Set analytics thresholds
The Autonomous Identity UI now supports the configuration of the analytics threshold values to calculate confidence scores, predications, and recommendations.
| In general, there is little reason to change the default threshold values. If you do edit these values, be aware that incorrect threshold values can negatively affect your analytics results. |
There are six types of threshold settings that administrators can edit:
-
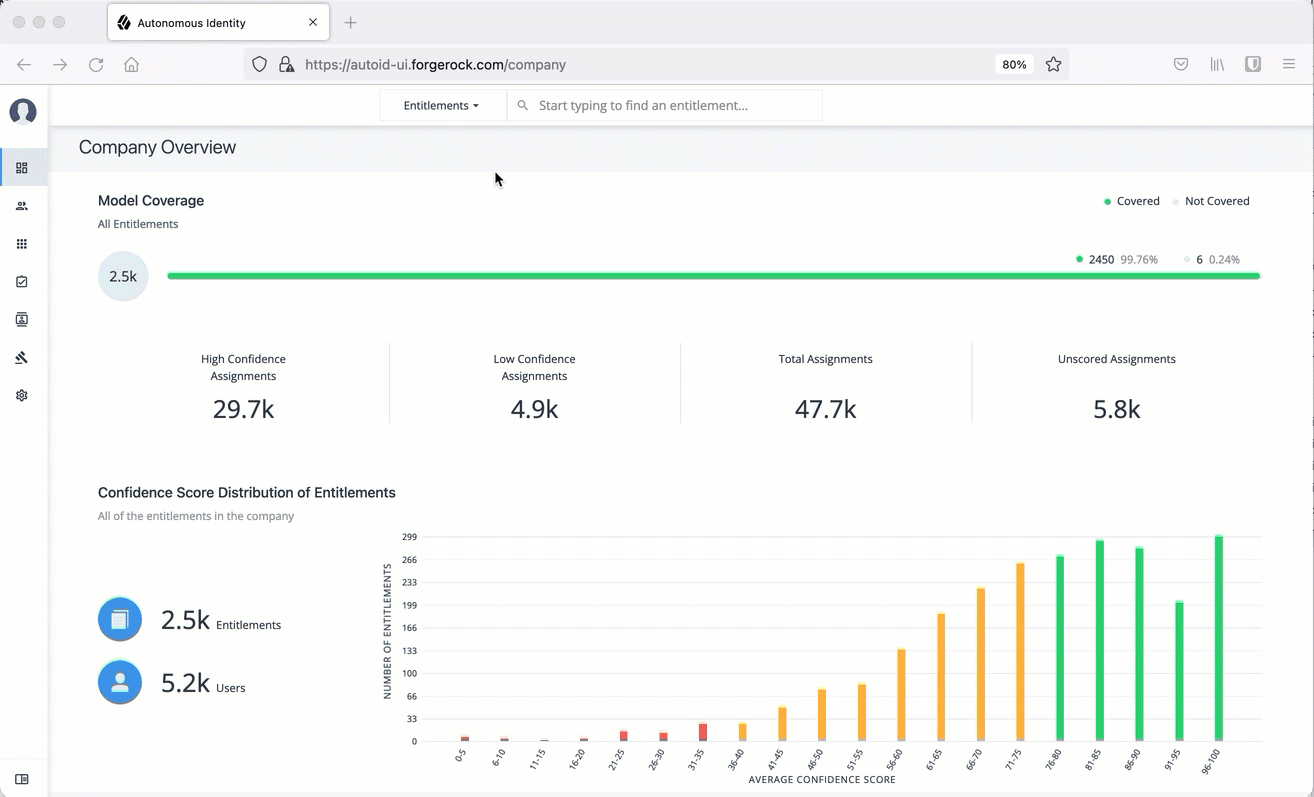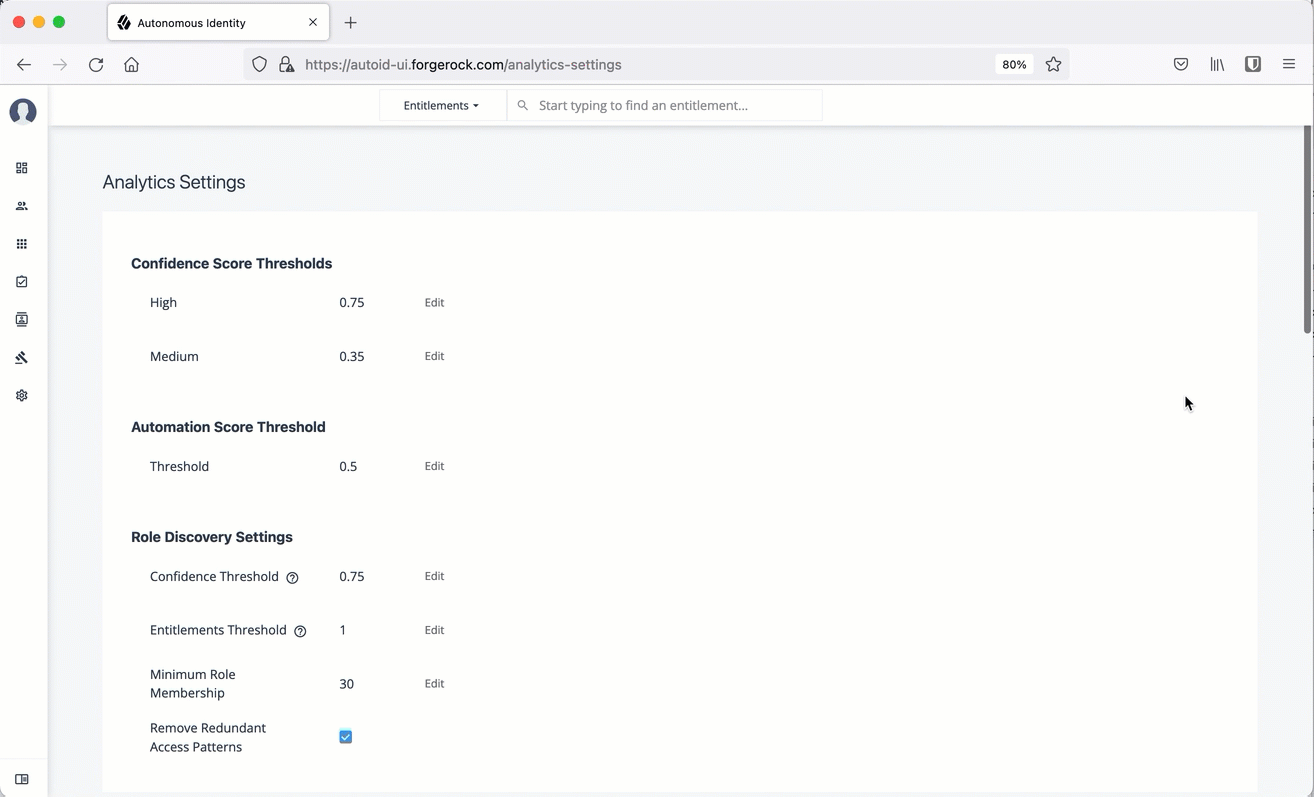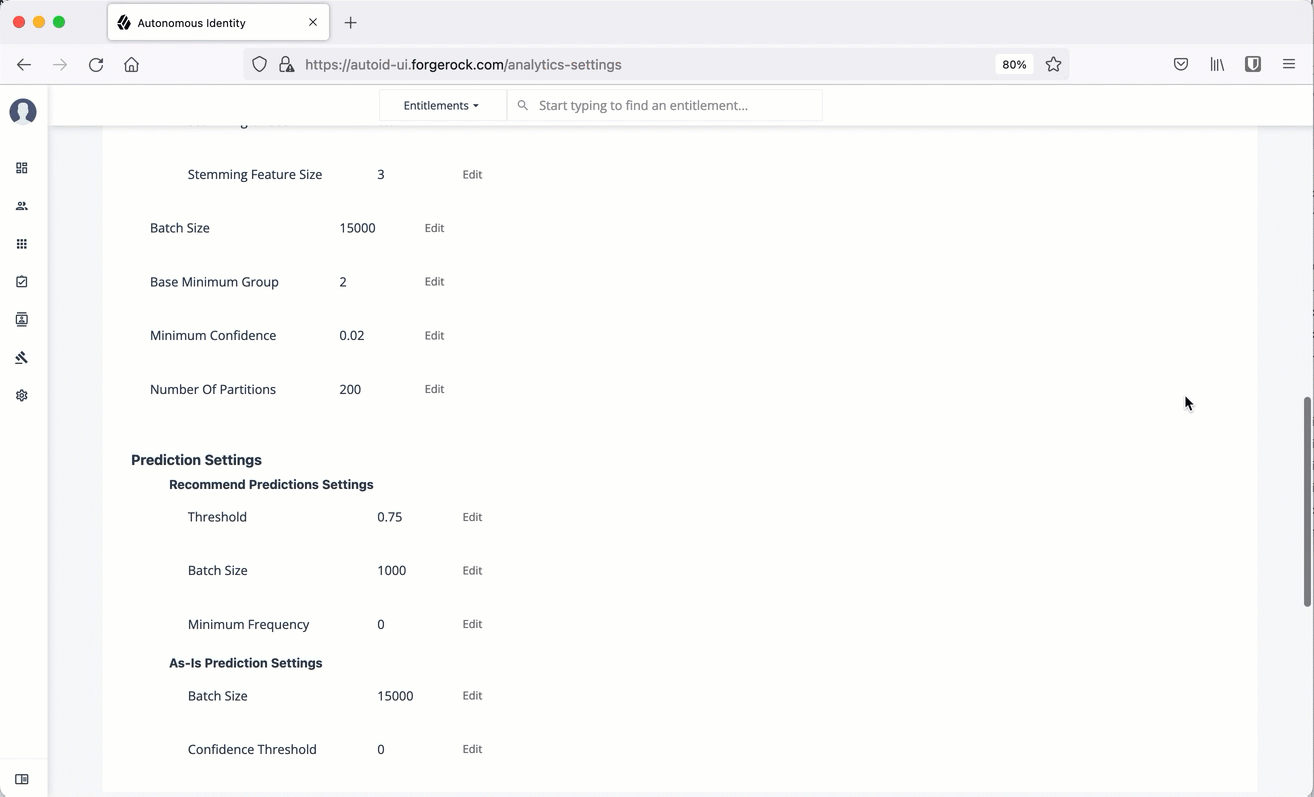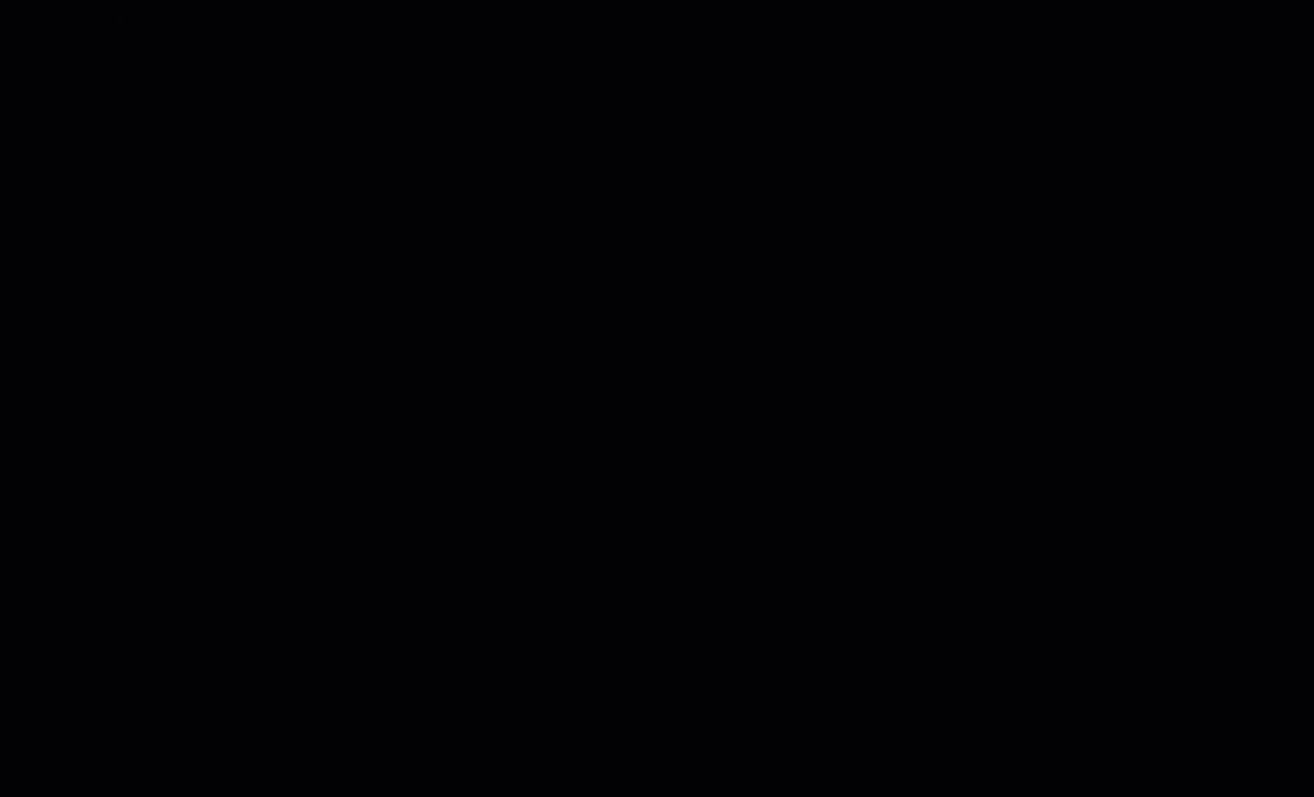
Confidence Score Thresholds. Confidence score thresholds lets you define High, Medium, and Low confidence score ranges. Autonomous Identity computes a confidence score for each access assignment based on its machine learning algorithm. The properties are:
Table 1: Confidence Score Thresholds Settings Default Description Confidence Score Thresholds
