Indexes
About indexes
A basic, standard directory feature is the ability to respond quickly to searches.
An LDAP search specifies the information that directly affects how long the directory might take to respond:
-
The base DN for the search.
The more specific the base DN, the less information to check during the search. For example, a request with base DN
dc=example,dc=compotentially involves checking many more entries than a request with base DNuid=bjensen,ou=people,dc=example,dc=com. -
The scope of the search.
A subtree or one-level scope targets many entries, whereas a base search is limited to one entry.
-
The search filter to match.
A search filter asserts that for an entry to match, it has an attribute that corresponds to some value. For example,
(cn=Babs Jensen)asserts thatcnmust have a value that equalsBabs Jensen.A directory server would waste resources checking all entries for a match. Instead, directory servers maintain indexes to expedite checking for a match.
LDAP directory servers disallow searches that cannot be handled expediently using indexes. Maintaining appropriate indexes is a key aspect of directory administration.
Role of an index
The role of an index is to answer the question, "Which entries have an attribute with this corresponding value?"
Each index is therefore specific to an attribute.
Each index is also specific to the comparison implied in the search filter. For example, a directory server maintains distinct indexes for exact (equality) matching and for substring matching. The types of indexes are explained in Index types. Furthermore, indexes are configured in specific directory backends.
Index implementation
An index is implemented as a tree of key-value pairs.
The key is a form of the value to match, such as babs jensen.
The value is a list of IDs for entries that match the key.
The figure that follows shows an equality (case ignore exact match) index with five keys from a total of four entries.
If the data set were large, there could be more than one entry ID per key:
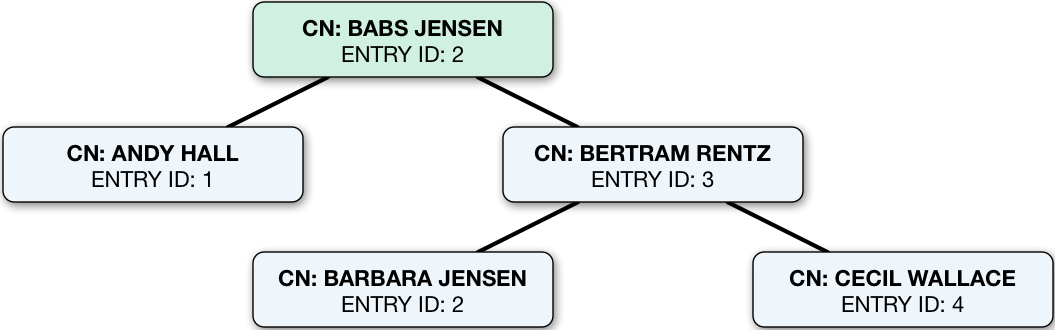
How DS uses indexes
This example illustrates how DS uses an index.
When the search filter is (cn=Babs Jensen), DS retrieves the IDs for entries whose CN matches Babs Jensen
by looking them up in the equality index of the CN attribute.
(For a complex filter, it might optimize the search by changing the order in which it uses the indexes.)
A successful result is zero or more entry IDs.
These are the candidate result entries.
For each candidate, DS retrieves the entry by ID from a system index called id2entry.
As its name suggests, this index returns an entry for an entry ID.
If there is a match, and the client application has the right to access to the data,
DS returns the search result.
It continues this process until no candidates are left.
Unindexed searches
If there are no indexes that correspond to a search request, DS must check for a match against every entry in the scope of the search. Evaluating every entry for a match is referred to as an unindexed search.
An unindexed search is an expensive operation, particularly for large directories.
A server refuses unindexed searches unless the user has specific permission to make such requests.
The permission to perform an unindexed search is granted with the unindexed-search privilege.
This privilege is reserved for the directory superuser by default.
It should not be granted lightly.
If the number of entries is smaller than the default resource limits,
you can still perform what appear to be unindexed searches,
meaning searches with filters for which no index appears to exist.
That is because the dn2id index returns all user data entries
without hitting a resource limit that would make the search unindexed.
Use cases that may call for unindexed searches include the following:
-
An application must periodically retrieve a very large amount of directory data all at once through an LDAP search.
For example, an application performs an LDAP search to retrieve everything in the directory once a week as part of a batch job that runs during off hours.
Make sure the application has no resource limits. For details, see Resource limits.
-
A directory data administrator occasionally browses directory data through a graphical UI without initially knowing what they are looking for or how to narrow the search.
Big indexes let you work around this problem. They facilitate searches where large numbers of entries match. For example, big indexes can help when paging through all the employees in the large company, or all the users in the state of California. For details, see Big index and Indexes for attributes with few unique values.
Alternatively, DS directory servers can use an appropriately configured VLV index to sort results for an unindexed search. For details, see VLV for paged server-side sort.
Index updates
When an entry is added, changed, or deleted, the directory server updates each affected index to reflect the change. This happens while the server is online, and has a cost. This cost is the reason to maintain indexes only those indexes that are used.
DS only updates indexes for the attributes that change. Updating an unindexed attribute is therefore faster than updating an indexed attribute.
What to index
DS directory server search performance depends on indexes. The default settings are fine for evaluating DS software, and they work well with sample data. The default settings do not necessarily fit your directory data, and the searches your applications perform:
-
Configure necessary indexes for the searches you anticipate.
-
Let DS optimize search queries to use whatever indexes are available.
DS servers may use a presence index when an equality index is not available, for example.
-
Use metrics and index debugging to check that searches use indexes and are optimized.
You cannot configure the optimizations DS servers perform. You can, however, review search metrics, logs, and search debugging data to verify that searches use indexes and are optimized.
-
Monitor DS servers for indexes that are not used.
Necessary indexes
Index maintenance has its costs. Every time an indexed attribute is updated, the server must update each affected index to reflect the change. This is wasteful if the index is not used. Indexes, especially substring indexes, can occupy more memory and disk space than the corresponding data.
Aim to maintain only indexes that speed up appropriate searches, and that allow the server to operate properly. The former indexes depend on how directory users search, and require thought and investigation. The latter includes non-configurable internal indexes, that should not change.
Begin by reviewing the attributes of your directory data. Which attributes would you expect to see in a search filter? If an attribute is going to show up frequently in reasonable search filters, then index it.
Compare your guesses with what you see actually happening in the directory.
Unindexed searches
Directory users might complain their searches fail because they’re unindexed.
By default, DS directory servers reject unindexed searches
with a result code of 50 and additional information about the unindexed search.
The following example attempts, anonymously, to get the entries for all users whose email address ends in .com:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=user.0,ou=People,dc=example,dc=com \
--bindPassword password \
--baseDN ou=people,dc=example,dc=com \
"(&(mail=*.com)(objectclass=person))"
# The LDAP search request failed: 50 (Insufficient Access Rights)
# Additional Information: You do not have sufficient privileges to perform an unindexed searchIf they’re unintentionally requesting an unindexed search, suggest ways to perform an indexed search instead. Perhaps the application needs a better search filter. Perhaps it requests more results than necessary. For example, a GUI application lets a user browse directory entries. The application could page through the results, rather than attempting to retrieve all the entries at once. To let the user page back and forth through the results, you could add a browsing (VLV) index for the application to get the entries for the current screen.
An application might have a good reason to get the full list of all entries in one operation.
