How Autonomous Identity Works
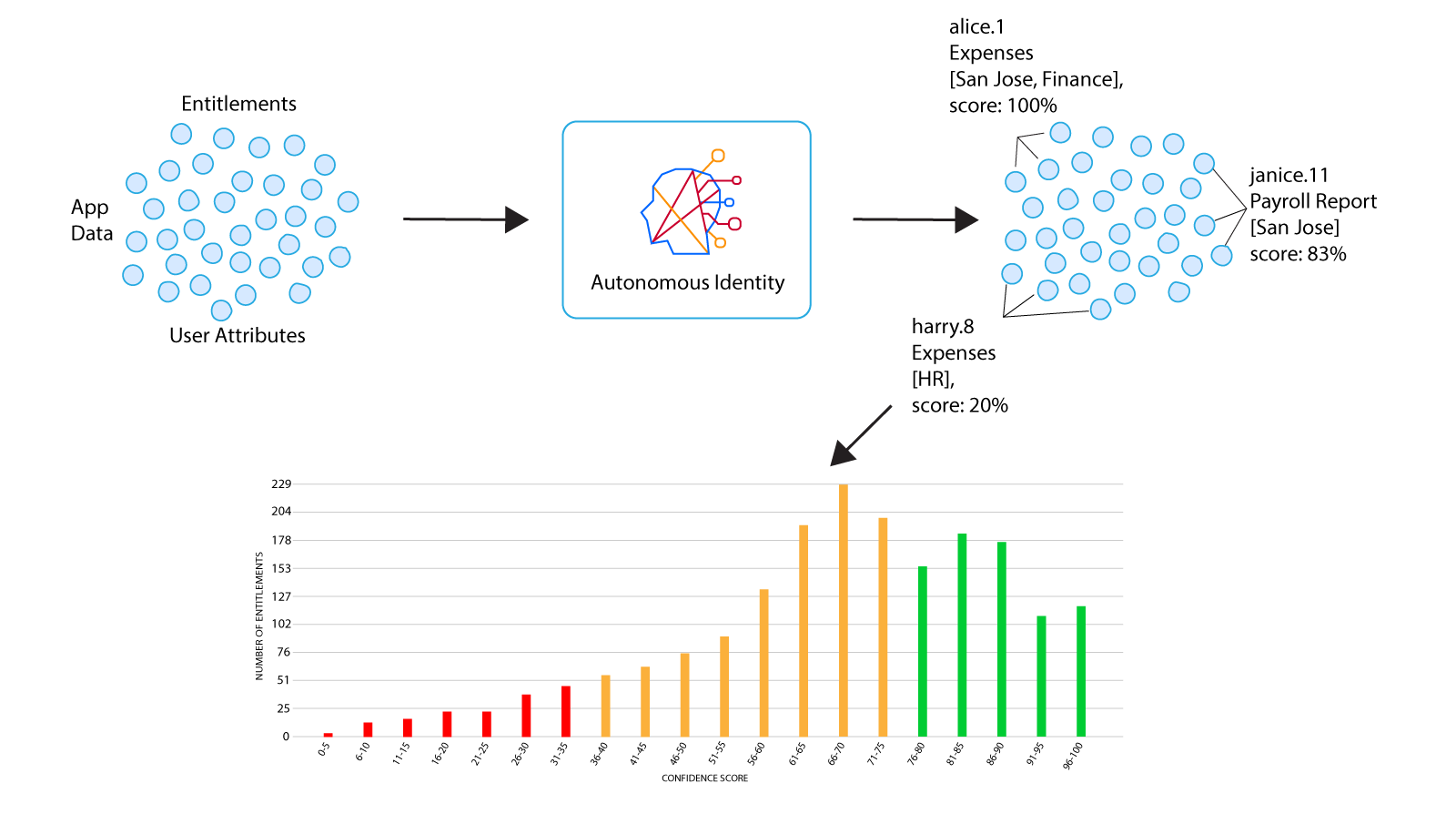
Autonomous Identity is an AI-based analytics engine that discovers, analyzes, and generates a complete profile of your company’s entitlements.
