Install a Multi-Node Deployment
This section presents instructions on deploying Autonomous Identity in a multi-node deployment. Multi-node deployments are configured in production environments, providing performant throughput by distributing the processing load across servers and supporting failover redundancy.
Like single-node deployment, ForgeRock provides a deployer script that pulls a Docker image from
ForgeRock’s Google Cloud Registry (gcr.io) repository. The image contains the microservices, analytics, and
backend databases needed for the system. The deployer also uses the node IP addresses specified in your hosts file
to set up an overlay network and your nodes.
| The topology presented in this section is a generalized example that is used in our automated testing. Each production deployment is unique and requires proper review prior to implementation. |
For production, the example assumes that you run the deployer on a dedicated low-spec box. After you set up your
environment and back up the autoid-config directory, you can recycle the deployer box.
|
Figure 8: An example multi-node deployment.
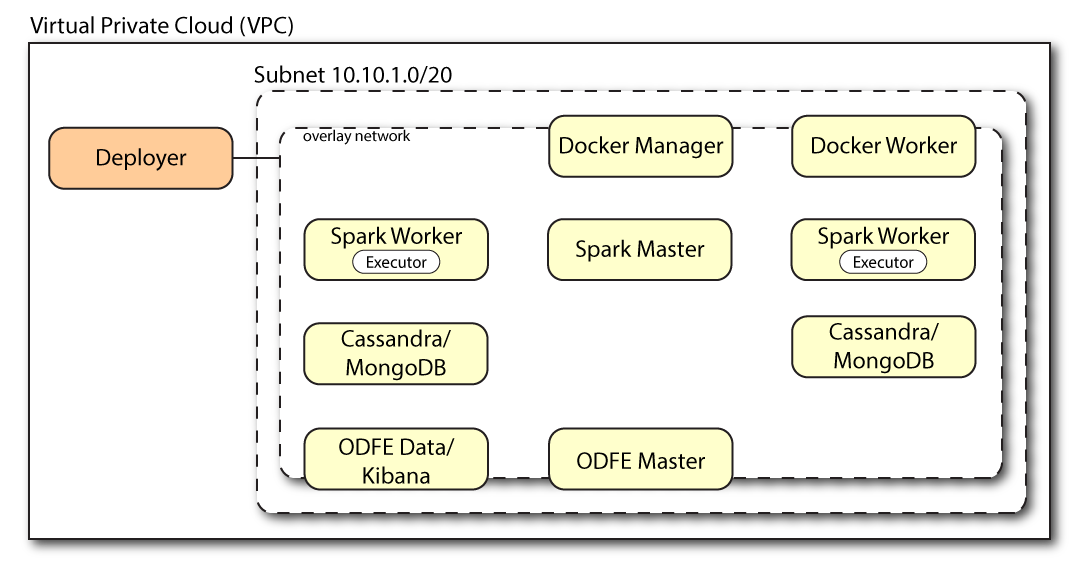
Prerequisites
Let’s deploy Autonomous Identity on a multi-node target on CentOS 7. The following are prerequisites:
-
Operating System. The target machine requires CentOS 7. The deployer machine can use any operating system as long as Docker is installed. For this chapter, we use CentOS 7 as its base operating system.
-
Default Shell. The default shell for the
autoiduser must bebash. -
Subnet Requirements. We recommend deploying your multi-node machines within the same subnet. Ports must be open for the installation to succeed. Each instance should be able to communicate to the other instances.
If any hosts used for the Docker cluster (docker-managers, docker-workers) have an IP address in the range of 10.0.x.x, they will conflict with the Swarm network. As a result, the services in the cluster will not connect to the Cassandra database or Elasticsearch backend.
The Docker cluster hosts must be in a subnet that provides IP addresses 10.10.1.x or higher.
