Comprehensive plans
Your comprehensive deployment plan should cover the following themes.
Team training
Training provides a common understanding, vocabulary, and basic skills for those working together on the project. Depending on previous experience with access management and with DS software, both internal teams and project partners might need training.
The type of training team members need depends on their involvement in the project:
-
All team members should take at least some training that provides an overview of DS software. This helps to ensure a common understanding and vocabulary for those working on the project.
-
Team members planning the deployment should take an DS training before finalizing their plans, and ideally before starting to plan the deployment.
DS training pays for itself as it helps you to make the right initial choices to deploy more quickly and successfully.
-
Team members involved in designing and developing DS client applications or custom plugins should take training in DS development in order to help them make the right choices.
-
Team members who have already had been trained in the past might need to refresh their knowledge if your project deploys newer or significantly changed features, or if they have not worked with DS software for some time.
ForgeRock University regularly offers training courses for DS topics. For a current list of available courses, refer to the ForgeRock web site.
When you have determined who needs training and the timing of the training during the project, prepare a training schedule based on team member and course availability. Include the scheduled training plans in your deployment project plan.
ForgeRock also offers an accreditation program for partners, including an in-depth assessment of business and technical skills for each ForgeRock product. This program is open to the partner community and ensures that best practices are followed during the design and deployment phases.
Customization
DS servers provide a Java plugin API that allows you to extend and customize server processing. A server plugin is a library that you plug into an installed server and configure for use. The DS server calls the plugin as described in Plugin types.
DS servers have many features that are implemented as server plugin extensions. This keeps the core server processing focused on directory logic, and loosely coupled with other operations.
When you create your own custom plugin, be aware you must at a minimum recompile and potentially update your plugin code for every DS server update. The plugin API has interface stability: Evolving. A plugin built with one version of a server is not guaranteed to run or even to compile with a subsequent version. Only create your own custom plugin when you require functionality that the server cannot be configured to provide. The best practice is to deploy DS servers with a minimum of custom plugins.
|
ForgeRock supports customers using standard plugins delivered as part of DS software. If you deploy with custom plugins and need support in production, contact info@forgerock.com in advance to determine how your deployment can be supported. |
Although some custom plugins involve little development work, they can require additional scheduling and coordination. The more you customize, the more important it is to test your deployment thoroughly before going into production. Consider each custom plugin as sub-project with its own acceptance criteria. Prepare separate plans for unit testing, automation, and continuous integration of each custom plugin. For details, refer to Tests.
When you have prepared plans for each custom plugin sub-project, you must account for those plans in your overall deployment project plan.
Plugin types
Plugin types correspond to the points where the server invokes the plugin.
For the full list of plugin invocation points, refer to the Javadoc for PluginType. The following list summarizes the plugin invocation points:
-
At server startup and shutdown
-
Before and after data export and import
-
Immediately after a client connection is established or is closed
-
Before processing begins on an LDAP operation (to change an incoming request before it is decoded)
-
Before core processing for LDAP operations (to change the way the server handles the operation)
-
After core processing for LDAP operations (where the plugin can access all information about the operation including the impact it has on the targeted entry)
-
When a subordinate entry is deleted as part of a subtree delete, or moved or renamed as part of a modify DN operation
-
Before sending intermediate and search responses
-
After sending a result
A plugin’s types are specified in its configuration, and can therefore be modified at runtime.
Plugin configuration
Server plugin configuration is managed with the same configuration framework that is used for DS server configuration.
The DS configuration framework has these characteristics:
-
LDAP schemas govern what attributes can be used in plugin configuration entries.
For all configuration attributes that are specific to a plugin, the plugin should have its own object class and attributes defined in the server LDAP schema. Having configuration entries governed by schemas makes it possible for the server to identify and prevent configuration errors.
For plugins, having schema for configuration attributes means that an important part of plugin installation is making the schema definitions available to the DS server.
-
The plugin configuration is declared in XML files.
The XML specifies configuration properties and their documentation, and inheritance relationships.
The XML Schema Definition files (.xsd files) for the namespaces used are not published externally. For example, the namespace identifier
http://opendj.forgerock.org/adminis not an active URL. An XML configuration definition has these characteristics:-
The attributes of the
<managed-object>element define XML namespaces, a (singular) name and plural name for the plugin, and the Java-related inheritance of the implementation to generate. A managed object is a configurable component of DS servers.A managed object definition covers the object’s structure and inheritance, and is like a class in Java. The actual managed object is like an instance of an object in Java. Its configuration maps to a single LDAP entry in the configuration backend
cn=config.Notice that the
<profile>element defines how the whole object maps to an LDAP entry in the configuration. The<profile>element is mandatory, and should include an LDAP profile.The
nameandplural-nameproperties are used to identify the managed object definition. They are also used when generating Java class names. Names must be a lowercase sequence of words separated by hyphens.The
packageproperty specifies the Java package name for generated code.The
extendsproperty identifies a parent definition that the current definition inherits. -
The mandatory
<synopsis>element provides a brief description of the managed object.If a longer description is required, add a
<description>. The<description>is used in addition to the synopsis, so there is no need to duplicate the synopsis in the description. -
The
<property>element defines a property specific to the plugin, including its purpose, its default value, its type, and how the property maps to an LDAP attribute in the configuration entry.The
nameattribute is used to identify the property in the configuration. -
The
<property-override>element sets the pre-defined propertyjava-classto the fully qualified implementation class.