Autonomous Identity looks at each entitlement and its relationship to the assigned user within the company. These relationships are modelled and assigned a single confidence score (from 0 to 100%) indicating the strength of correlation between the model and the assigned entitlement. The results are displayed on the UI console.
| For a definition of Autonomous Identity terms, see the Glossary. |
Figure 2: A simple conceptual diagram of Autonomous Identity
Let’s Run a Simple Example
Let’s run a simple example to see how Autonomous Identity models the entitlements and calculates confidence scores. Each company can decide the level and scope of the analysis. However, in most cases, the more data you analyze, the better the entitlement models.
Before you can ingest and process the data. You must run three pre-analytics tasks to prepare your data and machine learning runs.
Set Entity Definitions
The process begins by adding any new entity definitions to the schema. Autonomous Identity provides a UI interface that lets you add any new entity definitions or attributes to the schema.
Set Data Sources and Mappings
The next step is to define your data source files using the UI. Data can come from application services, HR databases, and other sources and must be in comma-separated values (.csv) formatted files.
You must also define mappings that map your data attributes to those in the schema. This is a critical step to ensure key data elements are properly included in your Autonomous Identity deployment.
Set Machine Learning Thresholds
The next step is to adjust any machine learning thresholds from the default values. In general, most deployments use the default values. You should only edit the values if you fully understand the machine learning process.
Data Ingestion
After you have set your entity definitions, defined your data sources and mappings, and set your thresholds, you can ingest the data into the system. There are four basic types of data required: applications, assignments, entitlements, and identities. Examples are provided below. Note that actual production data will have additional columns of information.
-
Applications. Applications data include those attributes that define your applications.
The following table shows a simple example of application data:
Table 1: Applications APP_ID APP_NAME APP_OWNER_ID adp-1
ADP
irene.9
expensify-1
Expensify
janice.10
-
Assignments. The second type of data is an assignments file that maps each user to their assigned entitlement. The data can come from your IAM/IGA system. If a user has multiple entitlements, each row represents a single assigned mapping to each entitlement.
The following table shows a simple example of assignments data:
Table 2: Assignments ENT_ID USR_ID HIGH_RISK Payroll Report
alice.1
High
Expenses
alice.1
High
Payroll Report
bob.2
High
Expenses
bob.2
High
Payroll Report
chris.3
High
Expenses
chris.3
High
Payroll Report
diane.4
High
Payroll Report
ellen.5
High
Payroll Report
fred.6
High
Expenses
gary.7
High
Payroll Report
harry.8
High
Expenses
irene.9
High
Payroll Report
janice.10
High
Expenses
karen.11
High
-
Entitlements. In another file, you have entitlement data. The file may include data, such as full entitlement name, application name, entitlement or role owner, or any other information that helps with the machine learning.
The following table shows a simple example of entitlement data:
Table 3: Entitlements ENT_ID ENT_OWNER APP_ID Payroll Report
alice.1
adp-1
Expenses
bob.2
expensify-1
-
Identities. The fourth type of data file is identities, which stores user profile information from your HR data including attributes that contain a minimally required set of information required for analytics processing.
The following table shows a simple example of identities data:
Table 4: Identities USR_ID DEPARTMENT CITY alice.1
San Jose
Finance
bob.2
Finance
San Jose
chris.3
Finance
San Jose
daine.4
HR
San Jose
ellen.5
HR
Austin
fred.6
HR
Austin
gary.7
HR
Austin
harry.8
HR
Austin
irene.9
IT
Dublin
janice.10
Finance
Dublin
karen.11
Finance
San Jose
Training
Next, Autonomous Identity runs a two-stage machine-learing process to generate the association rules and confidence scores. An association rule is an IF-THEN rule that expresses patterns between random data variables in a large transaction set. For example, [San Jose, Finance] → [Payroll Report] indicates that if a company’s finance office is located in San Jose and a person works in that office and department, it is likely that they get access to the Payroll Report.