-
High: 0.75 or 75%
-
Medium: 0.35 or 35%
-
Confidence scores from 75 to 100 are set to High.
-
Confidence scores from 35 to 74 are set to Medium, and scores from 0 to 34 are set to Low.
-
-
Automation Score Threshold. Automation score threshold is a UI setting determining if an approval button and checkbox appears before a justification rule on the Entitlement Details and Rules pages.
Click to display an example image of where the approval button and checkbox are located
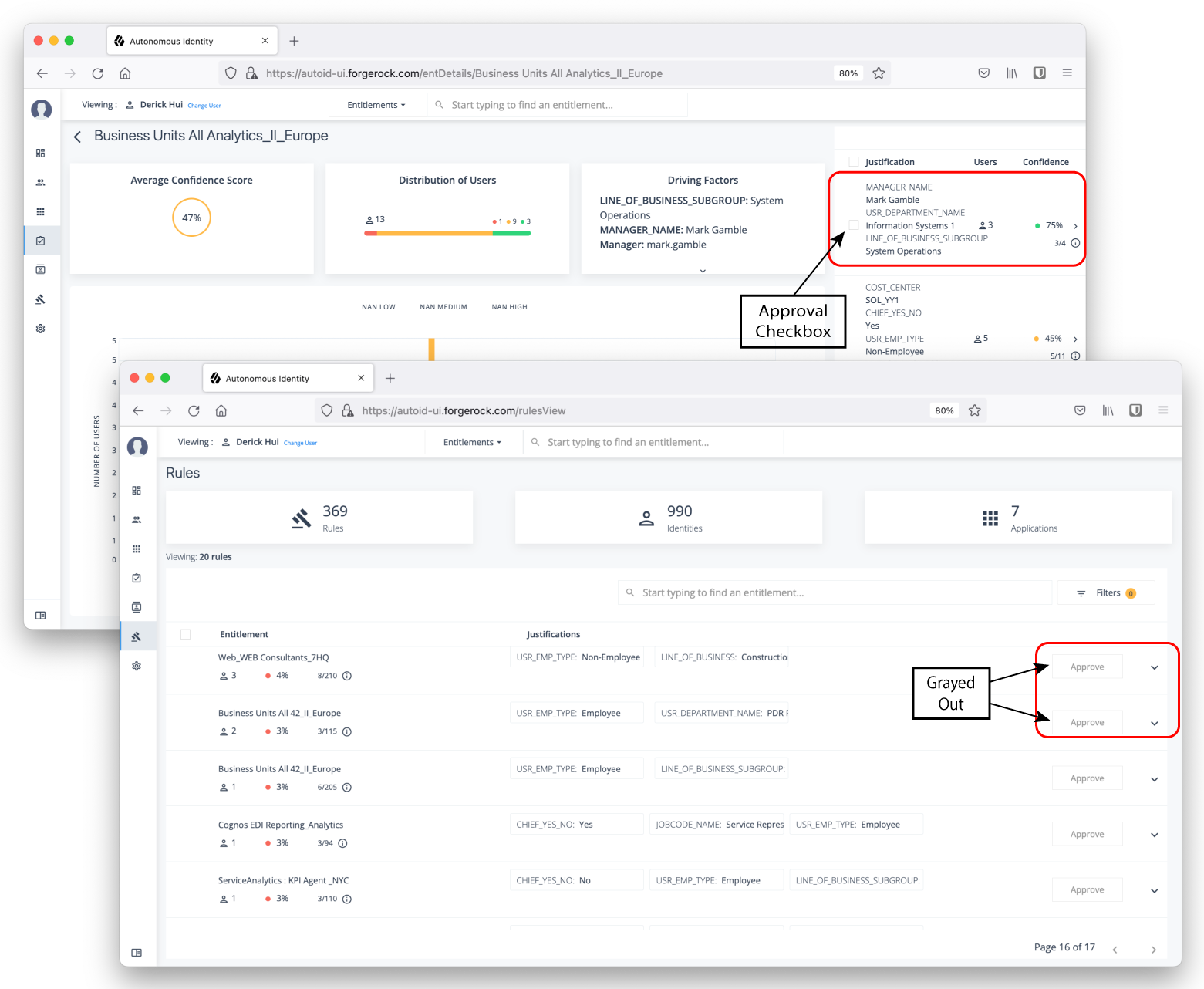
Table 2: Automation Score Threshold Settings Default Description Automation Score Threshold
0.5 or 50%
Specifies if any confidence score less than 50% will not give the user the option to approve the justification or rule.
-
Role Discovery Settings. Role discovery settings determine the key factors for roles for inclusion in the role mining process. Roles are a collection of entitlements and their associated justifications and access patterns. This collection is produced from the output training rules.