-
Deployment Requirements. Autonomous Identity provides a
deployer.shscript that downloads and installs the necessary Docker images. To download the deployment images, you must first obtain a registry key to log into the ForgeRock Google Cloud Registry (gcr.io). The registry key is only available to ForgeRock Autonomous Identity customers. For specific instructions on obtaining the registry key, see How To Configure Service Credentials (Push Auth, Docker) in Backstage. -
Filesystem Requirements. Autonomous Identity requires a shared filesystem accessible from the Spark master, Spark worker, analytics hosts, and application layer. The shared filesystem should be mounted at the same mount directory on all of those hosts. If the mount directory for the shared filesystem is different from the default,
/data, update the/autoid-config/vars.ymlfile to point to the correct directories:analytics_data_dir: /data analytics_conf_dif: /data/conf
-
Architecture Requirements. Make sure that the Spark master is on a separate node from the Spark workers.
-
Database Requirements. Decide which database you are using: Apache Cassandra or MongoDB. The configuration procedure is slightly different for each database.
-
Deployment Best-Practice. The example combines the ODFE data and Kibana nodes. For best performance in production, dedicate a separate node to Elasticsearch, data nodes, and Kibana.
-
IPv4 Forwarding. Many high-security environments run their CentOS-based systems with IPv4 forwarding disabled. However, Docker Swarm does not work with a disabled IPv4 forward setting. In such environments, make sure to enable IPv4 forwarding in the file
/etc/sysctl.conf:net.ipv4.ip_forward=1
| We recommend that your deployer team have someone with Cassandra expertise. This guide is not sufficient to troubleshoot any issues that may arise. |
Example Topology
Make sure you have sufficient storage for your particular deployment. For more information on sizing considerations, see Deployment Planning Guide.
| Each deployment is unique and should be discussed with your installer and ForgeRock. |
For this example, use the following configuration for this example multi-node deployment:
Num Nodes |
Cores |
Memory |
|
Deployer |
1 |
2 vCPU |
4 GB |
Docker Manager |
1 |
8 vCPU |
32 GB |
Docker Worker |
1 |
8 vCPU |
32 GB |
Cassandra Seeds |
2 |
8 vCPU |
32 GB |
Spark Master |
1 |
16 vCPU |
64 GB |
Spark Worker |
2 |
8 vCPU |
32 GB |
Elasticsearch (ODFE) Master/Kibana |
1 |
8 vCPU |
32 GB |
ODFE Data |
1 |
8 vCPU |
32 GB |
Set Up the Nodes
Set up your VMs based on the Example Topology.
-
For each VM, make sure that you have CentOS 7 as your operating system. Check your CentOS 7 version.
$ sudo cat /etc/centos-release
-
Set the user for the target node to a username of your choice:
-
In this example, create user
autoid.$ sudo adduser autoid
-
Set the password for the user you created in the previous step.
$ sudo passwd autoid
-
Configure the user for passwordless sudo.
$ echo "autoid ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/autoid
-
Add administrator privileges to the user.
$ sudo usermod -aG wheel autoid
-
-
Change to the user account.
$ su - autoid
-
Install yum-utils package on the deployer machine. yum-utils is a utilities manager for the Yum RPM package repository. The repository compresses software packages for Linux distributions.
$ sudo yum install -y yum-utils
Install Docker on the Deployer Machine
Install Docker on the deployer machine. We run commands from this machine to install Autonomous Identity on the target machine. In this example, we use CentOS 7.
-
Change to the user account.
$ su - autoid
-
Create the installation directory. Note that you can use any install directory for your system as long as your run the
deployer.shscript from there. Also, the disk volume where you have the install directory must have at least 8GB free space for the installation.$ mkdir autoid-config
-
Set up the Docker-CE repository.
$ sudo yum-config-manager \ --add-repo https://download.docker.com/linux/centos/docker-ce.repo -
Install the latest version of the Docker CE, the command-line interface, and containerd.io, a containerized website.
$ sudo yum install -y docker-ce docker-ce-cli containerd.io
-
Enable Docker to start at boot.
$ sudo systemctl enable docker
-
Start Docker.