If so, assign the application’s account the unindexed-search privilege.
Consider other options before you grant the privilege, however.
Unindexed searches cause performance problems for concurrent directory operations.
When an application has the privilege or binds with directory superuser credentials—by default,
the uid=admin DN and password—then DS does not reject its request for an unindexed search.
Check for unindexed searches using the ds-mon-backend-filter-unindexed monitoring attribute:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-backend-db)" ds-mon-backend-filter-unindexedIf ds-mon-backend-filter-unindexed is greater than zero, review the access log for unexpected unindexed searches.
The following example shows the relevant fields in an access log message:
{
"request": {
"protocol": "LDAP",
"operation": "SEARCH"
},
"response": {
"detail": "You do not have sufficient privileges to perform an unindexed search",
"additionalItems": {
"unindexed": null
}
}
}Beyond the key fields shown in the example, messages in the access log also specify the search filter and scope. Understand the operation that led to each unindexed search. If the filter is appropriate and often used, add an index to ease the search. Either analyze the access logs to find how often operations use the search filter or monitor operations with the index analysis feature, described in Index analysis metrics.
In addition to responding to client search requests, a server performs internal searches. Internal searches let the server retrieve data needed for a request, and maintain internal state information. Sometimes, internal searches become unindexed. When this happens, the server logs a warning similar to the following:
The server is performing an unindexed internal search request with base DN '%s', scope '%s', and filter '%s'. Unindexed internal searches are usually unexpected and could impact performance. Please verify that that backend's indexes are configured correctly for these search parameters.
When you see a message like this in the server log, take these actions:
-
Figure out which indexes are missing, and add them.
For details, see Index analysis metrics, Debug search indexes, and Configure indexes.
-
Check the integrity of the indexes.
For details, see Verify indexes.
-
If the relevant indexes exist, and you have verified that they are sound, the index entry limit might be too low.
This can happen, for example, in directory servers with more than 4000 groups in a single backend. For details, see Index entry limits.
-
If you have made the changes described in the steps above, and problem persists, contact technical support.
Index analysis metrics
DS servers provide the index analysis feature to collect information about filters in search requests. This feature is useful, but not recommend to keep enabled on production servers, as DS maintains the metrics in memory.
You can activate the index analysis mechanism using the dsconfig set-backend-prop command:
$ dsconfig \
set-backend-prop \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--set index-filter-analyzer-enabled:true \
--no-prompt \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pinThe command causes the server to analyze filters used, and to keep the results in memory. You can read the results as monitoring information:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=admin \
--bindPassword password \
--baseDN ds-cfg-backend-id=dsEvaluation,cn=Backends,cn=monitor \
--searchScope base \
"(&)" \
ds-mon-backend-filter-use-start-time ds-mon-backend-filter-use-indexed ds-mon-backend-filter-use-unindexed ds-mon-backend-filter-use
dn: ds-cfg-backend-id=dsEvaluation,cn=backends,cn=monitor
ds-mon-backend-filter-use-start-time: <timestamp>
ds-mon-backend-filter-use-indexed: 2
ds-mon-backend-filter-use-unindexed: 3
ds-mon-backend-filter-use: {"search-filter":"(employeenumber=86182)","nb-hits":1,"latest-failure-reason":"caseIgnoreMatch index type is disabled for the employeeNumber attribute"}The ds-mon-backend-filter-use values include the following fields:
search-filter-
The LDAP search filter.
nb-hits-
The number of times the filter was used.
latest-failure-reason-
A message describing why the server could not use any index for this filter.
The output can include filters for internal use, such as (aci=*).
In the example above, you see a filter used by a client application.
In the example, a search filter that led to an unindexed search, (employeenumber=86182), had no matches
because, "caseIgnoreMatch index type is disabled for the employeeNumber attribute".
Some client application has tried to find users by employee number, but no index exists for that purpose.
If this appears regularly as a frequent search, add an employee number index.
To avoid impacting server performance, turn off index analysis after you collect the information you need.
Use the dsconfig set-backend-prop command:
$ dsconfig \
set-backend-prop \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--set index-filter-analyzer-enabled:false \
--no-prompt \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pinDebug search indexes
Sometimes it is not obvious by inspection how a directory server processes a given search request.
The directory superuser can gain insight with the debugsearchindex attribute.
The default global access control prevents users from reading the debugsearchindex attribute.
To allow an administrator to read the attribute, add a global ACI such as the following:
$ dsconfig \
set-access-control-handler-prop \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--add global-aci:"(targetattr=\"debugsearchindex\")(version 3.0; acl \"Debug search indexes\"; \
allow (read,search,compare) userdn=\"ldap:///uid=user.0,ou=people,dc=example,dc=com\";)" \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-prompt|
The format of The values are intended to be read by human beings, not scripts.
If you do write scripts that interpret |
The debugsearchindex attribute value indicates how the server would process the search.
The server use its indexes to prepare a set of candidate entries.
It iterates through the set to compare candidates with the search filter, returning entries that match.
The following example demonstrates this feature for a subtree search with a complex filter:
Show details
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=user.0,ou=people,dc=example,dc=com \
--bindPassword password \
--baseDN dc=example,dc=com \
"(&(objectclass=person)(givenName=aa*))" \
debugsearchindex | sed -n -e "s/^debugsearchindex: //p"
{
"baseDn": "dc=example,dc=com",
"scope": "sub",
"filter": "(&(givenName=aa*)(objectclass=person))",
"maxCandidateSize": 100000,
"strategies": [
{
"name": "BaseObjectSearchStrategy",
"diagnostic": "not applicable"
},
{
"name": "VlvSearchStrategy",
"diagnostic": "not applicable"
},
{
"name": "AttributeIndexSearchStrategy",
"filter": {
"query": "INTERSECTION",
"rank": "RANGE_MATCH",
"filter": "(&(givenName=aa*)(objectclass=person))",
"subQueries": [
{
"query": "ANY_OF",
"rank": "RANGE_MATCH",
"filter": "(givenName=aa*)",
"subQueries": [
{
"query": "ANY_OF",
"rank": "RANGE_MATCH",
"filter": "(givenName=aa*)",
"subQueries": [
{
"query": "RANGE_MATCH",
"rank": "RANGE_MATCH",
"index": "givenName.caseIgnoreMatch",
"range": "[aa,ab[",
"diagnostic": "indexed",
"candidates": 50
},
{
"query": "RANGE_MATCH",
"rank": "RANGE_MATCH",
"index": "givenName.caseIgnoreSubstringsMatch:6",
"range": "[aa,ab[",
"diagnostic": "skipped"
}
],
"diagnostic": "indexed",
"candidates": 50
},
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(givenName=aa*)",
"index": "givenName.presence",
"diagnostic": "skipped"
}
],
"diagnostic": "indexed",
"candidates": 50,
"retained": 50
},
{
"query": "ANY_OF",
"rank": "OBJECT_CLASS_EQUALITY_MATCH",
"filter": "(objectclass=person)",
"subQueries": [
{
"query": "OBJECT_CLASS_EQUALITY_MATCH",
"rank": "OBJECT_CLASS_EQUALITY_MATCH",
"filter": "(objectclass=person)",
"subQueries": [
{
"query": "EXACT_MATCH",
"rank": "EXACT_MATCH",
"index": "objectClass.objectIdentifierMatch",
"key": "person",
"diagnostic": "not indexed",
"candidates": "[LIMIT-EXCEEDED]"
},
{
"query": "EXACT_MATCH",
"rank": "EXACT_MATCH",
"index": "objectClass.objectIdentifierMatch",
"key": "2.5.6.6",
"diagnostic": "skipped"
}
],
"diagnostic": "not indexed",
"candidates": "[LIMIT-EXCEEDED]"
},
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(objectclass=person)",
"index": "objectClass.presence",
"diagnostic": "skipped"
}
],
"diagnostic": "not indexed",
"candidates": "[LIMIT-EXCEEDED]",
"retained": 50
}
],
"diagnostic": "indexed",
"candidates": 50
},
"scope": {
"type": "sub",
"diagnostic": "not indexed",
"candidates": "[NOT-INDEXED]",
"retained": 50
},
"diagnostic": "indexed",
"candidates": 50
}
],
"final": 50
}The filter in the example matches person entries whose given name starts with aa.