Table 3: Role Discovery Settings Default Description Confidence Threshold
0.75 or 75%
Specifies the minimum rule confidence required for inclusion in the role mining process.
Entitlements Threshold
1
Specifies the minimum number of entitlements a role may contain. The Autonomous Identity role mining process does not produce candidate roles below this threshold value. For example, if the threshold is 2, there are no roles that contain only one entitlement.
Minimum Role Membership
30
Specifies the granularity of the role through its membership. For example, the default is 30, which means that no role produced can have fewer than 30 members.
Remove Redundant Access Patterns
Enabled
Specifies a pruning process that removes redundant patterns when more general patterns can be retained.
For example, if a user is an Employee AND in the department, Finance, they receive the Excel access entitlement. However, there may be a more general rule that provisions Excel access by simply being an Employee.
-
[ ENT_Excel | DEPT_Finance, EMP_TYPE_Employee]
-
[ ENT_Excel | EMP_TYPE_Employee]
As a result, Autonomous Identity removes the first pattern and retains the latter more general rule.
-
-
Training Settings. Administrators can set the thresholds for the AI/ML training process, specifically the stemming process and general training properties.
Stemming: During the training process, Autonomous Identity generates rules by searching the data for if-then patterns that have a parent-child relationship in their composition. These if-then patterns are also known as antecedent-consequent relationships, which means rule-entitlement for Autonomous Identity.
Stemming is a process to remove any redundant final association rules output. For a rule to be stemmed, it must match the following criteria:
-
Rule B consequent must match Rule A consequent.
-
Rule B antecedent must be a superset of Rule A antecedent.
-
Rule B confidence score must be within a given range +/- (offset) of Rule A confidence score.
For example, the Payroll Report entitlement has two rules, each that involves the Finance department. All Dublin employees in the Finance department also get the entitlement. Stemming prunes the second rule (B) and retains the more general first rule (A).
ID Consequent (ENT) Antecedent (Rule) Confidence Score A
Payroll report
[Finance]
90%
B
Payroll report
[Dublin,Finance]
89%
Table 4: Training Settings Type Settings Default Description Stemming Predictions
Determines stemming, or pruning, properties.
Stemming Enabled
Enabled
Specifies if stemming occurs or not. Do not disable this feature.
Stemming Offset
0.02
Specifies the confidence range (plus or minus) of one rule to another rule.
