Mappings with a JDBC repository
Generic, explicit, and hybrid, oh my!
Reasons for choosing generic or hybrid over explicit mappings include:
-
Generic and hybrid mapped objects offer the flexibility to add and subtract non-searchable properties without having to modify the Database Data Definition Language (DDL) or IDM object configuration.
-
The properties table for generic objects can grow large quickly.
Consider that a single object with 10 searchable properties would populate 10 rows within the generic properties table. Performance can be increased if commonly searched properties are mapped to a single column in the object table. In addition, the datatype of the property value can be enforced by the DDL of the column, or perhaps a required field could be marked as
NOT NULL. However, once a property is mapped to an explicit column, future changes to the property mapping may require a DDL change and possibly, a migration effort.
| PostgreSQL offers JSON capabilities that automatically makes all properties searchable. Although indexes will likely still need to be created for properties that need a performance boost. |
Generic mappings (JDBC)
Generic mapping speeds up development, and can make system maintenance more flexible by providing a stable database structure. However, generic mapping can have a performance impact and does not take full advantage of the database facilities (such as validation within the database and flexible indexing). In addition, queries can be more difficult to set up.
In a generic table, the entire object content is stored in a single large-character field named fullobject in the mainTable for the object. To search on specific fields, you can read them by referring to them in the corresponding properties table for that object. The disadvantage of generic objects is that, because every property you might like to filter by is stored in a separate table, you must join to that table each time you need to filter by anything.
The following diagram shows a pared down database structure for the default generic tables, when using a MySQL repository. The diagram indicates the relationship between the main table and the corresponding properties table for each object.
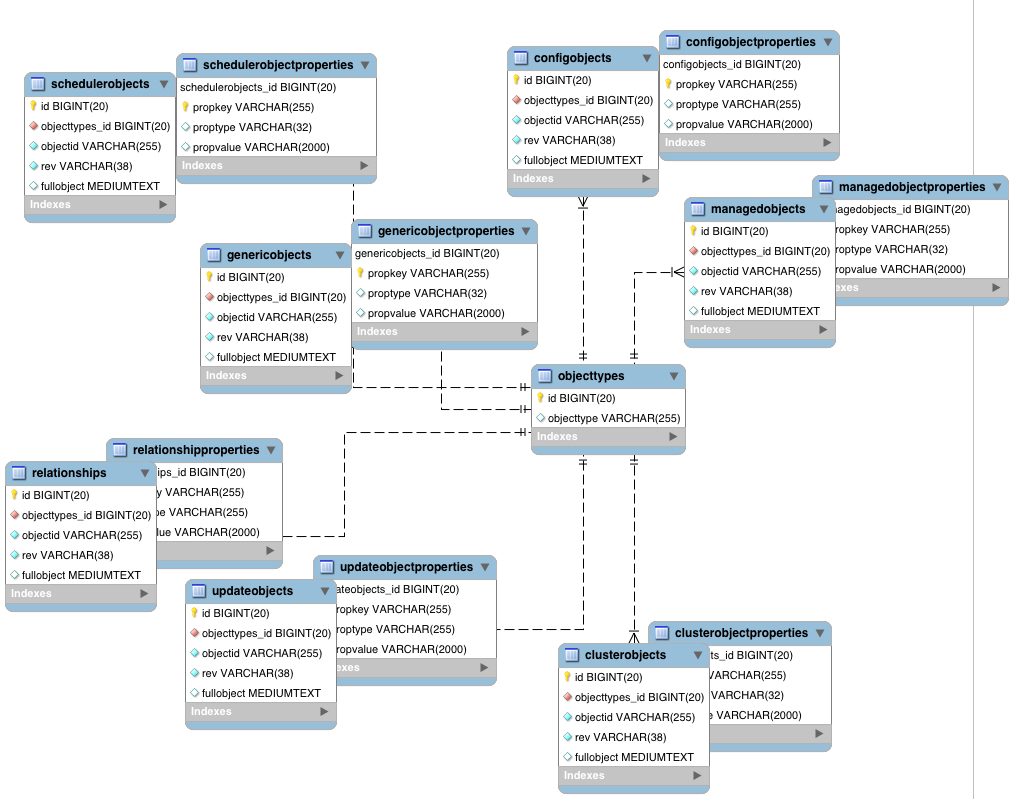
These separate tables can make the query syntax particularly complex. For example, a simple query to return user entries based on a user name would need to be implemented as follows:
SELECT obj.objectid, obj.rev, obj.fullobject FROM ${_dbSchema}.${_mainTable} obj
INNER JOIN ${_dbSchema}.${_propTable} prop ON obj.id = prop.${_mainTable}_id
INNER JOIN ${_dbSchema}.objecttypes objtype ON objtype.id = obj.objecttypes_id
WHERE prop.propkey='/userName' AND prop.propvalue = ${uid} AND objtype.objecttype = ${_resource}The query can be broken down as follows:
-
Select the full object, the object ID, and the object revision from the main table:
SELECT obj.objectid, obj.rev, obj.fullobject FROM ${_dbSchema}.${_mainTable} obj -
Join to the properties table and locate the object with the corresponding ID:
INNER JOIN ${_dbSchema}.${_propTable} prop ON obj.id = prop.${_mainTable}_id -
Join to the object types table to restrict returned entries to objects of a specific type. For example, you might want to restrict returned entries to
managed/userobjects, ormanaged/roleobjects:INNER JOIN ${_dbSchema}.objecttypes objtype ON objtype.id = obj.objecttypes_id -
Filter records by the
userNameproperty, where the userName is equal to the specifieduidand the object type is the specified type (in this case, managed/user objects):WHERE prop.propkey='/userName' AND prop.propvalue = ${uid} AND objtype.objecttype = ${_resource}The value of the
uidfield is provided as part of the query call, for example:openidm.query("managed/user", { "_queryId": "for-userName", "uid": "jdoe" });
Tables for user definable objects use a generic mapping by default.
The following sample generic mapping object illustrates how managed/ objects are stored in a generic table:
"genericMapping" : {
"managed/*" : {
"mainTable" : "managedobjects",
"propertiesTable" : "managedobjectproperties",
"searchableDefault" : true,
"properties" : {
"/picture" : {
"searchable" : false
}
}
}
}mainTable(string, mandatory)-
Indicates the main table in which data is stored for this resource.
The complete object is stored in the
fullobjectcolumn of this table. The table includes anobjecttypesforeign key that is used to distinguish the different objects stored within the table. In addition, the revision of each stored object is tracked, in therevcolumn of the table, enabling multiversion concurrency control (MVCC). For more information, see Manipulating Managed Objects Programmatically. propertiesTable(string, mandatory)-
Indicates the properties table, used for searches.
PostgreSQL repositories do not use these properties tables to access specific properties. Instead, the PostgreSQL json_extract_path_text()function achieves this functionality.The contents of the properties table is a defined subset of the properties, copied from the character large object (CLOB) that is stored in the
fullobjectcolumn of the main table. The properties are stored in a one-to-many style separate table. The set of properties stored here is determined by the properties that are defined assearchable.The stored set of searchable properties makes these values available as discrete rows that can be accessed with SQL queries, specifically, with
WHEREclauses. It is not otherwise possible to query specific properties of the full object.The properties table includes the following columns:
-
${_mainTable}_idcorresponds to theidof the full object in the main table, for example,manageobjects_id, orgenericobjects_id. -
propkeyis the name of the searchable property, stored in JSON pointer format (for example/mail). -
proptypeis the data type of the property, for examplejava.lang.String. The property type is obtained from the Class associated with the value. -
propvalueis the value of property, extracted from the full object that is stored in the main table.Regardless of the property data type, this value is stored as a string, so queries against it should treat it as such.