-
-
Compilation generates the server-side and client-side APIs to access the plugin configuration from the XML. To use the server-side APIs in a plugin project, first generate and compile them, and then include the classes on the project classpath.
When a plugin is loaded in the DS server, the client-side APIs are available to configuration tools like the
dsconfigcommand. Directory administrators can configure a custom plugin in the same way they configure other server components. -
The framework supports internationalization.
The plugin implementation selects appropriate messages from the resource bundle based on the server locale. If no message is available for the server locale, the plugin falls back to the default locale.
A complete plugin project includes LDAP schema definitions, XML configuration definitions, Java plugin code, and Java resource bundles. For examples, refer to the sample plugins delivered with DS software.
Pilot projects
Unless you are planning a maintenance upgrade, consider starting with a pilot implementation, which is a long-term project that is aligned with your specific requirements.
A pilot shows that you can achieve your goals with DS software plus whatever custom plugins and companion software you expect to use. The idea is to demonstrate feasibility by focusing on solving key use cases with minimal expense, but without ignoring real-world constraints. The aim is to fail fast, before investing too much, so you can resolve any issues that threaten the deployment.
Do not expect the pilot to become the first version of your deployment. Instead, build the pilot as something you can afford to change easily, and to throw away and start over if necessary.
The cost of a pilot should remain low compared to overall project cost. Unless your concern is primarily the scalability of your deployment, you run the pilot on a much smaller scale than the full deployment. Scale back on anything not necessary to validating a key use case.
Smaller scale does not necessarily mean a single-server deployment, though. If you expect your deployment to be highly available, for example, one of your key use cases should be continued smooth operation when part of your deployment becomes unavailable.
The pilot is a chance to experiment with and test features and services before finalizing your plans for deployment. The pilot should come early in your deployment plan, leaving appropriate time to adapt your plans based on the pilot results. Before you can schedule the pilot, team members might need training. You might require prototype versions of functional customizations.
Plan the pilot around the key use cases that you must validate. Make sure to plan the pilot review with stakeholders. You might need to iteratively review pilot results as some stakeholders refine their key use cases based on observations.
Directory data model
Before you start defining how to store and access directory data, you must know what data you want to store, and how client applications use the data. You must have or be able to generate representative data samples for planning purposes. You must be able to produce representative client traffic for testing.
When defining the directory information tree (DIT) and data model for your service, answer the following questions:
-
What additional schema definitions does your directory data require?
Refer to LDAP schema extensions.
-
What are the appropriate base DNs and branches for your DIT?
Refer to The DIT.
-
How will applications access the directory service? Over LDAP? Over HTTP?
Refer to Data views.
-
Will a single team manage the directory service and the data? Will directory data management be a shared task, delegated to multiple administrators?
Refer to Data management.
-
What groups will be defined in your directory service?
Refer to Groups.
-
What sort of data will be shared across many directory entries? Should you define virtual or collective attributes to share this data?
Refer to Shared data.
-
How should you cache data for appropriate performance?
Refer to Caching.
-
How will identities be managed in your deployment?
Refer to Identity management.
LDAP schema extensions
As described in LDAP schema, DS servers ship with many standard LDAP schema definitions. In addition, you can update LDAP schema definitions while the server is online.
This does not mean, however, that you can avoid schema updates for your deployment. Instead, unless the data for your deployment requires only standard definitions, you must add LDAP schema definitions before importing your data.
Follow these steps to prepare the schema definitions to add:
-
If your data comes from another LDAP directory service, translate the schema definitions used by the data from the existing directory service. Use them to start an LDIF modification list of planned schema updates, as described in Update LDAP schema.
The schema definitions might not be stored in the same format as DS definitions. Translating from existing definitions should be easier than creating new ones, however.
As long as the existing directory service performs schema checking for updates, the directory data you reuse already conforms to those definitions. You must apply them to preserve data integrity.
-
If your data comes from applications that define their own LDAP schema, add those definitions to your list of planned schema updates.
-
Match as much of your data as possible to the standard LDAP schema definitions listed in the LDAP schema reference.
-
Define new LDAP schema definitions for data that does not fit existing definitions. This is described in About LDAP schema, and Update LDAP schema.
Add these new definitions to your list.
Avoid any temptation to modify or misuse standard definitions, as doing so can break interoperability.
Once your schema modifications are ready, use comments to document your choices in the source LDIF. Keep the file under source control. Apply a change control process to avoid breaking schema definitions in the future.
Perhaps you can request object identifiers (OIDs) for new schema definitions from an OID manager in your organization. If not, either take charge of OID assignment, or else find an owner who takes charge. OIDs must remain globally unique, and must not be reused.
The DIT
When defining the base DNs and hierarchical structure of the DIT, keep the following points in mind:
-
For ease of use, employ short, memorable base DNs with RDNs using well-known attributes.
For example, you can build base DNs that correspond to domain names from domain component (
dc) RDNs. The sample data for Example.com usesdc=example,dc=com.Well-known attributes used in base DNs include the following:
-
c: country, a two-letter ISO 3166 country code -
dc: component of a DNS domain name -
l: locality -
o: organization -
ou: organizational unit -
st: state or province name
-
-
For base DNs and hierarchical structures, depend on properties of the data that do not change.