$ sudo systemctl start docker
-
Check that Docker is running.
$ systemctl status docker
-
Add the user to the Docker group.
$ sudo usermod -aG docker ${USER} -
Logout of the user account.
$ logout
-
Re-login using created user. Login with the user created for the deployer machine. For example,
autoid.$ su - autoid
Set Up SSH on the Deployer
-
On the deployer machine, change to the
~/.sshdirectory.$ cd ~/.ssh
-
Run
ssh-keygento generate an RSA keypair, and then click Enter. You can use the default filename.Do not add a key passphrase as it results in a build error. $ ssh-keygen -t rsa -C "autoid"
The public and private rsa key pair is stored in
home-directory/.ssh/id_rsaandhome-directory/.ssh/id_rsa.pub. -
Copy the SSH key to the
autoid-configdirectory.$ cp id_rsa ~/autoid-config
-
Change the privileges to the file.
$ chmod 400 ~/autoid-config/id_rsa
-
Copy your public SSH key,
id_rsa.pub, to each of your nodes.If your target system does not have an ~/.ssh/authorized_keys, create it usingsudo mkdir -p ~/.ssh, thensudo touch ~/.ssh/authorized_keys.For this example, copy the SSH key to each node:
$ ssh-copy-id -i id_rsa.pub autoid@<Node IP Address>
-
On the deployer machine, test your SSH connection to each target machine. This is a critical step. Make sure the connection works before proceeding with the installation.
For example, SSH to first node:
$ ssh -i id_rsa autoid@<Node 1 IP Address> Last login: Sat Oct 3 03:02:40 2020
-
If you can successfully SSH to each machine, set the privileges on your
~/.sshand~/.ssh/authorized_keys.$ chmod 700 ~/.ssh && chmod 600 ~/.ssh/authorized_keys
-
Enter Exit to end your SSH session.
-
Repeat steps 5–8 again for each node.
Set Up a Shared Directory
The analytics master and worker nodes require a shared directory, typically, /data. There are numerous ways to set up a shared directory, the following
procedure is just one example and sets up an NFS server on the analytics master.
-
On the Analytics Spark Master node, install
nfs-utils. This step may require that you run the install with root privileges, such assudoor equivalent.$ sudo yum install -y nfs-utils
-
Create the
/datadirectory.$ mkdir -p /data
-
Change the permissions on the
/datadirectory.$ chmod -R 755 /data $ chown nfsnobody:nfsnobody /data
-
Start the services and enable them to start at boot.
$ systemctl enable rpcbind $ systemctl enable nfs-server $ systemctl enable nfs-lock $ systemctl enable nfs-idmap $ systemctl start rpcbind $ systemctl start nfs-server $ systemctl start nfs-lock $ systemctl start nfs-idmap
-
Define the sharing points in the
/etc/exportsfile.$ vi /etc/exports /data <Remote IP Address 1>(rw,sync,no_root_squash,no_all_squash) /data <Remote IP Address 2>(rw,sync,no_root_squash,no_all_squash)
If you change the domain name and target environment, you need to also change the certificates to reflect the new changes. For more information, see Customize Domains.
-
Start the NFS service.
$ systemctl restart nfs-server
-
Add the NFS service to the
firewall-cmdpublic zone service:$ firewall-cmd --permanent --zone=public --add-service=nfs $ firewall-cmd --permanent --zone=public --add-service=mountd $ firewall-cmd --permanent --zone=public --add-service=rpc-bind $ firewall-cmd --reload
-
On each spark worker node, run the following:
-
Install
nfs-utils:$ yum install -y nfs-utils
-
Create the NFS directory mount points:
$ mkdir -p /data
-
Mount the NFS shared directory:
$ mount -t nfs <NFS Server IP>:/data /data
-
Test the new shared directory by creating a small text file. On an analytics worker node, run the following, and then check for the presence of the test file on the other servers:
$ cd /data $ touch test
-
Change Network Kernal Settings for Cassandra
The default network kernal setttings require overriding the default values to ensure TCP buffers are properly sized for use with Cassandra.
| If you are running an evaluation deployment with a small dataset, you can skip this section. For production deployments using Cassandra, run these instructions. |
For each Cassandra seed node, run the following steps:
-
SSH to a Cassandra seed machine.