-
searchableDefault(boolean, optional)-
Specifies whether all properties of the resource should be searchable by default. Properties that are searchable are stored and indexed. You can override the default for individual properties in the
propertieselement of the mapping. The preceding example indicates that all properties are searchable, with the exception of thepictureproperty.For large, complex objects, having all properties searchable implies a substantial performance impact. In such a case, a separate insert statement is made in the properties table for each element in the object, every time the object is updated. Also, because these are indexed fields, the recreation of these properties incurs a cost in the maintenance of the index. You should therefore enable
searchableonly for those properties that must be used as part of a WHERE clause in a query.PostgreSQL repositories do not use the searchableDefaultproperty. properties-
Lists any individual properties for which the searchable default should be overridden.
Note that if an object was originally created with a subset of
searchableproperties, changing this subset (by adding a newsearchableproperty in the configuration, for example) will not cause the existing values to be updated in the properties table for that object. To add the new property to the properties table for that object, you must update or recreate the object.
Improve generic mapping search performance (JDBC)
All properties in a generic mapping are searchable by default. In other words, the value of the searchableDefault property is true unless you explicitly set it to false. Although there are no individual indexes in a generic mapping, you can improve search performance by setting only those properties that you need to search as searchable. Properties that are searchable are created within the corresponding properties table. The properties table exists only for searches or look-ups, and has a composite index, based on the resource, then the property name.
The sample JDBC repository configuration files (db/database/conf/repo.jdbc.json) restrict searches to specific properties by setting the searchableDefault to false for managed/user mappings. You must explicitly set searchable to true for each property that should be searched. The following sample extract from repo.jdbc.json indicates searches restricted to the userName property:
"genericMapping" : {
"{managed_user}" : {
"mainTable" : "manageduserobjects",
"propertiesTable" : "manageduserobjectproperties",
"searchableDefault" : false,
"properties" : {
"/userName" : {
"searchable" : true
}
}
}
}With this configuration, IDM creates entries in the properties table only for userName properties of managed user objects.
If the global searchableDefault is set to false, properties that do not have a searchable attribute explicitly set to true are not written in the properties table.
Explicit mappings (JDBC)
Explicit mapping is more difficult to set up and maintain, but can take complete advantage of the native database facilities.
An explicit table offers better performance and simpler queries. There is less work in the reading and writing of data, because the data is all in a single row of a single table. In addition, it is easier to create different types of indexes that apply to only specific fields in an explicit table. The disadvantage of explicit tables is the additional work required in creating the table in the schema. Also, because rows in a table are inherently more simple, it is more difficult to deal with complex objects. Any non-simple key:value pair in an object associated with an explicit table is converted to a JSON string and stored in the cell in that format. This makes the value difficult to use, from the perspective of a query attempting to search within it.
You can have a generic mapping configuration for most managed objects, and an explicit mapping that overrides the default generic mapping in certain cases.
IDM provides a sample configuration, for each JDBC repository, that sets up an explicit mapping for the managed user object, and a generic mapping for all other managed objects. This configuration is defined in the files named /path/to/openidm/db/repository/conf/repo.jdbc-repository-explicit-managed-user.json. To use this configuration, copy the file that corresponds to your repository to your project’s conf/ directory, and rename it repo.jdbc.json. Run the sample-explicit-managed-user.sql data definition script (in the path/to/openidm/db/repository/scripts directory) to set up the corresponding tables when you configure your JDBC repository.
IDM uses explicit mapping for internal system tables, such as the tables used for auditing.
Depending on the types of usage your system is supporting, you might find that an explicit mapping performs better than a generic mapping. Operations such as sorting and searching (such as those performed in the default UI) tend to be faster with explicitly-mapped objects, for example.
The following sample explicit mapping object illustrates how internal/user objects are stored in an explicit table:
"explicitMapping" : {
"internal/user" : {
"table" : "internaluser",
"objectToColumn" : {
"_id" : "objectid",
"_rev" : { "column" : "rev", "isNotNull" : true },
"password" : "pwd"
}
},
...