For example, the sample data places all user entries under
ou=People,dc=example,dc=com. There is no need to move a user account when the user changes status, role in the organization, location, or any other property of their account. -
Introduce hierarchical branches in order to group similar entries.
As an example of grouping similar entries, the following branches separate apps, devices, user accounts, and LDAP group entries:
-
ou=Apps,dc=example,dc=com -
ou=Devices,dc=example,dc=com -
ou=Groups,dc=example,dc=com -
ou=People,dc=example,dc=com
In this example, client application accounts belong under
ou=Apps. A user account underou=Peoplefor a device owner or subscriber can have an attribute referencing devices underou=Devices. Device entries can reference theirownerinou=People. Group entries can include members from any branch. Their members' entries would reference the groups withisMemberOf. -
-
Otherwise, use hierarchical branches only as required for specific features. Such features include the following:
-
Access control
-
Data distribution
-
Delegated administration
-
Replication
-
Subentries
Use delegated administration when multiple administrators share the directory service. Each has access to manage a portion of the directory service or the directory data. By default, ACIs and subentries apply to the branch beneath their entry or parent. If a delegated administrator must be able to add or modify such operational data, the DIT should prevent the delegated administrator from affecting a wider scope than you intend to delegate.
-
As described in About replication, the primary unit of replication is the base DN. If necessary, you can split a base DN into multiple branches. For example use cases, read Deployment patterns.
Once you have defined your DIT, arrange the directory data you import to follow its structure.
Data views
If client applications only use LDAP to access the directory service, you have few choices to make when configuring connection handlers. The choices involve how to secure connections, and whether to limit access with client hostnames or address masks. The client applications all have the same LDAP view of the directory data.
If client applications use RESTful HTTP APIs to access the directory service, then you have the same choices as for LDAP. In addition, you must define how the HTTP JSON resources map to LDAP entries.
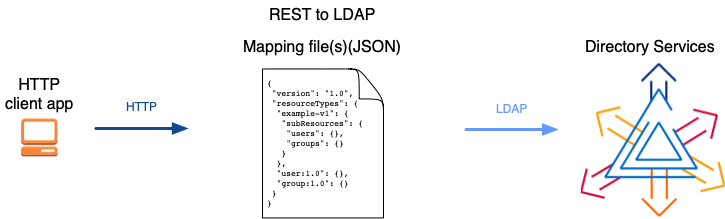
As shown above, you can define multiple versioned APIs providing alternative views of the underlying LDAP data if required for your deployment. The basic sample API that ships with DS servers is likely not sufficient. For details, refer to REST to LDAP reference.
Data management
In a shared or high-scale directory service, service management—installation and configuration, backup, and recovery—may be the responsibility of only a few specialists. These tasks may be carefully scripted.
Directory data management is, however, often a task shared by multiple users. Many of these tasks may be performed manually. In addition, users may be responsible for profile data in their own entry, including passwords, for example. You can arrange the DIT hierarchically to make it easier to scope control of administrative access.
Your plan must define who should have what access to which data, and list the privileges and access controls to grant such access. Read Administrative roles to review the alternatives.
Groups
As described in Groups, DS directory servers offer dynamic, static, and virtual static group implementations:
-
Dynamic groups identify members with an LDAP URL.
An entry belongs to a dynamic group when it matches the base DN, scope, and filter defined in a member URL of the group. Changes to the entry can modify its dynamic group membership.
-
Static groups enumerate each member. The size of a static group entry can grow very large in a high-scale directory.
-
Virtual static groups are like dynamic groups, but the server can be configured to have them return a list of members when read.
Consider your data and client applications. Use dynamic or virtual static groups whenever possible.
Shared data
As described in Virtual attributes, and Collective attributes, DS servers support virtual and collective attributes that let entries share attribute values. Sharing attribute values where it makes sense can significantly reduce data duplication, saving space and avoiding maintenance updates.
Consider your directory data. You can use virtual or collective attributes to replace attributes that repeat on many entries and can remain read-only on those entries. Familiar use cases include postal addresses that are the same for everyone in a given location, and class of service properties that depend on a service level attribute.
Caching
A directory server is an object-oriented database. It will therefore exhibit its best performance when its data is cached in memory. This is as true for large static groups mentioned in Groups as it is for all directory data.
A disadvantage of caching all data is that systems with enough RAM are more expensive. Consider the suggestions in Database Cache Settings, testing the results for your data when planning your deployment.
Identity management
DS servers have the following features that make them well-suited to serve identity data:
-
LDAP entries provide a natural model for identity profiles and accounts.
LDAP entries associate a unique name with a flat, extensible set of profile attributes such as credentials, location or contact information, descriptions, and more. LDAP schemas define what entries can contain, and are themselves extensible at runtime.
Because they are defined and accessible in standard ways, and because fine-grained access controls can protect all attributes of each entry, the profiles can be shared by all network participants as the single source of identity information.
Profile names need not be identified by LDAP DNs. For HTTP access, DS servers offer several ways to map to a profile, including mapping an HTTP user name to an LDAP name, or using an OAuth 2.0 access token instead. For devices and applications, DS servers can also map public key certificates to profiles.
-
Directory services are optimized to support common authentication mechanisms.
LDAP entries easily store and retrieve credentials, keys, PKI metadata, and more. Where passwords are used, directory services support multiple secure and legacy password storage schemes. You can also configure directory servers to upgrade password storage when users authenticate.