-
Change to the default user. In this example,
autoid. -
Open a text editor and edit the
/etc/sysctl.conffile. Add the following settings to the file:net.core.rmem_max=16777216 net.core.wmem_max=16777216 net.core.rmem_default=16777216 net.core.wmem_default=16777216 net.core.optmem_max=40960 net.ipv4.tcp_rmem=4096 87380 16777216 net.ipv4.tcp_wmem=4096 65536 16777216 vm.max_map_count=1048575
-
At runtime, make sure swap is not used. For a permanent change, modify
/etc/fstabfile.$ sudo swapoff -a
-
Disable defrag of huge pages. The following command must be executed at each boot:
$ echo never | sudo tee /sys/kernel/mm/transparent_hugepage/defrag
-
Set the proper ulimits for the user running Cassandra by setting them in the
/etc/security/limits.conffile. In this example, the user running Cassandra isautoid.Open a text editor, and add the following settings in the
/etc/security/limits.conffile:autoid - memlock unlimited autoid - nofile 100000 autoid - nproc 32768 autoid - as unlimited
Install Autonomous Identity
Before you begin, make sure you have CentOS 7 installed on your target machine.
-
On the deployer machine, change to the installation directory.
$ cd ~/autoid-config/
-
Obtain the registry key for the ForgeRock Google Cloud Registry (gcr.io). The registry key is only available to ForgeRock Autonomous Identity customers. For specific instructions on obtaining the registry key, see How To Configure Service Credentials (Push Auth, Docker) in Backstage.
-
Log in to the ForgeRock Google Cloud Registry (gcr.io) using the registry key.
$ docker login -u _json_key -p "$(cat autoid_registry_key.json)" https://gcr.io/forgerock-autoid
You should see:
Login Succeeded
-
Run the
create-templatecommand to generate thedeployer.shscript wrapper. Note that the command sets the configuration directory on the target node to/config. Note that the--userparameter eliminates the need to usesudowhile editing the hosts file and other configuration files.$ docker run --user=$(id -u) -v ~/autoid-config:/config -it gcr.io/forgerock-autoid/deployer:2021.8.6 create-template
Configure Autonomous Identity
The create-template command from the previous section creates a number of configuration files, required for the
deployment: ansible.cfg, vars.yml, vault.yml, and hosts.
-
On the deployer node, change to the
autoid-config/directory. -
Check the
ansible.cfgfile for the remote user and SSH private key file location. If you followed these instruction, the default settings should be in place, which will not require any edits to theansible.cfgfile.[defaults] host_key_checking = False remote_user = autoid private_key_file = id_rsa
-
On the deployer machine, open a text editor and edit the
~/autoid-config/vars.ymlfile to configure specific settings for your deployment:-
AI Product. Do not change this property.
ai_product: auto-id
-
Domain and Target Environment. Set the domain name and target environment specific to your deployment by editing the
/autoid-config/vars.xmlfile. By default, the domain name is set toforgerock.comand the target environment is set toautoid. The default Autonomous Identity URL will be:https://autoid-ui.forgerock.com. For this example, we use the default values.domain_name: forgerock.com target_environment: autoid
If you change the domain name and target environment, you need to also change the certificates to reflect the new changes. For more information, see Customize Domains.
-
Analytics Data Directory and Analytics Configuration Direction. For a multi-node Spark deployment, Autonomous Identity requires a shared filesystem accessible from Spark Master, Spark Worker(s), and Analytics hosts. The shared filesystem should be mounted at same mount directory on all of the above hosts. If the mount directory for shared filesystem is different than
/data, update the following properties in thevars.yamlfile to point to the correct location:analytics_data_dir: /data analytics_conf_dif: /data/conf
-
Database Type. By default, Apache Cassandra is set as the default database for Autonomous Identity. For MongoDB, set the
db_driver_type:tomongo.db_driver_type: cassandra
-
Private IP Address Mapping. You can skip this step as we use the private IP addresses in the subnet.