}resource-uri(string, mandatory)-
Indicates the URI for the resources to which this mapping applies; for example,
internal/user. table(string, mandatory)-
The name of the database table in which the object (in this case internal users) is stored.
objectToColumn(string, mandatory)-
The way in which specific managed object properties are mapped to columns in the table.
The mapping can be a simple one to one mapping, for example
"userName": "userName", or a more complex JSON map or list. When a column is mapped to a JSON map or list, the syntax is as shown in the following examples:"messageDetail" : { "column" : "messagedetail", "type" : "JSON_MAP" }"roles" : { "column" : "roles", "type" : "JSON_LIST" }Available column data types you can specify are
STRING(the default),NUMBER,JSON_MAP,JSON_LIST, andFULLOBJECT.You can also prevent a column from accepting a
NULLvalue, by setting the propertyisNotNulltotrue. This property is optional; if the property is omitted, it will default tofalse. Specifying which columns do not allow a null value can improve performance when sorting and paginating large queries. The syntax is similar to when specifying a column type:"createDate" : { "column" : "createDate", "isNotNull" : true }
|
Pay particular attention to the following caveats when you map properties to explicit columns in your database:
|
Hybrid mappings (JDBC)
Hybrid mappings are similar to generic mappings, except some object fields are mapped directly to a column, and therefore not stored in the Entity–attribute–value (EAV) properties table. The fullobject column still holds all the object data and is used for object constitution. The combination of the explicit field columns and the EAV properties table is used for searching.
Object type conversion
You can use the migration service to convert objects from one type to another.
Convert an explicit mapped object to a hybrid mapped object (JDBC)
This procedure demonstrates how to migrate data to a different storage configuration within the same system using the migration service to convert the object data. After you finish the conversion, the converted objects are technically hybrid objects—generically mapped objects that have certain fields that are mapped to explicit columns.
|
Considerations before you start:
|
This procedure assumes that the repository configuration includes explicitly mapped object types, and that such objects already exist in the corresponding tables. For example:
"explicitMapping" : {
...
"managed/objectToConvert" : {
"table" : "objecttoconvert",
"objectToColumn" : {
"_id" : "objectid",
"_rev" : "rev",
"desc" : "descr"
}
}-
Create the new generic table and associated properties table. Adjust the following example to match your repository requirements, as needed:
CREATE TABLE `openidm`.`objecttoconvert_gen` ( `id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT , `objecttypes_id` BIGINT UNSIGNED NOT NULL , `objectid` VARCHAR(255) NOT NULL , `rev` VARCHAR(38) NOT NULL , `descr` VARCHAR(255) NOT NULL , `fullobject` MEDIUMTEXT NULL , PRIMARY KEY (`id`) , UNIQUE INDEX `idx-objecttoconvert_object` (`objecttypes_id` ASC, `objectid` ASC) , INDEX `fk_objecttoconvert_objectypes` (`objecttypes_id` ASC) , CONSTRAINT `fk_objecttoconvert_objectypes` FOREIGN KEY (`objecttypes_id` ) REFERENCES `openidm`.`objecttypes` (`id` ) ON DELETE CASCADE ON UPDATE NO ACTION) ENGINE = InnoDB; CREATE TABLE IF NOT EXISTS `openidm`.`objecttoconvert_genproperties` ( `objecttoconvert_gen_id` BIGINT UNSIGNED NOT NULL , `propkey` VARCHAR(255) NOT NULL , `proptype` VARCHAR(32) NULL , `propvalue` VARCHAR(2000) NULL , `propindex` BIGINT NOT NULL DEFAULT 0, PRIMARY KEY (`objecttoconvert_gen_id`, `propkey`, `propindex`), INDEX `fk_objecttoconvertproperties_managedobjects` (`objecttoconvert_gen_id` ASC) , INDEX `idx_objecttoconvertproperties_propkey` (`propkey` ASC) , INDEX `idx_objecttoconvertproperties_propvalue` (`propvalue`(255) ASC) , CONSTRAINT `fk_objecttoconvertproperties_objecttoconvert` FOREIGN KEY (`objecttoconvert_gen_id` ) REFERENCES `openidm`.`objecttoconvert_gen` (`id` ) ON DELETE CASCADE ON UPDATE NO ACTION) ENGINE = InnoDB; -
Modify
conf/repo.jdbc.jsonto map the object path in the generic mapping section to the empty generic table. If the migrated data will have additional searchable columns, add them now. -
Create a
conf/migration.jsonfile with the following details:-
Update the authentication settings to match the system configuration.