During stage one of the training, Autonomous Identity analyzes the user attribute data using machine learning algorithms to pattern-mine and create itemsets of rules. The frequency of occurrence is counted for each itemset. Only rules that appear three times or more are considered. Itemsets less than three are ignored.
|
In a typical deployment, Autonomous Identity can create a million or more association rules for a company’s dataset. |
The following table shows the results of the initial training process:
| Itemset | Freq |
|---|---|
[San Jose] |
6 |
[Finance] |
5 |
[HR]=] |
5 |
[San Jose, Finance] |
4 |
[Austin] |
3 |
[Austin, HR] |
3 |
During this training run, the analytics engine creates a unique row in a table for each user and their assigned entitlements. In the example below, alice.1, bob.2, and chris.3 have multiple rows, one for each assigned entitlement. Again, only frequency sets (freqUnion) of three or more are considered.
The following table shows the results of the second training process:
| USER ID | CITY | DEPT | ENT |
|---|---|---|---|
alice.1 |
San Jose |
Finance |
Payroll Report |
alice.1 |
San Jose |
Finance |
Expenses |
bob.2 |
San Jose |
Finance |
Payroll Report |
bob.2 |
San Jose |
Finance |
Expenses |
chris.3 |
San Jose |
Finance |
Payroll Report |
chris.3 |
San Jose |
Finance |
Expenses |
diane.4 |
San Jose |
HR |
Payroll Report |
ellen.5 |
San Jose |
HR |
Payroll Report |
fred.6 |
Austin |
HR |
Payroll Report |
gary.7 |
Austin |
HR |
Expenses |
harry.8 |
Austin |
HR |
Payroll Report |
irene.9 |
Dublin |
IT |
Expenses |
janice.10 |
Dublin |
Finance |
Payroll Report |
karen.11 |
San Jose |
Finance |
Expenses |
Autonomous Identity applies the association rules to the entitlement mappings and calculates the risk confidence scores by dividing the freqUnion by frequency numbers (FreqUnion/Freq). The FREQ column show the number of occurrences of a rule from Table 5, for example, the rule [San Jose] appears 9 times. The FreqUnion is the union of a rule with an entitlement, for example, the union of the rule [San Jose] with the entitlement, Expenses, appears 4 times in Table 5. The confidence score indicates the scale from 0 to 100% to indicate the strength of each correlation. A confidence score of 100% indicates that the assigned entitlement is highly correlated to the user’s job function. Only rules that appear three times or more are considered.
The following table shows the applied association rules:
| RULE | ENT | FREQ | FreqUnion | Confidence |
|---|---|---|---|---|
[San Jose] |
Payroll Report |
9 |
5 |
56% |
[San Jose] |
Expenses |
9 |
4 |
44% |
[Finance] |
Payroll Report |
8 |
4 |
50% |
[Finance] |
Expenses |
8 |
4 |
50% |
[HR] |
Payroll Report |
5 |
4 |
80% |
[San Jose,Finance] |
Payroll Report |
7 |
3 |
43% |
[San Jose,Finance] |
Expenses |
7 |
4 |
57% |
Next, Autonomous Identity must re-adjust the frequency numbers from the previous table as the occurrences of a rule are inflated due to multiple appearances of a user’s entitlements (that is, one entitlement per row) as seen in Table 5. The re-adjustment provides a more accurate confidence score for each association rule.
The following are the results of the readjusted confidence scores:
| RULE | ENT | FREQ (Corrected) | FreqUnion | Confidence |
|---|---|---|---|---|
[San Jose] |
Payroll Report |
6 |
5 |
83% |
[San Jose] |
Expenses |
6 |
4 |
67% |
[Finance] |
Payroll Report |
5 |
4 |
80% |
[Finance] |
Expenses |
5 |
4 |
80% |
[HR] |
Payroll Report |
5 |
4 |
80% |
[San Jose,Finance] |
Payroll Report |
4 |
3 |
75% |
[San Jose,Finance] |
Expenses |
4 |
4 |
100% |
As-is Predictions
After the training process has determined the association rules for each entitlement, the analytics engine runs through an as-is predictions process, where user accesses are mapped to each entitlement using the association rules.