-
Authentication Option. This property has three possible values:
-
Local.
Localindicates that sets up elasticsearch with local accounts and enables the Autonomous Identity UI features: self-service and manage identities. Local auth mode should be enabled for demo environments only. -
SSO.
SSOindicates that single sign-on (SSO) is in use. With SSO only, the Autonomous Identity UI features, self-service and manage identities pages, is not available on the system but is managed by the SSO provider. The login page displays "Sign in using OpenID." For more information, see Set Up SSO. -
LocalAndSSO.
LocalAndSSOindicates that SSO is used and local account features, like self-service and manage identities are available to the user. The login page displays "Sign in using OpenID" and a link "Or sign in via email".authentication_option: "Local"
-
-
Access Log. By default, the access log is enabled. If you want to disable the access log, set the
access_log_enabledvariable to "false". -
JWT Expiry and Secret File. Optional. By default, the session JWT is set at 30 minutes. To change this value, set the
jwt_expiryproperty to a different value.jwt_expiry: "30 minutes" jwt_secret_file: "{{install path}}"/jwt/secret.txt" jwt_audience: "http://my.service" oidc_jwks_url: "na" -
Local Auth Mode Password. When
authentication_optionis set toLocal, thelocal_auth_mode_passwordsets the password for the login user. -
SSO. Use these properties to set up SSO. For more information, see Set Up SSO.
-
MongoDB Configuration. For MongoDB clusters, enable replication by uncommenting the
mongodb_replication_replsetproperty.# uncomment below for mongo with replication enabled. Not needed for single node deployments mongodb_replication_replset: mongors
Also, enable a custom key for inter-machine authentication in the clustered nodes.
# custom key # password for inter-process authentication # please regenerate this file on production environment with # command 'openssl rand -base64 741' mongodb_keyfile_content: | 8pYcxvCqoe89kcp33KuTtKVf5MoHGEFjTnudrq5BosvWRoIxLowmdjrmUpVfAivh CHjqM6w0zVBytAxH1lW+7teMYe6eDn2S/O/1YlRRiW57bWU3zjliW3VdguJar5i Z+1a8lI+0S9pWynbv9+Ao0aXFjSJYVxAm/w7DJbVRGcPhsPmExiSBDw8szfQ8PAU 2hwRl7nqPZZMMR+uQThg/zV9rOzHJmkqZtsO4UJSilG9euLCYrzW2hdoPuCrEDhu Vsi5+nwAgYR9dP2oWkmGN1dwRe0ixSIM2UzFgpaXZaMOG6VztmFrlVXh8oFDRGM0 cGrFHcnGF7oUGfWnI2Cekngk64dHA2qD7WxXPbQ/svn9EfTY5aPw5lXzKA87Ds8p KHVFUYvmA6wVsxb/riGLwc+XZlb6M9gqHn1XSpsnYRjF6UzfRcRR2WyCxLZELaqu iKxLKB5FYqMBH7Sqg3qBCtE53vZ7T1nefq5RFzmykviYP63Uhu/A2EQatrMnaFPl TTG5CaPjob45CBSyMrheYRWKqxdWN93BTgiTW7p0U6RB0/OCUbsVX6IG3I9N8Uqt l8Kc+7aOmtUqFkwo8w30prIOjStMrokxNsuK9KTUiPu2cj7gwYQ574vV3hQvQPAr hhb9ohKr0zoPQt31iTj0FDkJzPepeuzqeq8F51HB56RZKpXdRTfY8G6OaOT68cV5 vP1O6T/okFKrl41FQ3CyYN5eRHyRTK99zTytrjoP2EbtIZ18z+bg/angRHYNzbgk lc3jpiGzs1ZWHD0nxOmHCMhU4usEcFbV6FlOxzlwrsEhHkeiununlCsNHatiDgzp ZWLnP/mXKV992/Jhu0Z577DHlh+3JIYx0PceB9yzACJ8MNARHF7QpBkhtuGMGZpF T+c73exupZFxItXs1Bnhe3djgE3MKKyYvxNUIbcTJoe7nhVMrwO/7lBSpVLvC4p3 wR700U0LDaGGQpslGtiE56SemgoP
On production deployments, you can regenerate this file by running the following command:
$ openssl rand -base64 741
-
Elasticsearch Heap Size. The default heap size for Elasticsearch is 1GB, which is too small for production. For production deployments for large datasets, uncomment the option and enter a value.