The search scope is not explicitly specified, so the scope defaults to the subtree including the base DN.
Notice that the debugsearchindex value has the following top-level fields:
-
(Optional)
"vlv"describes how the server uses VLV indexes.The VLV field is not applicable for this example, and so is not present.
-
"filter"describes how the server uses the search filter to narrow the set of candidates. -
"scope"describes how the server uses the search scope. -
"final"indicates the final number of candidates in the set.
In the output, notice that the server uses the equality and substring indexes to find candidate entries
whose given name starts with aa.
If the filter indicated given names containing aa, as in givenName=*aa*,
the server would rely only on the substring index.
Notice that the output for the (objectclass=person) portion of the filter shows "candidates": "[LIMIT-EXCEEDED]".
In this case, there are so many entries matching the value specified that the index is not useful
for narrowing the set of candidates.
The scope is also not useful for narrowing the set of candidates.
Ultimately, however, the givenName indexes help the server to narrow the set of candidates.
The overall search is indexed and the result is 50 matching entries.
The following example shows a subtree search for accounts with initials starting either with aa or with zz:
Show details
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--baseDN dc=example,dc=com \
--bindDN uid=user.0,ou=people,dc=example,dc=com \
--bindPassword password \
"(|(initials=aa*)(initials=zz*))" \
debugsearchindex | sed -n -e "s/^debugsearchindex: //p"
{
"baseDn": "dc=example,dc=com",
"scope": "sub",
"filter": "(|(initials=aa*)(initials=zz*))",
"maxCandidateSize": 100000,
"strategies": [
{
"name": "BaseObjectSearchStrategy",
"diagnostic": "not applicable"
},
{
"name": "VlvSearchStrategy",
"diagnostic": "not applicable"
},
{
"name": "AttributeIndexSearchStrategy",
"filter": {
"query": "UNION",
"rank": "MATCH_ALL",
"filter": "(|(initials=aa*)(initials=zz*))",
"subQueries": [
{
"query": "ANY_OF",
"rank": "MATCH_ALL",
"filter": "(initials=aa*)",
"subQueries": [
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(initials=aa*)",
"index": "initials.presence",
"diagnostic": "not indexed"
},
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(initials=aa*)",
"index": "initials.presence",
"diagnostic": "not indexed"
}
],
"diagnostic": "not indexed"
},
{
"query": "ANY_OF",
"rank": "MATCH_ALL",
"filter": "(initials=zz*)",
"subQueries": [
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(initials=zz*)",
"index": "initials.presence",
"diagnostic": "skipped"
},
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(initials=zz*)",
"index": "initials.presence",
"diagnostic": "skipped"
}
],
"diagnostic": "skipped"
}
],
"diagnostic": "not indexed"
},
"scope": {
"type": "sub",
"diagnostic": "not indexed",
"candidates": "[NOT-INDEXED]",
"retained": "[NOT-INDEXED]"
},
"diagnostic": "not indexed",
"candidates": "[NOT-INDEXED]"
},
{
"name": "BigIndexSearchStrategy",
"filter": {
"query": "UNION",
"rank": "MATCH_ALL",
"filter": "(|(initials=aa*)(initials=zz*))",
"subQueries": [
{
"query": "ANY_OF",
"rank": "MATCH_ALL",
"filter": "(initials=aa*)",
"subQueries": [
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(initials=aa*)",
"index": "initials.big.presence",
"diagnostic": "not supported"
},
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(initials=aa*)",
"index": "initials.big.presence",
"diagnostic": "not supported"
}
],
"diagnostic": "not indexed"
}
],
"diagnostic": "not indexed"
},
"diagnostic": "not indexed"
}
],
"final": "[NOT-INDEXED]"
}As shown in the output, the search is not indexed. To fix this, index the initials attribute:
$ dsconfig \
create-backend-index \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--index-name initials \
--set index-type:equality \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-prompt
$ rebuild-index \
--hostname localhost \
--port 4444 \
--bindDn uid=admin \
--bindPassword password \
--baseDn dc=example,dc=com \
--index initials \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pinAfter configuring and building the new index, try the same search again:
Show details
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--baseDN dc=example,dc=com \
--bindDN uid=user.0,ou=people,dc=example,dc=com \
--bindPassword password \
"(|(initials=aa*)(initials=zz*))" \
debugsearchindex | sed -n -e "s/^debugsearchindex: //p"
{
"baseDn": "dc=example,dc=com",
"scope": "sub",
"filter": "(|(initials=aa*)(initials=zz*))",
"maxCandidateSize": 100000,
"strategies": [
{
"name": "BaseObjectSearchStrategy",
"diagnostic": "not applicable"
},
{
"name": "VlvSearchStrategy",
"diagnostic": "not applicable"
},
{
"name": "AttributeIndexSearchStrategy",
"filter": {
"query": "UNION",
"rank": "RANGE_MATCH",
"filter": "(|(initials=aa*)(initials=zz*))",
"subQueries": [
{
"query": "ANY_OF",
"rank": "RANGE_MATCH",
"filter": "(initials=aa*)",
"subQueries": [
{
"query": "ANY_OF",
"rank": "RANGE_MATCH",
"filter": "(initials=aa*)",
"subQueries": [
{
"query": "RANGE_MATCH",
"rank": "RANGE_MATCH",
"index": "initials.caseIgnoreMatch",
"range": "[aa,ab[",
"diagnostic": "indexed",
"candidates": 378
},
{
"query": "RANGE_MATCH",
"rank": "RANGE_MATCH",
"index": "initials.caseIgnoreSubstringsMatch:6",
"range": "[aa,ab[",
"diagnostic": "skipped"
}
],
"diagnostic": "indexed",
"candidates": 378
},
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(initials=aa*)",
"index": "initials.presence",
"diagnostic": "skipped"
}
],
"diagnostic": "indexed",
"candidates": 378
},
{
"query": "ANY_OF",
"rank": "RANGE_MATCH",
"filter": "(initials=zz*)",
"subQueries": [
{
"query": "ANY_OF",
"rank": "RANGE_MATCH",
"filter": "(initials=zz*)",
"subQueries": [
{
"query": "RANGE_MATCH",
"rank": "RANGE_MATCH",
"index": "initials.caseIgnoreMatch",
"range": "[zz,z{[",
"diagnostic": "indexed",
"candidates": 26
},
{
"query": "RANGE_MATCH",
"rank": "RANGE_MATCH",
"index": "initials.caseIgnoreSubstringsMatch:6",
"range": "[zz,z{[",
"diagnostic": "skipped"
}
],
"diagnostic": "indexed",
"candidates": 26
},
{
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(initials=zz*)",
"index": "initials.presence",
"diagnostic": "skipped"
}
],
"diagnostic": "indexed",
"candidates": 26
}
],
"diagnostic": "indexed",
"candidates": 404
},
"scope": {
"type": "sub",
"diagnostic": "not indexed",
"candidates": "[NOT-INDEXED]",
"retained": 404
},
"diagnostic": "indexed",
"candidates": 404
}
],
"final": 404
}Notice that the server can narrow the list of candidates using the equality index you created. The server would require a substring index instead of an equality index if the filter were not matching initial strings.