-
Modify the
instanceUrlto point to the same system.For example:
{ "enabled" : true, "endpoint" : "", "connection" : { "instanceUrl" : "http://localhost:8080/openidm/", "authType" : "basic", "userName" : "openidm-admin", "password" : "openidm-admin" }, "mappings" : [ { "target" : "repo/managed/objectToConvert_gen", "source" : "repo/managed/objectToConvert" } ] }
-
-
Call the migration service to view the mapping name that was generated:
curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header 'Accept-API-Version: resource=1.0' \ --request POST 'http://localhost:8080/openidm/migration?_action=mappingNames' [ [ "repoManagedObjecttoconvert_repoManagedObjecttoconvertGen" ] ] -
Start the migration:
curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header "Accept-API-Version: resource=1.0" \ --request POST \ "http://localhost:8080/openidm/migration?_action=migrate&mapping=repoManagedObjecttoconvert_repoManagedObjecttoconvertGen" { "migrationResults": { "recons": [ { "name": "repoManagedObjecttoconvert_repoManagedObjecttoconvertGen", "status": "PENDING" } ] } } -
You must wait until the migration is completed. To check the status of the migration:
curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header 'Accept-API-Version: resource=1.0' \ --request POST 'http://localhost:8080/openidm/migration?_action=status'
Example Return
{ "migrationResults": { "recons": [ { "name": "repoManagedObjecttoconvert_repoManagedObjecttoconvertGen", "status": { "_id": "820a1c66-6f1a-41d8-82a4-fc5a2d246326-424", "mapping": "repoManagedObjecttoconvert_repoManagedObjecttoconvertGen", "state": "SUCCESS", "stage": "COMPLETED_SUCCESS", "stageDescription": "reconciliation completed.", "progress": { "source": { "existing": { "processed": 0, "total": "9" } }, "target": { "existing": { "processed": 0, "total": "?" }, "created": 0, "unchanged": 0, "updated": 0, "deleted": 0 }, "links": { "existing": { "processed": 0, "total": "0" }, "created": 0 } }, "situationSummary": { "SOURCE_IGNORED": 0, "FOUND_ALREADY_LINKED": 0, "UNQUALIFIED": 0, "ABSENT": 0, "TARGET_IGNORED": 0, "MISSING": 0, "ALL_GONE": 0, "UNASSIGNED": 0, "AMBIGUOUS": 0, "CONFIRMED": 0, "LINK_ONLY": 0, "SOURCE_MISSING": 0, "FOUND": 0 }, "statusSummary": { "SUCCESS": 0, "FAILURE": 9 }, "durationSummary": { "sourceObjectQuery": { "min": 26, "max": 33, "mean": 30, "count": 9, "sum": 277, "stdDev": 2 }, "sourceQuery": { "min": 37, "max": 37, "mean": 37, "count": 1, "sum": 37, "stdDev": 0 }, "auditLog": { "min": 0, "max": 1, "mean": 0, "count": 11, "sum": 9, "stdDev": 0 }, "linkQuery": { "min": 4, "max": 4, "mean": 4, "count": 1, "sum": 4, "stdDev": 0 }, "correlationQuery": { "min": 8, "max": 18, "mean": 15, "count": 9, "sum": 139, "stdDev": 4 }, "sourcePhase": { "min": 113, "max": 113, "mean": 113, "count": 1, "sum": 113, "stdDev": 0 } }, "parameters": { "sourceQuery": { "resourceName": "external/migration/repo/managed/objectToConvert", "queryFilter": "true", "_fields": "_id" }, "targetQuery": { "resourceName": "repo/managed/objectToConvert_gen", "queryFilter": "true", "_fields": "_id" } }, "started": "2021-01-20T18:22:34.026Z", "ended": "2021-01-20T18:22:34.403Z", "duration": 377, "sourceProcessedByNode": {} } } ] } }Optionally, you can run the migration again to account for changes that may have occurred during the original migration. The data is now migrated to the new tables, but IDM is still referencing the previous mapping.