#elastic_heap_size: 4g # sets the heap size (1g|2g|3g) for the Elastic Servers
-
Java API Service. Optional. Set the Java API Service (JAS) properties for the deployment: authentication, maximum memory, directory for attribute mappings data source entities:
jas: auth_enabled: true auth_type: 'jwt' signiture_key_id: 'service1-hmac' signiture_algorithm: 'hmac-sha256' max_memory: 4096M mapping_entity_type: /common/mappings datasource_entity_type: /common/datasources
-
-
Open a text editor and enter the private IP addresses of the target machines in the
~/autoid-config/hostsfile. Make sure the target host IP addresses are accessible from the deployer machine. The following is an example of the~/autoid-config/hostsfile. NOTE:[notebook]is not used in Autonomous Identity.Click to See a Host File for a Multi-Node Cassandra Deployment
If you configured Cassandra as your database, the
~/autoid-config/hostsfile is as follows for multi-node target deployments:[docker-managers] 10.128.0.90 [docker-workers] 10.128.0.170 [docker:children] docker-managers docker-workers [cassandra-seeds] 10.128.0.175 10.128.0.34 [spark-master] 10.128.0.180 [spark-workers] 10.128.0.176 10.128.0.177 [spark:children] spark-master spark-workers [mongo_master] #ip# mongodb_master=True [mongo_replicas] #ip-1# ##ip-2# ##… [mongo:children] mongo_replicas mongo_master # ELastic Nodes [odfe-master-node] 10.128.0.178 [odfe-data-nodes] 10.128.0.184 [kibana-node] 10.128.0.184 [notebook] #ip#
-
Open a text editor and set the Autonomous Identity passwords for the configuration service, elasticsearch backend, and Cassandra or MongoDB database. The vault passwords file is located at
~/autoid-config/vault.yml.Despite the presence of special characters in the examples below, do not include special characters, such as &or$, in your productionvault.ymlpasswords as it will result in a failed deployer process.configuration_service_vault: basic_auth_password: ~@C~O>@%^()-_+=|<Y*$$rH&&/m#g{?-o!z/1}2??3=!*& cassandra_vault: cassandra_password: ~@C~O>@%^()-_+=|<Y*$$rH&&/m#g{?-o!z/1}2??3=!*& cassandra_admin_password: ~@C~O>@%^()-_+=|<Y*$$rH&&/m#g{?-o!z/1}2??3=!*& keystore_password: Acc#1234 truststore_password: Acc#1234 mongo_vault: mongo_admin_password: ~@C~O>@%^()-_+=|<Y*$$rH&&/m#g{?-o!z/1}2??3=!*& mongo_root_password: ~@C~O>@%^()-_+=|<Y*$$rH&&/m#g{?-o!z/1}2??3=!*& keystore_password: Acc#1234 truststore_password: Acc#1234 elastic_vault: elastic_admin_password: ~@C~O>@%^()-_+=|<Y*$$rH&&/m#g{?-o!z/1}2??3=!*& elasticsearch_password: ~@C~O>@%^()-_+=|<Y*$$rH&&/m#g{?-o!z/1}2??3=!*& keystore_password: Acc#1234 truststore_password: Acc#1234 -
Encrypt the vault file that stores the Autonomous Identity passwords, located at
~/autoid-config/vault.yml. The encrypted passwords will be saved to/config/.autoid_vault_password. The/config/mount is internal to the deployer container.$ ./deployer.sh encrypt-vault
-
Download the images. This step downloads software dependencies needed for the deployment and places them in the
autoid-packagesdirectory.$ ./deployer.sh download-images
-
Run the deployment.