If an index already exists, but you suspect it is not working properly, see Verify indexes.
Unused indexes
DS maintains metrics about index use. The metrics indicate how often an index was accessed since the DS server started.
The following examples demonstrate how to read the metrics for all monitored indexes:
-
LDAP
-
Prometheus
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=monitor \
--bindPassword password \
--baseDN cn=monitor \
"(objectClass=ds-monitor-backend-index)" ds-mon-index ds-mon-index-uses$ curl --cacert ca-cert.pem --user monitor:password https://localhost:8443/metrics/prometheus 2>/dev/null | grep index_usesIf the number of index uses is persistently zero, then you can eventually conclude the index is unused. Of course, it is possible that an index is needed, but has not been used since the last server restart. Be sure to sample often enough that you know the indexed is unused before taking action.
You can remove unused indexes with one of the following commands, depending on the type of index:
Index types
DS directory servers support multiple index types, each corresponding to a different type of search.
View what is indexed by using the backendstat list-indexes command.
For details about a particular index, you can use the backendstat dump-index command.
Presence index
A presence index matches an attribute that is present on the entry, regardless of the value.
By default, the aci attribute is indexed for presence:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=admin \
--bindPassword password \
--baseDN dc=example,dc=com \
"(aci=*)" \
aciA presence index takes up less space than other indexes. In a presence index, there is just one key with a list of IDs.
The following command examines the ACI presence index for a server configured with the evaluation profile:
$ stop-ds
$ backendstat \
dump-index \
--backendId dsEvaluation \
--baseDn dc=example,dc=com \
--indexName aci.presence
Key (len 1): PRESENCE
Value (len 3): [COUNT:2] 1 9
Total Records: 1
Total / Average Key Size: 1 bytes / 1 bytes
Total / Average Data Size: 3 bytes / 3 bytesIn this case, entries with ACI attributes have IDs 1 and 9.
Equality index
An equality index matches values that correspond exactly (generally ignoring case) to those in search filters. An equality index requires clients to match values without wildcards or misspellings:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=bjensen,ou=People,dc=example,dc=com \
--bindPassword hifalutin \
--baseDN dc=example,dc=com \
"(uid=bjensen)" \
mail
dn: uid=bjensen,ou=People,dc=example,dc=com
mail: bjensen@example.comAn equality index has one list of entry IDs for each attribute value.
Depending on the backend implementation, the keys in a case-insensitive index might not be strings.
For example, a key of 6A656E73656E could represent jensen.
The following command examines the SN equality index for a server configured with the evaluation profile:
$ stop-ds
$ backendstat \
dump-index \
--backendID dsEvaluation \
--baseDN dc=example,dc=com \
--indexName sn.caseIgnoreMatch | grep -A 1 "jensen$"
Key (len 6): jensen
Value (len 26): [COUNT:17] 18 31 32 66 79 94 133 134 150 5996 19415 32834 46253 59672 73091 86510 99929In this case, there are 17 entries that have an SN of Jensen.
Unless the keys are encrypted, the server can reuse an equality index for ordering and initial substring searches.
Approximate index
An approximate index matches values that "sound like" those provided in the filter.
An approximate index on sn lets client applications find people even when they misspell surnames:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=bjensen,ou=People,dc=example,dc=com \
--bindPassword hifalutin \
--baseDN dc=example,dc=com \
"(&(sn~=Jansen)(cn=Babs*))" \
cn
dn: uid=bjensen,ou=People,dc=example,dc=com
cn: Barbara Jensen
cn: Babs JensenAn approximate index squashes attribute values into a normalized form.
The following command examines an SN approximate index added to a server configured with the evaluation profile:
$ stop-ds
$ backendstat \
dump-index \
--backendID dsEvaluation \
--baseDN dc=example,dc=com \
--indexName sn.ds-mr-double-metaphone-approx | grep -A 1 "JNSN$"
Key (len 4): JNSN
Value (len 83): [COUNT:74] 18 31 32 59 66 79 94 133 134 150 5928 5939 5940 5941 5996 5997 6033 6034 19347 19358 19359 19360 19415 19416 19452 19453 32766 32777 32778 32779 32834 32835 32871 32872 46185 46196 46197 46198 46253 46254 46290 46291 59604 59615 59616 59617 59672 59673 59709 59710 73023 73034 73035 73036 73091 73092 73128 73129 86442 86453 86454 86455 86510 86511 86547 86548 99861 99872 99873 99874 99929 99930 99966 99967In this case, there are 74 entries that have an SN that sounds like Jensen.
Substring index
A substring index matches values that are specified with wildcards in the filter. Substring indexes can be expensive to maintain, especially for large attribute values:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=bjensen,ou=People,dc=example,dc=com \
--bindPassword hifalutin \
--baseDN dc=example,dc=com \
"(cn=Barb*)" \
cn
dn: uid=bfrancis,ou=People,dc=example,dc=com
cn: Barbara Francis
dn: uid=bhal2,ou=People,dc=example,dc=com
cn: Barbara Hall
dn: uid=bjablons,ou=People,dc=example,dc=com
cn: Barbara Jablonski
dn: uid=bjensen,ou=People,dc=example,dc=com
cn: Barbara Jensen
cn: Babs Jensen
dn: uid=bmaddox,ou=People,dc=example,dc=com
cn: Barbara MaddoxIn a substring index, there are enough keys to match any substring in the attribute values. Each key is associated with a list of IDs. The default maximum size of a substring key is 6 bytes.
The following command examines an SN substring index for a server configured with the evaluation profile:
$ stop-ds
$ backendstat \
dump-index \
--backendID dsEvaluation \
--baseDN dc=example,dc=com \
--indexName sn.caseIgnoreSubstringsMatch:6
...
Key (len 1): e
Value (len 25): [COUNT:22] ...
...
Key (len 2): en
Value (len 15): [COUNT:12] ...
...
Key (len 3): ens
Value (len 3): [COUNT:1] 147
Key (len 5): ensen
Value (len 10): [COUNT:9] 18 31 32 66 79 94 133 134 150
...
Key (len 6): jensen
Value (len 10): [COUNT:9] 18 31 32 66 79 94 133 134 150
...
Key (len 1): n
Value (len 35): [COUNT:32] ...
...
Key (len 2): ns
Value (len 3): [COUNT:1] 147
Key (len 4): nsen
Value (len 10): [COUNT:9] 18 31 32 66 79 94 133 134 150
...
Key (len 1): s
Value (len 13): [COUNT:12] 12 26 47 64 95 98 108 131 135 147 149 154
...
