About replication
Replication is the process of copying updates between DS servers so all directory servers eventually converge on identical copies of directory data. DS servers that replicate their data are replicas. Since replication is eventually convergent, different replicas can be momentarily out of sync. If you lose an individual replica, or even an entire data center, the remaining replicas continue to provide service. Applications can still write changes to the directory data. Replication brings the replicas back in sync when the problem is repaired.
Replication uses a DS-specific protocol that works only between DS replicas. It replays update operations quickly, storing historical change data to resolve most conflicts automatically. For example, if two client applications separately update a user entry to change the phone number, replication can identify the latest change, and apply it on all replicas without human intervention. To prevent the historical change data from growing forever, DS replicas purge historical data that is older than a configurable interval (default: three days).
DS software supports replication over fast and slow networks. For advanced deployments across multiple sites with many replicas and slow links, consider standalone servers. For details, refer to Install standalone servers (advanced).
Replication is resilient to host clock anomalies.
You should, however, aim to keep server clocks synchronized using ntpd, for example.
Keeping replica clocks synchronized helps prevent issues when validating certificates for secure connections,
and makes it easier to compare timestamps from multiple replicas.
Replication is designed to overcome the following issues:
-
Clock skew between different replicas.
Replication adjusts for skew automatically, and using
ntpdfurther mitigates this.Very large skew, such as replicating with a system whose clock was started at 0 (January 1, 1970), can cause problems.
-
Forward and backward clock adjustments on a single replica.
Replication adjusts for these automatically.
Very large changes, such as abruptly setting the clock back an entire day, can cause problems.
-
Timezone differences and adjustments.
Replication uses UTC time.
Very large host clock anomalies can result in the following symptoms:
-
SSL certificate validation errors, when the clocks are far enough apart that the validity dates cannot be correctly compared.
-
Problems with time-based settings in access control instruction subjects, and with features that depend on timestamps, such as password age and last login attributes.
-
Misleading changelog timestamps and replication-related monitoring data.
-
Incorrect replication conflict resolution.
-
Incorrect replication purge delay calculation.
Ready to replicate
When you set up a server, you can specify the following:
-
The replication port.
If specified, the setup process configures the server as a replication server.
-
The bootstrap replication servers' host:port combinations.
When the server starts, it contacts the bootstrap replication servers to discover other replicas and replication servers.
Setup profiles that create backends for schema and directory data configure replication domains for their base DNs. The server is ready to replicate that directory data when it starts up.
Replication initialization depends on the state of the data in the replicas.
DS replication shares changes, not data. When a replica applies an update, it sends a message to its replication server. The replication server forwards the update to all other replication servers, and to its replicas. The other replication servers do the same, so the update is eventually propagated to all replicas.
Each replica eventually converges on the same data by applying each update and resolving conflicts in the same way. As long as each replica starts from the same initial state, each replica eventually converges on the same state. It is crucial, therefore, for each replica to begin in the same initial state. Replicas cannot converge by following exactly the same steps from different initial states.
Internally, DS replicas store a shorthand form of the initial state called a generation ID. The generation ID is a hash of the first 1000 entries in a backend. If the replicas' generation IDs match, the servers can replicate data without user intervention. If the replicas' generation IDs do not match for a given backend, you must manually initialize replication between them to force the same initial state on all replicas.
If necessary, and before starting the servers, further restrict TLS protocols and cipher suites on all servers. This forces the server to use only the restricted set of protocols and cipher suites. For details, refer to TLS settings.
Replication per base DN
The primary unit of replication is the replication domain.
A replication domain has a base DN, such as dc=example,dc=com.
The set of DS replicas and replication servers sharing one or more replication domains is a replication topology. Replication among these servers applies to all the data under the domain’s base DN.
The following example topology replicates dc=example,dc=com, dc=example,dc=org, and dc=example,dc=net.
All the replication servers in a topology are fully connected, replicating the same data under each base DN:
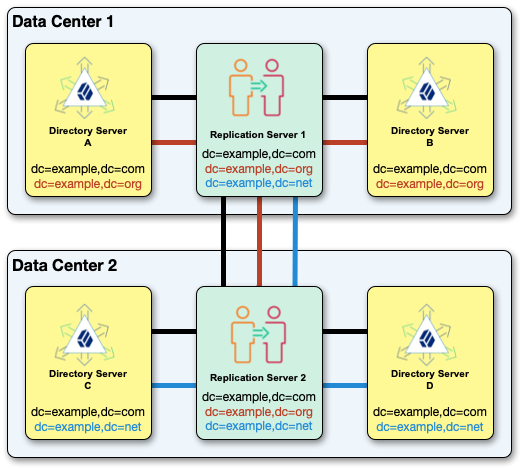
Replication doesn’t support separate, independent domains for the same base DN in the same topology.
For example, you can’t replicate two dc=example,dc=org domains with different data in the same topology:
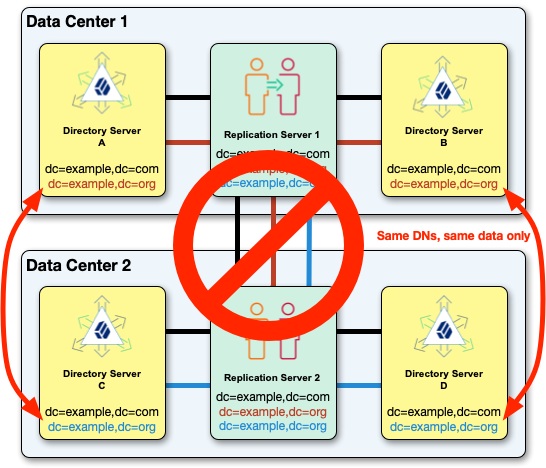
When you set up a replication domain, replicate the data under the base DN among all the servers in the topology. If the data under a base DN is different on different servers, configure the servers appropriately:
| Difference | Use this |
|---|---|
Different data under the same base DN. |
Separate replication topologies. In other words, put the replicas and replication servers in independent deployments unless the data matches. |
Some replicas have only part of the data under a base DN. |
|
Some replicas have only a subset of LDAP attributes. |
Replication depends on the directory schema under cn=schema.
If applications require specific, non-standard schema definitions or can update the LDAP schema online,
replicate cn=schema with the other base DNs.
Port use and operations
DS servers listen on dedicated ports for administrative requests and for replication requests. These dedicated ports must remain open to remote requests from configuration tools and from other servers. Make sure that firewall software allows connections to the administration and replication ports from all connecting servers.
DS server configuration tools securely connect to administration ports. Administrative connections are short-lived.
DS replicas connect to DS replication ports for replication requests. A server listening on a replication port is called a replication server, whether it is running inside the same process as a directory server, or on a separate host system. Replication connections are long-lived. Each DS replica connects to a replication server upon initialization and then at startup time. The replica keeps the connection open to push and receive updates, although it can connect to another replication server.
The command to initialize replication uses the administrative port, and initialization uses the replication port:

DS replicas push updates to and receive updates from replication servers over replication connections. When processing an update, a replica (DS) pushes it to the replication server (RS) it is connected to. The replication server pushes the update to connected replicas and to other replication servers. Replicas always connect through replication servers.
A replica with a replication port and a changelog plays both roles (DS/RS), normally connecting to its own replication server. A standalone replica (DS) connects to a remote replication server (RS). The replication servers connect to each other. The following figure shows the flow of messages between standalone replicas and replication servers.

The command to monitor replication status uses the administration ports on multiple servers to connect and read monitoring information, as shown in the following sequence diagram:

Replication connection selection
DS servers can provide both directory services and replication services. The two services are not the same, even if they usually run alongside each other in the same DS server.
Replication relies on the replication service provided by DS replication servers. DS directory servers (replicas) publish changes made to their data, and subscribe to changes published by other replicas. The replication service manages replication data only, sending and receiving replication messages. A replication server receives, sends, and stores only changes to directory data, not the data itself.
The directory service manages directory data.
It responds to requests, and stores directory data and historical information.
For each replicated base DN, such as dc=example,dc=com or cn=schema,
the directory service publishes changes to and subscribes to changes from a replication service.
The directory service resolves any conflicts that arise when reconciling changes from other replicas,
using the historical information about changes to resolve the conflicts.
(Conflict resolution is the responsibility of the directory server rather than the replication server.)
After a directory server connects to a replication topology, it connects to one replication server at a time for a given domain. The replication server provides the directory server with the list of all replication servers for that base DN. Given this list, the directory server selects its preferred replication server when starting up, when it loses the current connection, or when the connection becomes unresponsive.
For each replicated base DN, a directory server prefers to connect to a replication server:
-
In the same JVM as the directory server.
-
In the same group as the directory server.
By default, if no replication server in the same group is available, the directory server chooses a replication server from any available group.
To define the order of failover across replication groups, set the global configuration property, group-id-failover-order. When this property is set and no replication server is available in the directory server’s group, the directory server chooses a replication server from the next group in the list.
-
With the same initial data under the base DN as the directory server.
-
If initial data was the same, a replication server with all the latest changes from the directory server.
-
With the most available capacity relative to other eligible replication servers.
Available capacity depends on how many replicas in the topology are already connected to the replication server, and what proportion of all replicas ought to be connected to the replication server.
To determine what proportion ought to be connected, a directory server uses replication server weight. When configuring a replication server, you can assign it a weight (default: 1). The weight property takes an integer that indicates capacity relative to other replication servers. For example, a weight of 2 indicates a replication server that can handle twice as many connected replicas as one with weight 1.
The proportion that ought to be connected is
(replication server weight)/(sum of replication server weights). If there are four replication servers with weight 1, the proportion for each is 1/4.
Consider a dc=example,dc=com topology with five directory servers connected to replication servers A, B, and C, where:
-
Two directory servers are connected to replication server A.
-
Two directory servers are connected to replication server B.
-
One directory server is connected to replication server C.
Replication server C is the server with the most available capacity. All other criteria being equal, replication server C is the server to connect to when another directory server joins the topology.
The directory server regularly updates the list of replication servers in case it must reconnect. As available capacity can change dynamically, a directory server can reconnect to another replication server to balance the replication load in the topology. For this reason, the server can also end up connected to different replication servers for different base DNs.