Rejected attempts lead to a locked account.



Note
Nodes May Have Prerequisite Stages
Some Decision Nodes are only applicable when used in conjunction with other nodes. For example, the Persistent Cookie Decision Node looks for a persistent cookie that has been set in the request, typically by the Set Persistent Cookie Node. The OTP Collector Decision Node, which is both a collector and a decision node, only works when used in conjunction with a one-time password generated by a HOTP Generator Node.
Differences Between Modules and Nodes
Authentication modules contain multiple states, with the associated inputs and outputs of each state resulting in either callbacks returned to the user, or state changes inside either AM or at a third party service.
States within a module either collect input from the user or process it. For example, a module can collect the username and the password from the user and then authenticate the user against the data store. When finished, the module decides whether to return a boolean success or failure flag.
The outcome of an authentication module can only be success or failure. Any branching or looping must be handled within the module. An authentication mechanism is implemented in full within a single module, rather than across multiple modules. Therefore, authentication modules can become large - handling multiple steps within the flow of an authentication journey.
Authentication nodes, however, can have an arbitrary number of outcomes that do not need to represent success or failure. Branching and looping are handled by connecting nodes within the tree and are fully controlled by the tree administrator, rather than the node developer. Nodes are often considerably smaller in terms of code size, and are responsible for handling a single step within the authentication flow. For example, an individual node could capture user input, another could make a decision based on available state, and another could invoke an external API.
Nodes expose this approach to the tree administrator. Unlike modules, where the journey through the module's states is defined by the module's developer, a journey through a collection of nodes may be different for each user.
Node developers should be aware of the expectations for a node to deliver a limited amount of specific functionality, which tree administrators can connect together in a variety of ways.
Nodes are responsible for a single step of the authentication flow. Modules are responsible for an entire authentication mechanism.
Tree administrators control the branching, looping, and sequencing of steps by linking nodes together. Module developers set these state transitions within the module itself.
Nodes are stateless; instances of node objects are not retained between HTTP requests, and all state captured must be saved to the authentication session's shared state. Modules store state within the module object.
Node configuration is handled with annotations. Modules use XML.
Nodes are easier to test due to their smaller code size and their specific functionality.
Converting Modules to Nodes
The ease of transitioning from a module to a node depends on the amount of functionality provided in the module. As nodes are more fine-grained than modules, split the functionality of the module into individual nodes which can then work together to provide functionality similar to the module, but in a more flexible manner.
An example of this approach was applied to the one-time password nodes, which were developed from the HOTP authentication module. The module performs the following duties:
Generates one-time passwords.
Sends one-time passwords by using SMS messaging.
Sends one-time passwords by using SMTP.
Collects and verifies the one-time password.
The four distinct functions are encapsulated into separate nodes, allowing greater control over the one-time password process.
For example, a tree administrator who is only interested in sending one-time passwords by using SMS messages can omit the SMTP node. Separating out the decision functionality means that it can be combined with another decision node, or simply routed to an alternative authentication process.
Some authentication modules delegate their functionality to utility classes in AM, which simplifies the process of creating a similarly functioning node.
For example, the LDAP authentication module and LDAP Decision Node share the LDAPAuthUtils class for LDAP authentication. In cases where such utility classes do not exist, consider extracting the common functionality used by the module into such a class, so that it can be more easily used by nodes. For information on sharing configuration, see "Sharing Configuration Between Nodes".
Determining the Functionality of a Node
To determine the functionality of a node, it is important to reduce the responsibility to its core purpose, while ensuring it performs enough tasks to be useful as a step in an authentication journey.
Before creating a set of nodes, a node developer must first understand the level of granularity they should produce. For example, a customer's environment may require a series of utility nodes which, on their own, do not perform authentication actions, but have multiple use cases in many authentication journeys. In this case, the developer may create nodes that take values from the shared state and save it to the user's profile.
Individual nodes can respond to a variety of inputs and outputs, and return different sets of callbacks to the user - similar to the state mechanism used by modules - without leaving the node.
The following guidelines help a node developer to determine the best point at which to split a node into multiple instances:
If a node's process method takes input from the user, and then immediately processes it.
Consider splitting the functionality over two nodes. A collector node returns callbacks to the user, and stores the response in the shared state. A decision node uses the inputs collected so far in the tree to determine the next course of action.
A node that takes input from the user and makes a decision should only be designed as a single node if there is no possible additional use for the data gathered, other than making that specific decision.
If a processing stage in a node is duplicated in other nodes.
In this case, take the repeating stage out and place it in its own node. Connect this node appropriately to each of the other nodes.
If multiple nodes contain the same step in processing, such as returning a set of callbacks to ask the user for a set of data before processing it in different ways, the common functionality should be pulled out into its own node.
If a single function within the node has obvious use cases in other authentication journeys.
In this case, the functionality should be written into a single, reusable node. For example, in multi-factor authentication, a mechanism for reporting a lost device is applicable to many node types, such as mobile push, OATH, and others.