Key (len 2): se
Value (len 7): [COUNT:6] 52 58 75 117 123 148
Key (len 3): sen
Value (len 10): [COUNT:9] 18 31 32 66 79 94 133 134 150
...In this case, the SN value Jensen shares substrings with many other entries. The size of the lists and number of keys make a substring index much more expensive to maintain than other indexes. This is particularly true for longer attribute values.
Ordering index
An ordering index is used to match values for a filter that specifies a range.
For example, the ds-sync-hist attribute used by replication has an ordering index by default.
Searches on that attribute often seek entries with changes more recent than the last time a search was performed.
The following example shows a search that specifies a range on the SN attribute value:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=bjensen,ou=People,dc=example,dc=com \
--bindPassword hifalutin \
--baseDN dc=example,dc=com \
"(sn>=zyw)" \
sn
dn: uid=user.13401,ou=People,dc=example,dc=com
sn: Zywiel
dn: uid=user.26820,ou=People,dc=example,dc=com
sn: Zywiel
dn: uid=user.40239,ou=People,dc=example,dc=com
sn: Zywiel
dn: uid=user.53658,ou=People,dc=example,dc=com
sn: Zywiel
dn: uid=user.67077,ou=People,dc=example,dc=com
sn: Zywiel
dn: uid=user.80496,ou=People,dc=example,dc=com
sn: Zywiel
dn: uid=user.93915,ou=People,dc=example,dc=com
sn: ZywielIn this case, the server only requires an ordering index if it cannot reuse the (ordered) equality index instead. For example, if the equality index is encrypted, an ordering index must be maintained separately.
Big index
A big index is designed for attributes where many, many entries have the same attribute value.
This can happen for attributes whose values all belong to a known enumeration.
For example, if you have a directory service with an entry for each person in the United States,
the st (state) attribute is the same for more than 30 million Californians (st: CA).
With a regular equality index, a search for (st=CA) would be unindexed.
With a big index, the search is indexed, and optimized for paging through the results.
For an example, refer to Indexes for attributes with few unique values.
A big index can be easier to configure and to use than a virtual list view index. Consider big indexes when:
-
Many1 entries have the same value for a given attribute.
DS search performance with a big index is equivalent to search performance with a standard index. For attributes with only a few unique values, big indexes support much higher modification rates.
-
Modifications outweigh searches for the attribute.
When attributes have a wide range of possible values, favor standard indexes, except when the attribute is often the target of modifications, and only sometimes part of a search filter.
1 Many, but not all entries.
Do not create a big index for all values of the objectClass attribute, for example.
When all entries have the same value for an attribute, as is the case for objectClass: top,
indexes consume additional system resources and disk space with no benefit.
The DS server must still read every entry to return search results.
In practice, the upper limit is probably somewhat less than half the total entries.
In other words, if half the entries have the same value for an attribute,
it will cost more to maintain the big index than to evaluate all entries to find matches for the search.
Let such searches remain unindexed searches.
Virtual list view (browsing) index
A virtual list view (VLV) or browsing index is designed to help applications that list results. For example, a GUI application might let users browse through a list of users. VLVs help the server respond to clients that request server-side sorting of the search results.
VLV indexes correspond to particular searches. Configure your VLV indexes using the command line.
Indexing tools
| Command | Use this to… |
|---|---|
Drill down into the details and inspect index contents during debugging. |
|
Configure indexes, and change their settings. |
|
Build a new index. Rebuild an index after changing its settings, or if the index has errors. |
|
Check an index for errors if you suspect there’s a problem. |
Configure indexes
You modify index configurations by using the dsconfig command.
Configuration changes take effect after you rebuild the index with the new configuration,
using the rebuild-index command.
The dsconfig --help-database command lists subcommands
for creating, reading, updating, and deleting index configuration.
|
Indexes are per directory backend rather than per base DN. To maintain separate indexes for different base DNs on the same server, put the entries in different backends. |
Standard indexes
New index
The following example creates a new equality index for the description attribute:
$ dsconfig \
create-backend-index \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--index-name description \
--set index-type:equality \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptApproximate index
The following example adds an approximate index for the sn (surname) attribute:
$ dsconfig \
set-backend-index-prop \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--index-name sn \
--add index-type:approximate \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptApproximate indexes depend on the Double Metaphone matching rule.
Extensible match index
DS servers support matching rules defined in LDAP RFCs. They also define DS-specific extensible matching rules.
The following are DS-specific extensible matching rules:
- Name:
ds-mr-double-metaphone-approx -
Double Metaphone Approximate Match described at http://aspell.net/metaphone/. The DS implementation always produces a single value rather than one or possibly two values.
Configure approximate indexes as described in Approximate index.
For an example using this matching rule, see Approximate match.
- Name:
ds-mr-user-password-exact -
User password exact matching rule used to compare encoded bytes of two hashed password values for exact equality.
- Name:
ds-mr-user-password-equality -
User password matching rule implemented as the user password exact matching rule.
- Name:
partialDateAndTimeMatchingRule -
Partial date and time matching rule for matching parts of dates in time-based searches.
For an example using this matching rule, see Active accounts.
- Name:
relativeTimeOrderingMatch.gt -
Greater-than relative time matching rule for time-based searches.
For an example using this matching rule, see Active accounts.
- Name:
relativeTimeOrderingMatch.lt -
Less-than relative time matching rule for time-based searches.
For an example using this matching rule, see Active accounts.
The following example configures an extensible matching rule index
for "later than" and "earlier than" generalized time matching on the ds-last-login-time attribute:
$ dsconfig \
create-backend-index \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--set index-type:extensible \
--set index-extensible-matching-rule:1.3.6.1.4.1.26027.1.4.5 \
--set index-extensible-matching-rule:1.3.6.1.4.1.26027.1.4.6 \
--index-name ds-last-login-time \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptNotice that the index-extensible-matching-rule setting takes an OID, not the name of the matching rule.
Indexes for attributes with few unique values
As described in Big index, big indexes fit the case where many, many entries have the same attribute value.
The default DS evaluation profile generates 100,000 user entries with addresses in the United States,
so some st (state) attributes are shared by 4000 or more users.
With a regular equality index, searches for some states reach the index entry limit,
causing unindexed searches.
A big index avoids this problem.
The following commands configure an equality index for the state attribute, and then build the new index:
$ dsconfig \
create-backend-index \
--backend-name dsEvaluation \
--index-name st \
--set index-type:big-equality \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-prompt
$ rebuild-index \
--baseDn dc=example,dc=com \
--index st \
--hostname localhost \
--port 4444 \
--bindDn uid=admin \
--bindPassword password \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pinOnce the index is ready, a client application can page through all the users in a state with an indexed search:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDn uid=bjensen,ou=People,dc=example,dc=com \
--bindPassword hifalutin \
--baseDn dc=example,dc=com \
--simplePageSize 5 \
"(st=CA)" \
cn
dn: uid=user.9,ou=People,dc=example,dc=com
cn: Abbe Abbate
dn: uid=user.123,ou=People,dc=example,dc=com
cn: Aili Aksel
dn: uid=user.124,ou=People,dc=example,dc=com
cn: Ailina Akyurekli
dn: uid=user.132,ou=People,dc=example,dc=com
cn: Ainslee Alary
dn: uid=user.264,ou=People,dc=example,dc=com
cn: Alphen Angell
Press RETURN to continueWhen creating a big index that uses an extensible matching rule, model your work on the example in Extensible match index, but use the following options to set the index type and the matching rule:
-
--set index-type:big-extensible -
--set big-index-matching-rule:OIDNotice that the
big-index-matching-rulesetting takes an OID, not the name of the matching rule.The OID must specify an equality matching rule for big indexes. For example, if you create a big index for the
sn(surname) attribute withcaseIgnoreMatch, use--set big-index-matching-rule:2.5.13.2.