Each individual server can process thousands of authentication requests per second.
ForgeRock® Access Management integrates directory authentication into full access management services, including making directory authentication part of a flow that potentially involves multiple authentication steps.
-
Directory services support user self-service operations and administrator intervention.
Directory services let you protect accounts automatically or manually by locking accounts after repeated authentication failure, expiring old passwords, and tracking authentication times to distinguish active and inactive accounts. Directory services can then notify applications and users about account-related events, such as account lockout, password expiration, and other events.
Users can be granted access to update their own profiles and change their passwords securely. If necessary, administrators can also be granted access to update profiles and to reset passwords.
ForgeRock Identity Management integrates directory account management features into full identity management services.
| Topics | References |
|---|---|
Account Management |
|
Authentication |
|
Authorization |
|
Password Management |
Directory access
Consider these topics when designing the access model for your deployment.
Separation of duties (SoD)
The fewer restrictions you place on an administrative account, the greater the danger the account will be misused.
As described in Administrative access, you can avoid using directory superuser accounts for most operations. Instead, limit administrator privileges and access to grant only what their roles require. The first high-level distinction to make is between operational staff who manage the service, and those users who manage directory data. Read the section cited for fine-grained distinctions.
When your deployment involves delegated administration, it is particularly important to grant only required access to the delegates. This is easier if your DIT supports appropriate access scopes by default, as described in The DIT.
Immutable and mutable configuration
An immutable configuration does not change at runtime. A mutable configuration does change at runtime.
With an immutable configuration, you maintain the server configuration as an artifact under source control, and manage changes by applying the same process you use for other source code. This approach helps prevent surprises in production configurations. If properly applied, there is little risk of rolling out an untested change.
With a mutable configuration, operational staff have more flexibility to make changes. This approach requires even more careful change management for test and production systems.
DS server configurations can be immutable, except for the portion devoted to replication, which evolves as peer servers come and go.
DS directory data, however, must remain mutable to support write operations. As long as you separate directory data from the configuration, this does not prevent you from replacing directory server replicas. As described in Manual initialization, new replicas can start with existing data sets.
Fine-grained access
DS servers provide both HTTP and LDAP access to directory data. HTTP access to directory data eventually translates to LDAP access internally. At the LDAP level, DS servers provide powerful, fine-grained access control.
The default server behavior is to refuse all access. All DS servers therefore grant some level of access through privileges, and through access controls. For details, refer to Access control.
Access control instructions (ACIs) in directory data take the form of aci LDAP attributes,
or global-aci properties in the server configuration.
You write ACIs in a domain-specific language.
The language lets you describe concisely who has access to what under what conditions.
When configuring access control, notice that access controls apply
beneath their location in the directory information tree.
As a result, some ACIs, such as those granting access to LDAP controls and extended operations,
must be configured for the entire server rather than a particular location in the data.
Privileges
Administrative privileges provide a mechanism that is separate from access control to restrict what administrators can do.
You assign privileges to users as values of the ds-privilege-name LDAP attribute.
You can assign privileges to multiple users with collective attribute subentries.
For details, refer to Administrative privileges.
Take care when granting privileges, especially the following privileges:
-
bypass-acl: The holder is not subject to access control. -
config-write: The holder can edit the server configuration. -
modify-acl: The holder can edit access control instructions. -
privilege-change: The holder can edit administrative privileges. -
proxied-auth: The holder can make requests on behalf of another user, including directory superusers such asuid=admin.
Authentication
DS servers support a variety of authentication mechanisms.
When planning your service, use the following guidelines:
-
Limit anonymous access to public data.
-
Allow simple (username and password) authentication only over secure connections.
-
Require client applications to authenticate based on public key certificates (EXTERNAL SASL mechanism) rather than simple authentication where possible.
For details, refer to Authentication mechanisms.
Proxy layer
DS directory proxy servers, and the DS REST to LDAP gateway application encapsulate DS directory services, and offer access to other directory services.
Unlike directory servers, directory proxy servers do not hold directory data, and so use global access policies rather than ACIs. You define global access policies as server configuration objects. For details, refer to Access control.
As mentioned in System resources, be aware that for high-performance services you may need to deploy as many proxy servers or gateways as directory servers.
For details about DS LDAP proxy services, refer to LDAP proxy.
HTTP access
As described in HTTP access, you can configure DS servers to provide RESTful HTTP access.
If you deploy this capability, you must configure how HTTP resources map to LDAP entries. This is explained in Data views. For details, refer to REST to LDAP reference.
Higher-level abstraction
Although LDAP and RESTful HTTP access ensure high performance, your deployment may require a higher level of abstraction than LDAP or HTTP can provide.
Other ForgeRock® Identity Platform components offer such higher-level abstractions. For example, ForgeRock Access Management software lets you plug into directory services for authentication and account profiles, and then orchestrate powerful authentication and authorization scenarios. ForgeRock Identity Management software can plug into directory services to store configuration and account profiles, to provide user self-services, and to synchronize data with a wide variety of third-party systems.
For an introduction to the alternatives, read about the ForgeRock Identity Platform.
Data replication
Replication is the process of synchronizing data updates across directory servers. Replication is the feature that makes the directory a highly available distributed database.
Consistency and availability
Replication is designed to provide high availability with tolerance for network partitions. In other words, the service continues to allow both read and write operations when the network is down. Replication provides eventual consistency, not immediate consistency.