$ ./deployer.sh run
Set the Replication Factor
Once Cassandra has been deployed, you need to set the replication factor to match the number of nodes on your system. This ensures that each record is stored in each of the nodes. In the event one node is lost, the remaining node can continue to serve content even if the cluster itself is running with reduced redundancy.
You can define replication on a per keyspace-basis as follows:
-
SSH to a Cassandra seed node.
-
Change to the
/opt/autoid/apache-cassandra-3.11.2/directory. -
Start the Cassandra sheel,
cqlsh, and define theautoidkeyspace. Change the replication factor to match the number of seed nodes. The default admin user for Cassandra iszoran_dba.$ bin/cqlsh -u zoran_dba $ zoran_dba@cqlsh> desc keyspace autoid; CREATE KEYSPACE autoid WITH replication = {'class':'SimpleStrategy','replication_factor':'2'} AND durable_writes=true; CREATE TABLE autoid.user_access_decisions_history( user text, entitlement text, date_created timestamp, … -
Restart Cassandra on this node.
-
Repeat these steps on the other Cassandra seed node(s).
Resolve Hostname
After installing Autonomous Identity, set up the hostname resolution for your deployment.
-
Configure your DNS servers to access Autonomous Identity dashboard on the target node. The following domain names must resolve to the IP address of the target node:
<target-environment>-ui.<domain-name>
-
If DNS cannot resolve target node hostname, edit it locally on the machine that you want to access Autonomous Identity using a browser.
Open a text editor and add an entry in the
/etc/hosts(Linux/Unix) file orC:\Windows\System32\drivers\etc\hosts(Windows) for the target node.For multi-node, use the Docker Manager node as your target.
<Docker Mgr Node Public IP Address> <target-environment>-ui.<domain-name>
For example:
<IP Address> autoid-ui.forgerock.com
-
If you set up a custom domain name and target environment, add the entries in
/etc/hosts. For example:<IP Address> myid-ui.abc.com
For more information on customizing your domain name, see Customize Domains.
Access the Dashboard
Access the Autonomous Identity console UI:
-
Open a browser. If you set up your own url, use it for your login.
-
Log in as a test user.
test user: bob.rodgers@forgerock.com password: <password>
Check Apache Cassandra
Check Cassandra:
-
On the target node, check the status of Apache Cassandra.
$ /opt/autoid/apache-cassandra-3.11.2/bin/nodetool status
-
An example output is as follows:
Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 34.70.190.144 1.33 MiB 256 100.0% a10a91a4-96e83dd-85a2-4f90d19224d9 rack1 --
|
If you see a "data set too large for maximum size" error message while checking the status or starting Apache Cassandra, then you must update the segment size and timeout settings. To update these settings:
|
Check MongoDB
Check the status of MongoDB:
-
On the target node, check the status of MongoDB.