-
Edit the
repo.jdbc.jsonfile:-
Remove the old mapping from
explicitMapping:"explicitMapping" : { ... "managed/objectToConvert" : { "table" : "objecttoconvert", "objectToColumn" : { "_id" : "objectid", "_rev" : "rev", "desc" : "descr" } } -
Modify the newly added
genericMappingto point to the old resource path:"genericMapping" : { ... "managed/objectToConvert" : { "mainTable" : "objecttoconvert_gen", "propertiesTable" : "objecttoconvert_genproperties", "searchableDefault" : false, "objectToColumn" : { "_id" : "objectid", "_rev" : "rev", "desc" : "descr" }, "properties": { "/stringArrayField" : { "searchable" : true } } }, }
-
-
Run a SQL update statement so that the
objecttypestable points the temporary object type to the original object type. Adjust the following example to match your repository requirements, as needed:update openidm.objecttypes set objecttype = 'managed/objectToConvert' where objecttype = 'managed/objectToConvert_gen';
Convert a generic mapped object to an explicit mapped object (JDBC)
This procedure demonstrates how to migrate data to a different storage configuration within the same system using the migration service to convert the object data.
|
Considerations before you start:
|
This procedure assumes an existing generic object resource path of managed/objectToConvert, with objects stored in the generic objects table genericobjects. A sample object might be:
{
"_id" : "4213-2134-23423",
"_rev" : "AB231A",
"name" : "Living room camera",
"properties": { "location" : "45.123N100.123W", "uptime" : 123123 },
"otherProperties" : { "bla": "blabla", "blahdee" : "da"}
}Before you start, consider the following:
-
Make sure to map a column to each field of your object.
-
Fields that are objects, not simple scalar values, will be stored as serialized JSON, and won’t be easily searchable.
-
Object instances are constituted by selecting the mapped columns and putting the data in the JSON object using the field path that the column is mapped to.
-
Create table indexes that are inline with your system’s usage of searches and sorting of the column data. For example, modify or add indexes to include all newly created columns for any fields that were configured as searchable.
-
Create the new explicit table:
CREATE TABLE `openidm`.`objectToConvert` ( `objectid` VARCHAR(255) NOT NULL , `rev` VARCHAR(38) NOT NULL , `name` VARCHAR(255) NOT NULL , `location` VARCHAR(38) NULL , `uptime` BIGINT NULL , `misc` MEDIUMTEXT NULL, PRIMARY KEY (`objectid`)); -
Modify
conf/repo.jdbc.jsonto add a new mapping for the object type in theexplicitMappingnode. To avoid conflict with the generically mapped object path, slightly modify the resource path. A new explicit mapping example:"explicitMapping" : { ... "managed/objectToConvert_explicit": { "table": "objectToConvert", "objectToColumn" : { "_id" : "objectid", "_rev" : { "column" : "rev", "isNotNull" : true }, "name" : { "column" : "name", "isNotNull" : true }, "properties/location" : { "column": "location" }, "properties/uptime" : { "column" : "uptime" }, "otherProperties" : { "column" : "misc", "type" : "JSON_MAP" } } } ... ... } -
Create a
conf/migration.jsonfile with the following details:-
Update the authentication settings to match the system configuration.