Custom indexes for JSON
DS servers support attribute values that have JSON syntax.
The following schema excerpt defines a json attribute with case-insensitive matching:
attributeTypes: ( json-attribute-oid NAME 'json'
SYNTAX 1.3.6.1.4.1.36733.2.1.3.1 EQUALITY caseIgnoreJsonQueryMatch
X-ORIGIN 'DS Documentation Examples' )When you index a JSON attribute defined in this way, the default directory server behavior is to maintain index keys for each JSON field. Large or numerous JSON objects can result in large indexes, which is wasteful. If you know which fields are used in search filters, you can choose to index only those fields.
As described in Schema and JSON, for some JSON objects only a certain field or fields matter when comparing for equality. In these special cases, the server can ignore other fields when checking equality during updates, and you would not maintain indexes for other fields.
How you index a JSON attribute depends on the matching rule in the attribute’s schema definition, and on the JSON fields you expect to be used as search keys for the attribute.
Index JSON attributes
The examples that follow demonstrate these steps:
-
Using the schema definition and the information in the following table, configure a custom schema provider for the attribute’s matching rule, if necessary.
Matching Rule in Schema Definition Fields in Search Filter Custom Schema Provider Required? caseExactJsonQueryMatchcaseIgnoreJsonQueryMatchAny JSON field
No
Custom JSON query matching rule
Specific JSON field or fields
Yes, see JSON query matching rule index
Custom JSON equality or ordering matching rule
Specific field(s)
Yes, see JSON equality matching rule index
A custom schema provider applies to all attributes using this matching rule.
-
Add the schema definition for the JSON attribute.
-
Configure the index for the JSON attribute.
-
Add the JSON attribute values in the directory data.
JSON query matching rule index
This example illustrates the steps in Index JSON attributes.
|
If you installed a directory server with the |
The following command configures a custom, case-insensitive JSON query matching rule.
This only maintains keys for the access_token and refresh_token fields:
$ dsconfig \
create-schema-provider \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--provider-name "Custom JSON Query Matching Rule" \
--type json-query-equality-matching-rule \
--set enabled:true \
--set case-sensitive-strings:false \
--set ignore-white-space:true \
--set matching-rule-name:caseIgnoreOAuth2TokenQueryMatch \
--set matching-rule-oid:1.3.6.1.4.1.36733.2.1.4.1.1 \
--set indexed-field:access_token \
--set indexed-field:refresh_token \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptThe following commands add schemas for a oauth2Token attribute that uses the matching rule:
$ ldapmodify \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=admin \
--bindPassword password << EOF
dn: cn=schema
changetype: modify
add: attributeTypes
attributeTypes: ( oauth2token-attribute-oid NAME 'oauth2Token'
SYNTAX 1.3.6.1.4.1.36733.2.1.3.1 EQUALITY caseIgnoreOAuth2TokenQueryMatch
SINGLE-VALUE X-ORIGIN 'DS Documentation Examples' )
-
add: objectClasses
objectClasses: ( oauth2token-attribute-oid NAME 'oauth2TokenObject' SUP top
AUXILIARY MAY ( oauth2Token ) X-ORIGIN 'DS Documentation Examples' )
EOFThe following command configures an index using the custom matching rule implementation:
$ dsconfig \
create-backend-index \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--index-name oauth2Token \
--set index-type:equality \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptFor an example of how a client application could use this index, see JSON query filters.
JSON equality matching rule index
This example illustrates the steps in Index JSON attributes.
|
If you installed a directory server with the |
The following command configures a custom, case-insensitive JSON equality matching rule, caseIgnoreJsonTokenIdMatch:
$ dsconfig \
create-schema-provider \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--provider-name "Custom JSON Token ID Matching Rule" \
--type json-equality-matching-rule \
--set enabled:true \
--set case-sensitive-strings:false \
--set ignore-white-space:true \
--set matching-rule-name:caseIgnoreJsonTokenIDMatch \
--set matching-rule-oid:1.3.6.1.4.1.36733.2.1.4.4.1 \
--set json-keys:id \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptNotice that this example defines a matching rule with OID 1.3.6.1.4.1.36733.2.1.4.4.1.
In production deployments, use a numeric OID allocated for your own organization.
The following commands add schemas for a jsonToken attribute,
where the unique identifier is in the "id" field of the JSON object:
$ ldapmodify \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=admin \
--bindPassword password << EOF
dn: cn=schema
changetype: modify
add: attributeTypes
attributeTypes: ( jsonToken-attribute-oid NAME 'jsonToken'
SYNTAX 1.3.6.1.4.1.36733.2.1.3.1 EQUALITY caseIgnoreJsonTokenIDMatch
SINGLE-VALUE X-ORIGIN 'DS Documentation Examples' )
-
add: objectClasses
objectClasses: ( json-token-object-class-oid NAME 'JsonTokenObject' SUP top
AUXILIARY MAY ( jsonToken ) X-ORIGIN 'DS Documentation Examples' )
EOFThe following command configures an index using the custom matching rule implementation:
$ dsconfig \
create-backend-index \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--index-name jsonToken \
--set index-type:equality \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-promptFor an example of how a client application could use this index, see JSON assertions.
Virtual list view index
The following example shows how to create a VLV index. This example applies where GUI users browse user accounts, sorting on surname then given name:
$ dsconfig \
create-backend-vlv-index \
--hostname localhost \
--port 4444 \
--bindDn uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--index-name people-by-last-name \
--set base-dn:ou=People,dc=example,dc=com \
--set filter:"(|(givenName=*)(sn=*))" \
--set scope:single-level \
--set sort-order:"+sn +givenName" \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-prompt|
When referring to a VLV index after creation, you must add |
VLV for paged server-side sort
A special VLV index lets the server return sorted results. For example, users page through an entire directory database in a GUI. The user does not filter the data before seeing what is available.
The VLV index must have the following characteristics:
-
Its filter must be "always true,"
(&). -
Its scope must cover the search scope of the requests.
-
Its base DN must match or be a parent of the base DN of the search requests.
-
Its sort order must match the sort keys of the requests in the order they occur in the requests, starting with the first sort key used in the request.
For example, if the sort order of the VLV index is
+l +sn +cn, then it works with requests having the following sort orders:-
+l +sn +cn -
+l +sn -
+l -
Or none for single-level searches.
The VLV index sort order can include additional keys not present in a request.
-
The following example commands demonstrate creating and using a VLV index to sort paged results
by locality, surname, and then full name.
The l attribute is not indexed by default.
This example makes use of the rebuild-index command described below.