According to what is called the CAP theorem, it appears to be impossible to guarantee consistency, availability, and partition tolerance when network problems occur. The CAP theorem makes the claim that distributed databases can guarantee at most two of the following three properties:
- Consistency
-
Read operations reflect the latest write operation (or result in errors).
- Availability
-
Every correct operation receives a non-error response.
- Partition Tolerance
-
The service continues to respond even when the network between individual servers is down or operating in degraded mode.
When the network connection is down between two replicas, replication is temporarily interrupted. Client applications continue to receive responses to their requests, but clients making requests to different servers will not have the same view of the latest updates. The discrepancy in data on different replicas also arises temporarily when a high update load takes time to fully process across all servers.
Eventual consistency can be a trap for the unwary. The client developer who tests software only with a single directory server might not notice problems that become apparent when a load balancer spreads requests evenly across multiple servers. A single server is immediately consistent for its own data. Implicit assumptions about consistency therefore go untested.
For example, a client application that implicitly assumes immediate consistency might perform a write quickly followed by a read of the same data. Tests are all successful when only one server is involved. In deployment, however, a load balancer distributes requests across multiple servers. When the load balancer sends the read to a replica that has not yet processed the write, the client application appears to perform a successful write, followed by a successful read that is inconsistent with the write that succeeded!
When deploying replicated DS servers, keep this eventual consistency trap in mind. Educate developers about the trade off, review patches, and test and fix client applications under your control. In deployments with client applications that cannot be fixed, use affinity load balancing in DS directory proxy servers to work around broken clients. For details, refer to Load balancing.
Deploying replication
In DS software, the role of a replication server is to transmit messages about updates. Directory servers receive replication messages from replication servers, and apply updates accordingly, meanwhile serving client applications.
Deploy at least two servers in case one fails. Deploy more servers where necessary, knowing more servers means more complexity for those managing the service.
After you install a directory server and configure it as a replica, you must initialize it to the current replication state. There are a number of choices for this, as described in Manual initialization. Once a replica has been initialized, replication eventually brings its data into a consistent state with the other replicas. As described in Consistency and availability, give a heavy update load or significant network latency, temporary inconsistency is expected. You can monitor the replication status to estimate when replicas will converge on the same data set.
Client applications can adopt best practices that work with eventual consistency, as described in Best practices, Optimistic concurrency (MVCC), and Update. To work around broken client applications that assume immediate consistency, use affinity load balancing in directory proxy servers. For details, refer to Load balancing.
Some client applications need notifications when directory data changes. Client applications cannot participate in replication itself, but can get change notifications. For details, refer to Changelog for notifications.
Standalone replication servers
| This information applies to advanced deployments. |
In most modern deployments, each directory server acts as a replication server as well.
For deployments with many servers over slow or high-latency networks, DS software makes it possible to configure standalone replication servers and directory servers.
All replication servers communicate with each other. Directory servers always communicate through replication servers, even if the replication service runs in the same server process as the directory server. By assigning servers to replication groups, you ensure directory servers only connect to local replication servers until they must fail over to remote replication servers. This limits the replication traffic over slow network links to messages between replication servers, except when all local replication servers are down. For details, refer to Install standalone servers (advanced) and Replication groups (advanced).
Deploy the replication servers first. You can think of them as providing a network service (replication) in the same way DNS provides a network service (name resolution). You therefore install and start replication servers before you add directory servers.
Scaling replication
When scaling replicated directory services, keep the following rules in mind:
-
Read operations affect only one replica.
To add more read performance, use more powerful servers or add servers.
-
Write operations affect all replicas.
To add more write performance, use more powerful servers or add separate replication domains.
When a replica writes an update to its directory data set, it transmits the change information to its replication server for replay elsewhere. The replication server transmits the information to connected directory servers, and to other replication servers replicating the same data. Those replication servers transmit the message to others until all directory servers have received the change information. Each directory server must process the change, reconciling it with other change information.
As a result, you cannot scale up write capacity by adding servers. Each server must replay all the writes.
If necessary, you can scale up write capacity by increasing the capacity of each server (faster disks, more powerful servers), or by splitting the data into separate sets that you replicate independently (data distribution).
High availability
In shared directory service deployments, the directory must continue serving client requests during maintenance operations, including service upgrades, during network outage recovery, and in spite of system failures.
DS replication lets you build a directory service that is always online. DS directory proxy capabilities enable you to hide maintenance operations from client applications. You must still plan appropriate use of these features, however.
As described previously, replication lets you use redundant servers and systems to tolerate network partitions. Directory server replicas continue to serve requests when peer servers fail or become unavailable. Directory proxy servers route around directory servers that are down for maintenance or down due to failure. When you upgrade the service, you roll out one upgraded DS server at a time. New servers continue to interoperate with older servers, so the whole service never goes down. All of this depends on deploying redundant systems, including network links, to eliminate single points of failure. For more, refer to High availability.
As shown in that section, your deployment may involve multiple locations. Some deployments even use separate replication topologies, for example, to sustain very high write loads, or to separate volatile data from more static data. Carefully plan your load balancing strategy to offer good service at a reasonable cost. By using replication groups, you can limit most replication traffic over slow links to communications between replication servers. Directory proxy servers can direct client traffic to local servers until it becomes necessary to fail over to remote servers.