In the example, the user alice.1 has the following mapped entitlements, which are called justifications for their entitlement accesses.
The following table shows the results of the as-is-predictions process:
| USER ID | ENT | RULE | Confidence | FreqUnion |
|---|---|---|---|---|
alice.1 |
Payroll Report |
83% |
5 |
|
alice.1 |
Payroll Report |
80% |
4 |
|
alice.1 |
Payroll Report |
75% |
3 |
|
alice.1 |
Expenses |
67% |
4 |
|
alice.1 |
Expenses |
80% |
4 |
|
alice.1 |
Expenses |
100% |
4 |
The as-is predictions filter the justifications from the previous step using confidence score properties that are set in the configuration file. The maximum confidence score is set by the maxConf property. The minimum confidence score is set by the maxConf minus the pred_conf_window property, which is set to 5% in the configuration file by default. Thus, for this example, the maximum confidence and minimum confidence score filters for each entitlement is as follows:
The following table shows the result of the as-is-predictions:
| ENT | maxConf | Min |
|---|---|---|
Payroll Report |
83% |
78% |
Expenses |
100% |
95% |
Applying the filters in Table 9 to the mapped entitlements in Table 8, we get the following filtered assigned entitlements while discarding the rest. These filters are applied to all users in your analysis.
The following table shows the results for alice.1:
| USER ID | ENT | RULE | Confidence | FreqUnion |
|---|---|---|---|---|
alice.1 |
Payroll Report |
83% |
5 |
|
alice.1 |
Payroll Report |
80% |
4 |
|
alice.1 |
Expenses |
100% |
4 |
Finally, the highest freqUnion is used to find the users with a specific rule and entitlement access. All rules with the lower freqUnion values are filtered out to favor rules that apply to the largest number of employees within a company. This ensures that the most generalized rules are used for the analysis.
The following table shows the final as-is predictions for a user:
| USER ID | ENT | RULE | Confidence | FreqUnion |
|---|---|---|---|---|
alice.1 |
Payroll Report |
83% |
5 |
|
alice.1 |
Expenses |
100% |
4 |
Recommendations
The analytics process goes through a recommendations predictions process that takes the entitlement rules and identifies any users who should have access to the entitlement but do not. The analytics engine looks at each user’s confidence score associated with the entitlement and if the confidence score exceeds a pre-configured hreshold value, the recommendation are made for the user.
The process begins by assigning the entitlements to all users and removing already existing accesses. Autonomous Identity assigns the rules and confidence scores for these new assignments.
The following table shows the recommendations assigned to users who do not have a particular entitlement:
| USER ID | ENT | RULE | Confidence |
|---|---|---|---|
diane.4 |
Expenses |
67% |
|
ellen.5 |
Expenses |
67% |
|
fred.6 |
Expenses |
67% |
|
gary.7 |
Payroll Report |
80% |
|
harry.8 |
Expenses |
20% |
|
irene.9 |
Payroll Report |
no rule found |
0% |
janice.10 |
Expenses |
80% |
|
janice.11 |
Payroll Report |
83% |
The analytics engine determines the rules and confidence scores that meet a threshold property, conf_thresh, which is set to 80% in the configuration file by default.
The following example shows the final recommendations:
| USER ID | ENT | RULE | Confidence |
|---|---|---|---|
gary.7 |
Payroll Report |
80% |
|
janice.10 |
Expenses |
80% |
|
janice.11 |
Payroll Report |
83% |
The results will be uploaded to the Cassandra database as a recommended new entitlement and appears on the UI console on the Recommendations screen.
Output to the UI Console
The final step of the process is for Autonomous Identity to display the confidence scores graphically on the UI as a distribution from low, medium, to high scores. The console lets you immediately identify the low confidence scores that could pose a potential security risk as well as the high confidence scores that can be automatically approved or certified. Autonomous Identity displays the attributes that justified each confidence score as well as other data to help you manage your entitlements.
You can run the analytics weekly or monthly to ensure near realtime assessment of your entitlements. This ensures that some entitlements can immediately be flagged if it goes stale and is no longer necessary.