$ mongo --tls \ --host <Host IP> \ --tlsCAFile /opt/autoid/mongo/certs/rootCA.pem \ --tlsAllowInvalidCertificates \ --tlsCertificateKeyFile /opt/autoid/mongo/certs/mongodb.pem
Check Apache Spark
Check Spark:
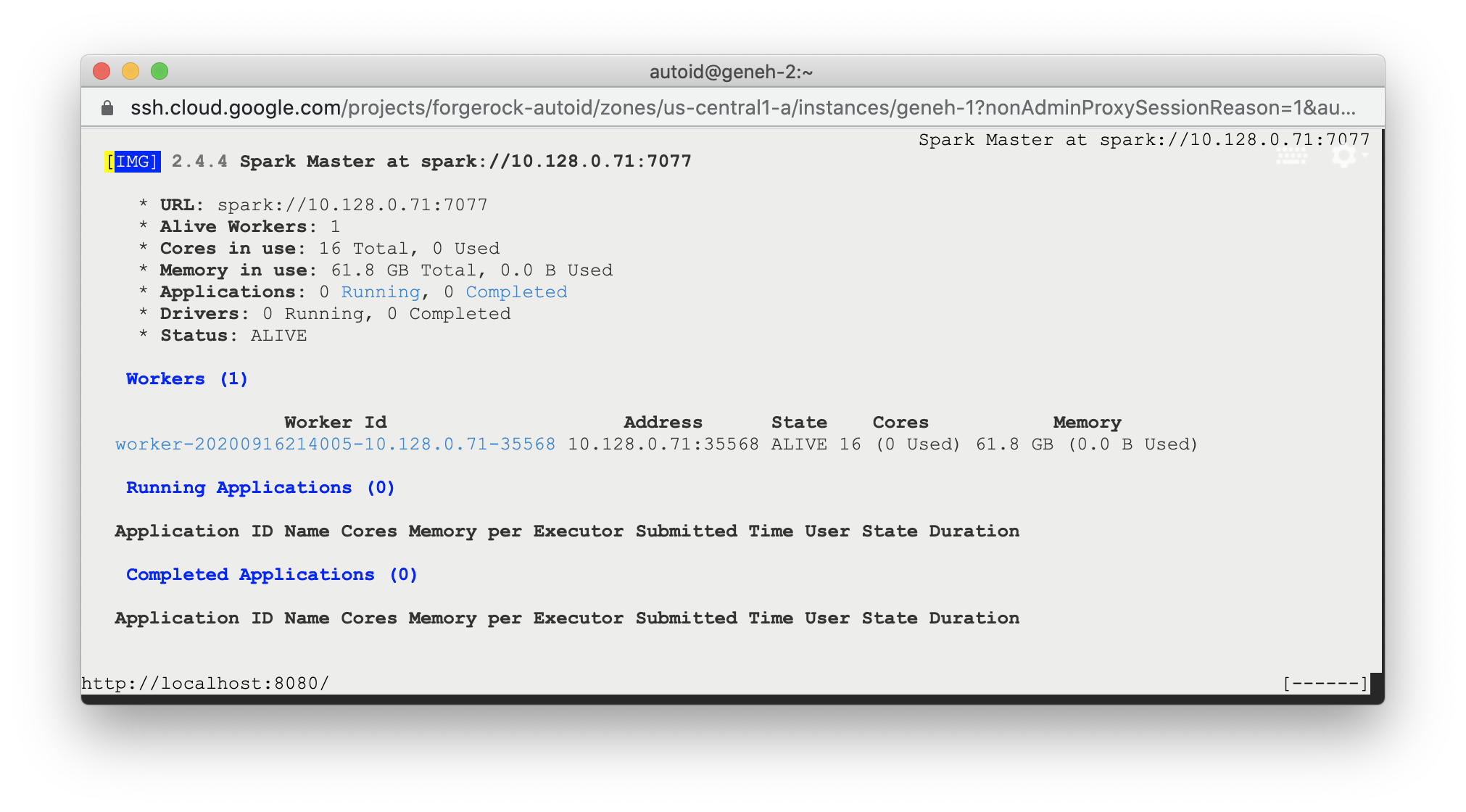
-
SSH to the target node and open Spark dashboard using the bundled text-mode web browser
$ elinks http://localhost:8080
You should see Spark Master status as ALIVE and worker(s) with State ALIVE.
Click to See an Example of the Spark Dashboard
Start the Analytics
If the previous installation steps all succeeded, you must now prepare your data’s entity definitions, data sources, and attribute mappings prior to running your analytics jobs. These step are required and are critical for a successful analytics process.
For more information, see Set Entity Definitions.