Sound operational procedures play as important a role in availability as good design. Operational staff maintaining the directory service must be well-trained and organized so that someone is always available to respond if necessary. They must have appropriate tools to monitor the service in order to detect situations that need attention. When maintenance, debugging, or recovery is required, they should have a planned response in most cases. Your deployment plans should therefore cover the requirements and risks that affect your service.
Before finalizing deployment plans, make sure that you understand key availability features in detail. For details about replication, read Replication and the related pages. For details about proxy features, read LDAP proxy.
Backup and recovery
Make sure your plans define how you:
-
Back up directory data
-
Safely store backup files
-
Recover your directory service from backup
DS servers store data in backends. A backend is a private server repository that can be implemented in memory, as a file, or as an embedded database. DS servers use local backends to store directory data, server configuration, LDAP schema, and administrative tasks. Directory proxy servers implement a type of backend for non-local data, called a proxy backend, which forwards LDAP requests to a remote directory service.
For performance reasons, DS servers store directory data in a local database backend, which is a backend implemented using an embedded database. Database backends are optimized to store directory data. Database backends hold data sets as key-value pairs. LDAP objects fit the key-value model very effectively, with the result that a single database backend can serve hundreds of millions of LDAP entries. Database backends support indexing and caching for fast lookups in large data sets. Database backends do not support relational queries or direct access by other applications. For more information, refer to Data storage.
Backup and restore procedures are described in Backup and restore. When planning your backup and recovery strategies, be aware of the following key features:
-
Backups are not guaranteed to be compatible across major and minor server releases. Restore backups only on directory servers of the same major or minor version.
-
Backup and restore tasks can run while the server is online. They can, however, have a significant impact on server performance.
For deployments with high performance requirements, consider dedicating a replica to perform only backup operations. This prevents other replicas from stealing cycles to back up data that could otherwise be used to serve client applications.
-
When you restore replicated data from backup, the replication protocol brings the replica up to date with others after the restore operation.
This requires, however, that the backup is recent enough. Backup files older than the replication purge delay (default: 3 days) are stale and should be discarded.
-
Directory data replication ensures that all servers converge on the latest data. If your data is affected by a serious accidental deletion or change, you must restore the entire directory service to an earlier state.
For details, refer to Recover from user error.
-
When you restore encrypted data, the server must have the same shared master key as the server that performed the backup.
Otherwise, the directory server cannot decrypt the symmetric key used to decrypt the data. For details, refer to Data encryption.
-
For portability across versions, and to save directory data in text format, periodically export directory data to LDIF.
The LDIF serves as an alternative backup format. In a disaster recovery situation, restore directory data by importing the version saved in LDIF.
LDIF stores directory data in text format. It offers no protection of the data.
Use an external tool to encrypt the LDIF you export to protect against data leaks and privacy breaches.
If you have stored passwords with a reversible encryption password storage scheme, be aware that the server must have the same shared master key as the server that encrypted the password.
For details, refer to Import and export, and Manual initialization.
-
You can perform a file system backup of your servers instead of using the server tools.
You must, however, stop the server before taking a file system backup. Running DS directory servers cannot guarantee that database backends will be recoverable unless you back them up with the DS tools.
Monitoring and auditing
When monitoring DS servers and auditing access, be aware that you can obtain some but not all data remotely.
The following data sources allow remote monitoring:
-
HTTP connection handlers expose a
/metrics/apiendpoint that offers RESTful access to monitoring data, and a/metrics/prometheusendpoint for Prometheus monitoring software.For details, refer to Use administrative APIs.
-
LDAP connection handlers expose a
cn=monitorbranch that offers LDAP access to monitoring data.For details, refer to LDAP-based monitoring.
-
JMX connection handlers offer remote access.
For details, refer to JMX-based monitoring.
-
SNMP connection handlers enable remote access.
For details, refer to SNMP-based monitoring.
-
You can configure alerts to be sent over JMX or SMTP (mail).
For details, refer to Alerts.
-
Replication conflicts are found in the directory data.
For details, refer to Replication conflicts.
-
Server tools, such as the
statuscommand, can run remotely.For details, refer to Status and tasks.
The following data sources require access to the server system:
-
Server logs, as described in Logging.
DS servers write log files to local disk subsystems. In your deployment, plan to move access logs that you want to retain. Otherwise, the server eventually removes logs according to its retention policy to avoid filling up the disk.
-
Index verification output and statistics, as described in Rebuild indexes, and Verify indexes.
When defining how to monitor the service, use the following guidelines:
-
Your service level objectives (SLOs) should reflect what your stakeholders expect from the directory service for their key client applications.
If SLOs reflect what stakeholders expect, and you monitor them in the way key client applications would experience them, your monitoring system can alert operational staff when thresholds are crossed, before the service fails to meet SLOs.
-
Make sure you keep track of resources that can expire, such as public key certificates and backup files from directory server replicas, and resources that can run out, such as system memory and disk space.
-
Monitor system and network resources in addition to the directory service.
Make sure operational staff can find and fix problems with the system or network, not only the directory.
-
Monitor replication delay, so you can take action when it remains high and continues to increase over the long term.
In order to analyze server logs, use other software, such as Splunk, which indexes machine-generated logs for analysis.
If you require integration with an audit tool, plan the tasks of setting up logging to work with the tool, and analyzing and monitoring the data once it has been indexed. Consider how you must retain and rotate log data once it has been consumed, as a high-volume service can produce large volumes of log data.