Stemming Feature Size
3
Specifies the "up-to" maximum antecedent/justification size that may be the size priority of stemming. Because we want to retain the smallest rules possible, we start by prioritizing rules with an antecedent size of 1. We can then increase the antecedent size, iteratively, until we reach the Stemming Feature Size setting.
Batch Size
15000
Specifies the number of samples viewed is indicated by the batch size. An epoch is defined as the number of passes for a model to iterate through the entire dataset once and update its learning algorithm. To process the entire epoch, the model views a few samples at a time in batches.
Base Minimum Group
2
Specifies the minimum support value used in training. It is referred as Base, because it is used to find the minimum support value for the initial chunk of training.
Minimum Confidence
0.02
Specifies the lowest acceptable confidence score to be included in the entitlement-rule combination.
Number of Partitions
200
Specifies the number of partitions in a Spark configuration. A partition is a smaller chunk of a large dataset. Spark can run one concurrent task in a single partition. As a rule of thumb, the more partitions you have, the more work can be distributed among Spark worker nodes. In this case, small chunks of data are processed by each worker. In the case of fewer partitions, Autonomous Identity can process larger chunks of data.
-
-
Predictions Settings. Administrators can set the thresholds for the recommendation and as-is prediction processes.
Table 5: Predictions Settings Type Settings Default Description Recommendation Settings
Properties for setting the recommendation predictions settings.
Threshold
0.75
Specifies the confidence score threshold to be considered for recommendation.
Batch Size
1000
Specifies the number of rules and user entitlements processed at one time.
Minimum Frequency
0
Specifies the minimum frequency for a rule to appear for consideration as a recommendation. During the first training stage, Autonomous Identity models the frequent itemsets that appear in the HR attributes-only of each user. Only rules that appear a minimum of N times are considered. The value of N is the Minimum Frequency.
As-Is Prediction Settings
Properties for setting the as-is predictions settings.
Batch Size
15000
Specifies the number of rules and user entitlements processed at one time.
Confidence Threshold
0
Specifies the confidence score threshold to be considered for an as-is prediction.
Minimum Rule Length
1
Specifies the minimum justification size for rules to be considered in predictions. You only would increase this property if you don’t want a single rule overriding more specific or granular rules when determining access. For example, if the minimum rule length is 2, Autonomous Identity only uses the rule DEPT_Finance, JOB_TITLE_Account_II. However, if the default is kept at 1, the second and shorter rule can include a broader number of entitlement assignments.
-
[ ENT_AccountingSoftware | DEPT_Finance, JOB_TITLE_Account_II]
-
[ ENT_AccountingSoftware | EMP_TYPE_Employee]
Maximum Rule Length
10
Specifies the maximum justification size for rules to be considered in predictions. This property is a guardrail to keep rules that contain extremely large or complex justifications out of the prediction set.
Prediction Confidence Window
0.05
Specifies the range of acceptable values for a prediction confidence score. Rules with confidence scores outside the prediction confidence window range are filtered out. A confidence window is determined from the values set in the configuration file: max=maxConf, min=maxConf - pred_conf_window.
-
-
Analytics Spark Job Config. Administrators can adjust the Apache Spark job configuration if needed.
Table 6: Analytics Spark Job Configuration Settings Default Description Driver Memory
2G
Specifies the amount of memory for the driver process.
Driver Cores
3
Specifies the number of cores to use for the driver process in cluster mode.
Executor Memory
3G
Specifies the amount of memory to use per executor process.
Executor Cores
6
Specifies the number of executor cores per worker node.
Configure Analytic Settings
-
Log in to the Autonomous Identity UI as an administrator.
-
On the Autonomous Identity UI, click Administration.
-
Click Analytics Settings.
-
Under Confidence Score Thresholds, click Edit next to the High threshold value, and then enter a new value. Click Save. Repeat for the Medium threshold value.
-
Under Automation Score Threshold, click Edit next to a threshold value, and then enter a new value.
-
Under Role Discovery Setting, click Edit next to a threshold value, and then enter a new value.
-
Under Training Settings, click Edit next to a threshold value, and then enter a new value.
-
Under Prediction Settings, click Edit next to a threshold value, and then enter a new value.
-
Under Analytics Spark Job Config, click Edit next to a threshold value, and then enter a new value.
-
Click Save.
Click an example
-
Next, you can run the analytics. Refer Run Analytics.