The directory superuser is not subject to resource limits on the LDAP search operation:
$ dsconfig \
create-backend-vlv-index \
--hostname localhost \
--port 4444 \
--bindDn uid=admin \
--bindPassword password \
--backend-name dsEvaluation \
--index-name by-name \
--set base-dn:ou=People,dc=example,dc=com \
--set filter:"(&)" \
--set scope:subordinate-subtree \
--set sort-order:"+l +sn +cn" \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-prompt
$ rebuild-index \
--hostname localhost \
--port 4444 \
--bindDn uid=admin \
--bindPassword password \
--baseDn dc=example,dc=com \
--index vlv.by-name \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDn uid=admin \
--bindPassword password \
--baseDn dc=example,dc=com \
--sortOrder +l,+sn,+cn \
--simplePageSize 5 \
"(&)" \
cn l sn
dn: uid=user.93953,ou=People,dc=example,dc=com
cn: Access Abedi
l: Abilene
sn: Abedi
dn: uid=user.40283,ou=People,dc=example,dc=com
cn: Achal Abernathy
l: Abilene
sn: Abernathy
dn: uid=user.67240,ou=People,dc=example,dc=com
cn: Alaine Alburger
l: Abilene
sn: Alburger
dn: uid=user.26994,ou=People,dc=example,dc=com
cn: Alastair Alexson
l: Abilene
sn: Alexson
dn: uid=user.53853,ou=People,dc=example,dc=com
cn: Alev Allen
l: Abilene
sn: Allen
Press RETURN to continue ^CRebuild indexes
When you first import directory data, the directory server builds the indexes as part of the import process. DS servers maintain indexes automatically, updating them as directory data changes.
Only rebuild an index manually when it is necessary to do so. Rebuilding valid indexes wastes server resources, and is disruptive for client applications.
|
When you rebuild an index while the server is online, the index appears as degraded and unavailable while the server rebuilds it. A search request that relies on an index in this state may temporarily fail as an unindexed search. |
However, you must manually intervene when you:
-
Create a new index for a new directory attribute.
-
Create a new index for existing directory attribute.
-
Change the server configuration in a way that affects the index, for example, by changing Index entry limits.
-
Verify an existing index, and find that it has errors or is not in a valid state.
Automate index rebuilds
To automate the process of rebuilding indexes, use the --rebuildDegraded option.
This rebuilds only degraded indexes, and does not affect valid indexes:
$ rebuild-index \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--baseDN dc=example,dc=com \
--rebuildDegraded \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pinClear a new index for a new attribute
When you add a new attribute, as described in Update LDAP schema, and create an index for the new attribute, the new index appears as degraded or invalid. The attribute has not yet been used, and so the index is sure to be empty, not degraded.
In this case, you can safely use the rebuild-index --clearDegradedState command.
The server can complete this operation quickly,
because there is no need to scan the entire directory backend to rebuild a new, unused index.
In this example, an index has just been created for newUnusedAttribute.
If the newly indexed attribute has already been used, rebuild the index instead of clearing the degraded state.
Before using the rebuild-index command, test the index status to make sure is has not been used:
-
DS servers must be stopped before you use the backendstat command:
$ stop-dsbash -
Check the status of the index(es).
The indexes are prefixed with
!before the rebuild:$ backendstat \ show-index-status \ --backendID dsEvaluation \ --baseDN dc=example,dc=com \ | grep newUnusedAttribute ! newUnusedAttribute.caseIgnoreMatch ... ! newUnusedAttribute.caseIgnoreSubstringsMatch:6 ... ! newUnusedAttribute.presence ...bash -
Update the index information to fix the value of the unused index:
$ rebuild-index \ --offline \ --baseDN dc=example,dc=com \ --clearDegradedState \ --index newUnusedAttributebashAlternatively, you can first start the server, and perform this operation while the server is online.
-
(Optional) With the server offline, check that the
!prefix has disappeared:$ backendstat \ show-index-status \ --backendID dsEvaluation \ --baseDN dc=example,dc=com \ | grep newUnusedAttribute newUnusedAttribute.caseIgnoreMatch ... newUnusedAttribute.caseIgnoreSubstringsMatch:6 ... newUnusedAttribute.presence ...bash -
Start the server if you have not done so already:
$ start-dsbash
Rebuild an index
When you make a change that affects an index configuration, manually rebuild the index.
Individual indexes appear as degraded and are unavailable while the server rebuilds them. A search request that relies on an index in this state may temporarily fail as an unindexed search.
The following example rebuilds a degraded cn index immediately with the server online.
While the server is rebuilding the cn index, search requests that would normally succeed may fail:
$ rebuild-index \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--baseDN dc=example,dc=com \
--index cn \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pinAvoid rebuilding all indexes at once
Rebuilding multiple non-degraded indexes at once is disruptive, and not recommended unless some change has affected all indexes.
If you use the --rebuildAll option, first take the backend offline, stop the server,
or, at minimum, make sure that no applications connect to the server while it is rebuilding indexes.
Index entry limits
An index is a tree of key-value pairs. The key is what the search is trying to match. The value is a list of entry IDs.
As the number of entries in the directory grows, the list of entry IDs for some keys can become very large.
For example, every entry in the directory has objectClass: top.
If the directory maintains a substring index for mail, the number of entries ending in .com could be huge.
A directory server therefore defines an index entry limit. When the number of entry IDs for a key exceeds the limit, the server stops maintaining a list of IDs for that key. The limit effectively means a search using only that key is unindexed. Searches using other keys in the same index are not affected.
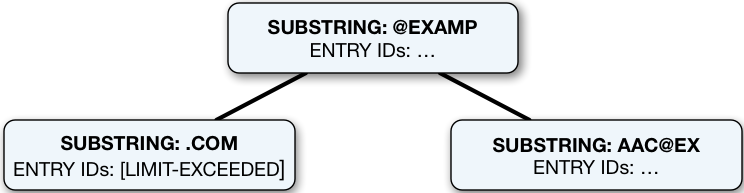
The following figure shows a fragment from a substring index for the mail attribute.
The number of email addresses ending in com has exceeded the index entry limit.
For the other substring keys, the entry ID lists are still maintained.
To save space, the entry IDs are not shown in the figure.
Ideally, the limit is set at the point where it becomes more expensive to maintain the entry ID list for a key, and to perform an indexed search than to perform an unindexed search. In practice, the limit is a tradeoff, with a default index entry limit value of 4000. Keep the default setting unless you have good reason to change it.
Check index entry limits
The following steps show how to get information about indexes where the index entry limit is exceeded for some keys. In this case, the directory server holds 100,000 user entries.