Hardening and security
When you first set up DS servers with the evaluation profile, the configuration favors ease of use over security for Example.com data.
All other configurations and setup profiles leave the server hardened for more security by default. You explicitly grant additional access if necessary.
For additional details, refer to Security.
Tests
In addition to planning tests for each custom plugin, test each feature you deploy. Perform functional and non-functional testing to validate that the directory service meets SLOs under load in realistic conditions. Include acceptance tests for the actual deployment. The data from the acceptance tests help you to make an informed decision about whether to go ahead with the deployment or to roll back.
Functional tests
Functional testing validates that specified test cases work with the software considered as a black box.
As ForgeRock already tests DS servers and gateways functionally, focus your functional testing on customization and service level functions. For each key capability, devise automated functional tests. Automated tests make it easier to integrate new deliveries to take advantage of recent bug fixes, and to check that fixes and new features do not cause regressions.
As part of the overall plan, include not only tasks to develop and maintain your functional tests, but also to provision and to maintain a test environment in which you run the functional tests before you significantly change anything in your deployment. For example, run functional tests whenever you upgrade any server or custom component, and analyze the output to understand the effect on your deployment.
Performance tests
With written SLOs, even if your first version consists of guesses, you turn performance plans from an open-ended project to a clear set of measurable goals for a manageable project with a definite outcome. Therefore, start your testing with service level objectives clear definitions of success.
Also, start your testing with a system for load generation that can reproduce the traffic you expect in production, and underlying systems that behave as you expect in production. To run your tests, you must therefore generate representative load data and test clients based on what you expect in production. You can then use the load generation system to perform iterative performance testing.
Iterative performance testing consists of identifying underperformance, and the bottlenecks that cause it, and discovering ways to eliminate or work around those bottlenecks. Underperformance means that the system under load does not meet service level objectives. Sometimes resizing or tuning the system can help remove bottlenecks that cause underperformance.
Based on SLOs and availability requirements, define acceptance criteria for performance testing, and iterate until you have eliminated performance bottlenecks.
Tools for running performance testing include the tools listed in Performance tests, and Gatling, which uses a domain-specific language for load testing. To mimic the production load, examine the access patterns, and the data that DS servers store. The representative load should reflect the distribution of client access expected in production.
Although you cannot use actual production data for testing, you can generate similar test data using tools,
such as the makeldif command.
As part of the overall plan, include tasks to:
-
Develop and maintain performance tests.
-
Provision and maintain a pre-production test environment that mimics your production environment.
Security measures in your test environment must mimic your production environment. Security measures can affect performance.
Once you are satisfied that the baseline performance is acceptable, run performance tests again when something in your deployment changes significantly with respect to performance. For example, if the load or number of clients changes significantly, it could raise performance requirements. Also, consider the thresholds that you can monitor in the production system to estimate when your system might no longer meet performance requirements.
Deployment tests
Here, deployment testing is a description rather than a term. It refers to the testing implemented within the deployment window after the system is deployed to the production environment, but before client applications and users access the system.
Plan for minimal changes between the pre-production test environment and the actual production environment. Then test that those changes have not cause any issues, and that the system generally behaves as expected.
Take the time to agree upfront with stakeholders regarding the acceptance criteria for deployment tests. When the production deployment window is small, and you have only a short time to deploy and test the deployment, you must trade off thorough testing for adequate testing. Make sure to plan enough time in the deployment window for performing the necessary tests and checks.
Include preparation for this exercise in your overall plan, as well as time to check the plans close to the deployment date.
Configuration changes
Make sure your plan defines the change control process for configuration. Identify the ways that the change is likely to affect your service. Validate your expectations with appropriate functional, integration, and stress testing. The goal is to adapt how you maintain the service before, during, and after the change. Complete your testing before you subject all production users to the change.
Review the configuration options described here, so that you know what to put under change control.
Server configuration
DS servers store configuration in files under the server’s config directory.
When you set up a server, the setup process creates the initial configuration files
based on templates in the server’s template directory.
File layout describes the files.
When a server starts, it reads its configuration files to build an object view of the configuration in memory. This view holds the configuration objects, and the constraints and relationships between objects. This view of the configuration is accessible over client-side and server-side APIs. Configuration files provide a persistent, static representation of the configuration objects.
Configuration tools use the client-side API to discover the server configuration and to check for constraint violations and missing relationships. The tools prevent you from breaking the server configuration structurally by validating structural changes before applying them. The server-side API allows the server to validate configuration changes, and to synchronize the view of the configuration in memory with the file representation on disk. If you make changes to the configuration files on disk while the server is running, the server can neither validate the changes beforehand, nor guarantee that they are in sync with the view of the configuration in memory.
| Method | Notes |
|---|---|
Tools ( |
Stable, supported, public interfaces for editing server configurations. Most tools work with local and remote servers, both online and offline. |
Files |
Internal interface to the server configuration, subject to change without warning in any release. If you must make manual changes to configuration files, always stop the DS server before editing the files. If the changes break the configuration, compare with the |
REST (HTTP) API |
Internal interface to the server configuration, subject to change without warning in any release. Useful for enabling browser-based access to the configuration. |
Once a server begins to replicate data with other servers, the part of the configuration pertaining to replication is specific to that server. As a result, a server effectively cannot be cloned once it has begun to participate in data replication. When deploying servers, do not initialize replication until you have deployed the server.