-
Modify the
instanceUrlto point to the same system.For example:
{ "enabled" : true, "endpoint" : "", "connection" : { "instanceUrl" : "http://localhost:8080/openidm/", "authType" : "basic", "userName" : "openidm-admin", "password" : "openidm-admin" }, "mappings" : [ { "target" : "repo/managed/objectToConvert_explicit", "source" : "repo/managed/objectToConvert" } ] }
-
-
Call the migration service to view the mapping name that was generated:
curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header 'Accept-API-Version: resource=1.0' \ --request POST 'http://localhost:8080/openidm/migration?_action=mappingNames'
IDM returns something similar to:
[ [ "repoManagedObjecttoconvert_repoManagedObjecttoconvertExplicit" ] ] -
Start the migration:
curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header "Accept-API-Version: resource=1.0" \ --request POST \ "http://localhost:8080/openidm/migration?_action=migrate&mapping=repoManagedObjecttoconvert_repoManagedObjecttoconvertExplicit"
IDM returns something similar to:
{ "migrationResults": { "recons": [ { "name": "repoManagedObjecttoconvert_repoManagedObjecttoconvertExplicit", "status": "PENDING" } ] } } -
You must wait until the migration completes. To check the status of the migration:
curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header 'Accept-API-Version: resource=1.0' \ --request POST 'http://localhost:8080/openidm/migration?_action=status'
IDM returns something similar to:
{ "migrationResults": { "recons": [ { "name": "repoManagedObjecttoconvert_repoManagedObjecttoconvertExplicit", "status": { "_id": "820a1c66-6f1a-41d8-82a4-fc5a2d246326-424", "mapping": "repoManagedObjecttoconvert_repoManagedObjecttoconvertExplicit", "state": "SUCCESS", "stage": "COMPLETED_SUCCESS", "stageDescription": "reconciliation completed.", "progress": { "source": { "existing": { "processed": 0, "total": "9" } }, "target": { "existing": { "processed": 0, "total": "?" }, "created": 0, "unchanged": 0, "updated": 0, "deleted": 0 }, "links": { "existing": { "processed": 0, "total": "0" }, "created": 0 } }, "situationSummary": { "SOURCE_IGNORED": 0, "FOUND_ALREADY_LINKED": 0, "UNQUALIFIED": 0, "ABSENT": 0, "TARGET_IGNORED": 0, "MISSING": 0, "ALL_GONE": 0, "UNASSIGNED": 0, "AMBIGUOUS": 0, "CONFIRMED": 0, "LINK_ONLY": 0, "SOURCE_MISSING": 0, "FOUND": 0 }, "statusSummary": { "SUCCESS": 0, "FAILURE": 9 }, "durationSummary": { "sourceObjectQuery": { "min": 26, "max": 33, "mean": 30, "count": 9, "sum": 277, "stdDev": 2 }, "sourceQuery": { "min": 37, "max": 37, "mean": 37, "count": 1, "sum": 37, "stdDev": 0 }, "auditLog": { "min": 0, "max": 1, "mean": 0, "count": 11, "sum": 9, "stdDev": 0 }, "linkQuery": { "min": 4, "max": 4, "mean": 4, "count": 1, "sum": 4, "stdDev": 0 }, "correlationQuery": { "min": 8, "max": 18, "mean": 15, "count": 9, "sum": 139, "stdDev": 4 }, "sourcePhase": { "min": 113, "max": 113, "mean": 113, "count": 1, "sum": 113, "stdDev": 0 } }, "parameters": { "sourceQuery": { "resourceName": "external/migration/repo/managed/objectToConvert", "queryFilter": "true", "_fields": "_id" }, "targetQuery": { "resourceName": "repo/managed/objectToConvert_explicit", "queryFilter": "true", "_fields": "_id" } }, "started": "2021-01-20T18:22:34.026Z", "ended": "2021-01-20T18:22:34.403Z", "duration": 377, "sourceProcessedByNode": {} } } ] } }Optionally, you can run the migration again to account for changes that may have occurred during the original migration. The data is now migrated to the new tables, but IDM is still referencing the previous mapping and generic table.