Documentation
The DS product documentation is written for readers like you, who are architects and solution developers, as well as for DS developers and for administrators who have had DS training. The people operating your production environment need concrete documentation specific to your deployed solution, with an emphasis on operational policies and procedures.
Procedural documentation can take the form of a runbook with procedures that emphasize maintenance operations, such as backup, restore, monitoring and log maintenance, collecting data pertaining to an issue in production, replacing a broken server or web application, responding to a monitoring alert, and so forth. Make sure you document procedures for taking remedial action in the event of a production issue.
Furthermore, to ensure that everyone understands your deployment and to speed problem resolution in the event of an issue, changes in production must be documented and tracked as a matter of course. When you make changes, always prepare to roll back to the previous state if the change does not perform as expected.
Maintenance and support
If you own the architecture and planning, but others own the service in production, or even in the labs, then you must plan coordination with those who own the service.
Start by considering the service owners' acceptance criteria. If they have defined support readiness acceptance criteria, you can start with their acceptance criteria. You can also ask yourself the following questions:
-
What do they require in terms of training in DS software?
-
What additional training do they require to support your solution?
-
Do your plans for documentation and change control, as described in Documentation, match their requirements?
-
Do they have any additional acceptance criteria for deployment tests, as described in Deployment tests?
Also, plan back line support with ForgeRock or a qualified partner. The aim is to define clearly who handles production issues, and how production issues are escalated to a product specialist if necessary.
Include a task in the overall plan to define the hand off to production, making sure there is clarity on who handles monitoring and issues.
Rollout
In addition to planning for the hand off of the production system, also prepare plans to roll out the system into production. Rollout into production calls for a well-choreographed operation, so these are likely the most detailed plans.
Take at least the following items into account when planning the rollout:
-
Availability of all infrastructure that DS software depends on, such as the following:
-
Server hosts and operating systems
-
Web application containers for gateways
-
Network links and configurations
-
Persistent data storage
-
Monitoring and audit systems
-
-
Installation for all DS servers.
-
Final tests and checks.
-
Availability of the personnel involved in the rollout.
In your overall plan, leave time and resources to finalize rollout plans toward the end of the project.
Ongoing change
To succeed, your directory service must adapt to changes, some that you can predict, some that you cannot.
In addition to the configuration changes covered in Configuration changes, predictable changes include the following:
- Increases and decreases in use of the service
-
For many deployments, you can predict changes in the use of the directory service, and in the volume of directory data.
If you expect cyclical changes, such as regular batch jobs for maintenance or high traffic at particular times of the year, test and prepare for normal and peak use of the service. For deployments where the peaks are infrequent but much higher than normal, it may be cost effective to dedicate replicas for peak use that are retired in normal periods.
If you expect use to increase permanently, then decide how much headroom you must build into the deployment. Plan to monitor progress and add capacity as necessary to maintain headroom, and to avoid placing DS servers under so much stress that they stop performing as expected.
If you expect use to decrease permanently, at some point you will retire the directory service. Make sure all stakeholders have realistic migration plans, and that their schedules match your schedule for retirement.
Depending on the volume of directory data and the growth you expect for the directory service, you may need to plan for scalability beyond your initial requirements.
As described in Scaling replication, you can increase read performance by adding servers. To increase write performance, first try more powerful servers and faster storage.
Single directory services can support thousands of replicated write operations per second, meaning millions of write operations per hour. It may well be possible to achieve appropriate performance by deploying on more powerful servers, and by using higher performance components, such as dedicated SSD disks instead of traditional disks.
When scaling up the systems is not enough, you must instead organize the DIT to replicate different branches separately. Deploy the replicas for each branch on sets of separate systems. For details, refer to High scalability.
- Directory service upgrades
-
ForgeRock regularly offers new releases of DS software. These include maintenance and feature releases. Supported customers may also receive patch releases for particular issues.
Patch and maintenance releases are generally fully compatible. Plan to test and roll out patch and maintenance releases swiftly, as they include important updates such as fixes for security issues or bugs that you must address quickly.
Plan to evaluate feature releases as they occur. Even if you do not intend to use new features immediately, you might find important improvements that you should roll out. Furthermore, by upgrading regularly you apply fewer changes at a time than you would by waiting until the end of support life and then performing a major upgrade.
- Key rotation
-
Even if you do not change the server configuration, the signatures eventually expire on certificates used to secure connections. You must at minimum replace the certificates. You could also change the key pair in addition to getting a new certificate.
If you encrypt directory data for confidentiality, you might also choose to rotate the symmetric encryption key.
Unpredictable changes include the following:
- Disaster recovery
-
As described in High availability, assess the risks. In light of the risks, devise and test disaster recovery procedures.
For details, refer to Disaster recovery.
- New security issues
-
Time and time again, security engineers have found vulnerabilities in security mechanisms that could be exploited by attackers. Expect this to happen during the lifetime of your deployment.
You might need to change the following at any time:
-
Keys used to secure connections
-
Keys used to encrypt directory data
-
Protocol versions used to secure connections
-
Password storage schemes
-
Deployed software that has a newly discovered security bug
-
In summary, plan to adapt your service to changing conditions. To correct security bugs and other issues and to recover from minor or major disasters, be prepared to patch, upgrade, roll out, and roll back changes as part of your regular operations.