-
Edit the
repo.jdbc.jsonfile:-
If the mapping of the generic resource had a mapping, it should be removed. If the generic resource was included in the
managed/*path, as in the example, there is nothing to remove. -
Modify the object path from
managed/objectToConvert_explicittomanaged/objectToConvert.
-
-
Save the
repo.jdbc.jsonfile.Until IDM processes the configuration change, REST requests are unavailable.
-
Once IDM finishes processing the configuration change, it is safe to delete the object data from the original generic table. Using a proper delete cascade, the searchable properties of the generic object are automatically deleted from the generic properties table. For example:
delete from managedobjects where objecttypes_id = ( select o2.id from objecttypes o2 where objecttype = "managed/objectToConvert");
Convert a generic mapped object to a hybrid mapped object (JDBC)
This procedure demonstrates how to convert a generically stored property to an explicitly stored property; moving property value storage out of the object’s property table, and into a new column on the object table. After you finish the conversion, the converted objects are technically hybrid objects—generically mapped objects that have certain fields that are mapped to explicit columns.
|
Considerations before you start:
|
This procedure assumes an existing generic object resource path as: managed/objectToConvert, with objects stored in the generic objects table objecttoconvertobjects. A sample object might be:
{
"_id" : "4213-2134-23423",
"_rev" : "AB231A",
"name" : "Living room camera",
"properties": { "location" : "45.123N100.123W", "uptime" : 123123 },
"otherProperties" : { "bla": "blabla", "blahdee" : "da"}
}-
Create a new database column for the explicit field data:
alter table openidm.objecttoconvertobjects add column `name` varchar(255); -
Edit the
genericMappingsection of theconf/repo.jdbc.jsonfile:-
For each object to convert, add the
objectToColumnconfiguration for the fields to explicitly map to a column. For example:"genericMapping" : { ... "managed/objectToConvert": { "mainTable" : "objecttoconvertobjects", "propertiesTable" : "objecttoconvertobjectsproperties", "searchableDefault" : true, "objectToColumn" : { "name" : "name" } } ... } -
If the object is defined with a wildcard mapping, such as
managed/*, create a new mapping specifically for the object conversion.
-
-
Save the
conf/repo.jdbc.jsonfile.Until IDM processes the configuration change, REST requests are unavailable.
-
For any added columns to be usable, they must be reindexed and populated.
The
rewriteObjects.jsscript can read and rewrite object data to match the config from theconf/repo.jdbc.jsonfile. The script reads one page of data at a time, and then writes out each object, one at a time. Consider the page size and queryFilter to efficiently process the data by splitting the data into groups that can run in parallel. The request will not return until ALL pages have been processed.For example, to run the
rewriteObjects.jsscript with 1000 objects per page:curl \ --header "X-OpenIDM-Username: openidm-admin" \ --header "X-OpenIDM-Password: openidm-admin" \ --header 'Accept-API-Version: resource=1.0' \ --header 'content-type: application/json' \ --request POST \ --data-raw '{ "type":"text/javascript", "file":"bin/defaults/script/update/rewriteObjects.js", "globals" : { "rewriteConfig" :{ "queryFilter": "true", "pageSize": 1000, "objectPaths": [ "repo/managed/objectToConvert" ] } } }' \ "http://localhost:8080/openidm/script?_action=eval" -
Now that the new column contains data, edit or create new indexes so that the new column can be queried efficiently. For example:
alter table openidm.objecttoconvertobjects add index `idx_obj_name` (`name`);