Use the backendstat show-index-status command:
-
Stop DS servers before you use the
backendstatcommand:$ stop-dsbash -
Non-zero values in the Over column of the output table indicate the number of keys for which the
index-entry-limitsetting has been exceeded. The keys that are over the limit are then listed below the table:$ backendstat show-index-status --backendID dsEvaluation --baseDN dc=example,dc=com Index Name ...Over Entry Limit... ------------------------------------------------------...-----------------... ... ... cn.caseIgnoreSubstringsMatch:6 ... 14 4000... ... ... givenName.caseIgnoreSubstringsMatch:6 ... 9 4000... ... ... mail.caseIgnoreIA5SubstringsMatch:6 ... 31 4000... ... ... objectClass.objectIdentifierMatch ... 4 4000... ... ... sn.caseIgnoreSubstringsMatch:6 ... 14 4000... ... ... telephoneNumber.telephoneNumberSubstringsMatch:6 ... 10 4000... ... Index: mail.caseIgnoreIA5SubstringsMatch:6 Over index-entry-limit keys: [.com] [0@exam] ... Index: cn.caseIgnoreSubstringsMatch:6 Over index-entry-limit keys: [a] [an] [e] [er] [i] [k] [l] [n] [o] [on] [r] [s] [t] [y] Index: givenName.caseIgnoreSubstringsMatch:6 Over index-entry-limit keys: [a] [e] [i] [ie] [l] [n] [na] [ne] [y] Index: telephoneNumber.telephoneNumberSubstringsMatch:6 Over index-entry-limit keys: [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] Index: sn.caseIgnoreSubstringsMatch:6 Over index-entry-limit keys: [a] [an] [e] [er] [i] [k] [l] [n] [o] [on] [r] [s] [t] [y] Index: objectClass.objectIdentifierMatch Over index-entry-limit keys: [inetorgperson] [organizationalperson] [person] [top]bashFor example, every user entry has the object classes listed, and every user entry has an email address ending in
.com, so those values are not specific enough to be used in search filters.A non-zero value in the Over column represents a tradeoff. As described above, this is usually a good tradeoff, not a problem to be solved.
For a detailed explanation of each column of the output, see backendstat show-index-status.
-
Start the server:
$ start-dsbash
On over index-entry-limit keys
The settings for this directory server are a good tradeoff.
Unless you are seeing many unindexed searches that specifically target keys in the Over index-entry-limit keys lists,
there’s no reason to change the index-entry-limit settings.
A search might be indexed even though some keys are over the limit.
For example, as shown above, the objectClass value inetorgperson is over the limit.
Yet, a search with a filter like (&(cn=Babs Jensen)(objectclass=inetOrgPerson)) is indexed:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=user.1,ou=people,dc=example,dc=com \
--bindPassword password \
--baseDN dc=example,dc=com \
"(&(cn=Babs Jensen)(objectclass=inetOrgPerson))" cn
dn: uid=bjensen,ou=People,dc=example,dc=com
cn: Barbara Jensen
cn: Babs JensenThe search is indexed because the equality index for cn is not over the limit,
so the search term (cn=Babs Jensen) is enough for DS to find a match using that index.
If you look at the debugsearchindex output,
you can see how DS uses the cn index, and skips the objectclass index.
The overall search is clearly indexed:
Show debugsearchindex output
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=admin \
--bindPassword password \
--baseDN dc=example,dc=com \
"(&(cn=Babs Jensen)(objectclass=inetOrgPerson))" \
debugsearchindex | sed -n -e "s/^debugsearchindex: //p"
{
"baseDn": "dc=example,dc=com",
"scope": "sub",
"filter": "(&(cn=Babs Jensen)(objectclass=inetOrgPerson))",
"maxCandidateSize": 100000,
"strategies": [{
"name": "BaseObjectSearchStrategy",
"diagnostic": "not applicable"
}, {
"name": "VlvSearchStrategy",
"diagnostic": "not applicable"
}, {
"name": "AttributeIndexSearchStrategy",
"filter": {
"query": "INTERSECTION",
"rank": "EXACT_MATCH",
"filter": "(&(cn=Babs Jensen)(objectclass=inetOrgPerson))",
"subQueries": [{
"query": "ANY_OF",
"rank": "EXACT_MATCH",
"filter": "(cn=Babs Jensen)",
"subQueries": [{
"query": "EXACT_MATCH",
"rank": "EXACT_MATCH",
"filter": "(cn=Babs Jensen)",
"index": "cn.caseIgnoreMatch",
"key": "babs jensen",
"diagnostic": "indexed",
"candidates": 1
}, {
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(cn=Babs Jensen)",
"index": "cn.presence",
"diagnostic": "skipped"
}],
"diagnostic": "indexed",
"candidates": 1,
"retained": 1
}, {
"query": "ANY_OF",
"rank": "OBJECT_CLASS_EQUALITY_MATCH",
"filter": "(objectclass=inetOrgPerson)",
"subQueries": [{
"query": "OBJECT_CLASS_EQUALITY_MATCH",
"rank": "OBJECT_CLASS_EQUALITY_MATCH",
"filter": "(objectclass=inetOrgPerson)",
"subQueries": [{
"query": "EXACT_MATCH",
"rank": "EXACT_MATCH",
"index": "objectClass.objectIdentifierMatch",
"key": "inetorgperson",
"diagnostic": "skipped"
}, {
"query": "EXACT_MATCH",
"rank": "EXACT_MATCH",
"index": "objectClass.objectIdentifierMatch",
"key": "2.16.840.1.113730.3.2.2",
"diagnostic": "skipped"
}],
"diagnostic": "skipped"
}, {
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(objectclass=inetOrgPerson)",
"index": "objectClass.presence",
"diagnostic": "skipped"
}],
"diagnostic": "skipped"
}],
"diagnostic": "indexed",
"candidates": 1
},
"diagnostic": "indexed",
"candidates": 1
}],
"final": 1
}Index entry limit changes
In rare cases, the index entry limit might be too low for a certain key. This could manifest itself as a frequent, useful search becoming unindexed with no reasonable way to narrow the search.
You can change the index entry limit on a per-index basis. Do not do this in production unless you can explain and show why the benefits outweigh the costs.
|
Changing the index entry limit significantly can result in serious performance degradation. Be prepared to test performance thoroughly before you roll out an index entry limit change in production. |
To configure the index-entry-limit for an index or a backend:
-
Use the
dsconfig set-backend-index-propcommand to change the setting for a specific backend index. -
(Not recommended) Use the
dsconfig set-backend-propcommand to change the setting for all indexes in the backend.
Verify indexes
You can verify that indexes correspond to current directory data, and do not contain errors. Use the verify-index command.
The following example verifies the cn index offline:
$ stop-ds
$ verify-index \
--baseDN dc=example,dc=com \
--index cn \
--clean \
--countErrorsThe output indicates whether any errors are found in the index.
Debug a missing index
This example explains how you, as directory administrator, investigate an indexing problem.
How it looks to the application
In this example, an LDAP client application helps people look up names using mobile telephone numbers.
The mobile numbers stored on the mobile attribute in the directory.
The LDAP client application sees a search for a mobile number failing with error 50:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=user.1,ou=people,dc=example,dc=com \
--bindPassword password \
--baseDN dc=example,dc=com \
"(mobile=14120300042)" cn
# The LDAP search request failed: 50 (Insufficient Access Rights)
# Additional Information: You do not have sufficient privileges to perform an unindexed searchThe application owner tells you there’s a problem searching on mobile numbers.
How it looks to the administrator
As administrator, you can see the failures in the DS access logs. The following example includes only the relevant fields of an access log message with the failure:
{
"request": {
"operation": "SEARCH",
"dn": "dc=example,dc=com",
"scope": "sub",
"filter": "(mobile=14120300042)"
},
"response": {
"status": "FAILED",
"statusCode": "50",
"detail": "You do not have sufficient privileges to perform an unindexed search",
"additionalItems": {
"unindexed": null
},
"nentries": 0
},
"userId": "uid=user.1,ou=People,dc=example,dc=com"
}For this simple filter, (mobile=14120300042), if the search is uninindexed,
you can conclude that the attribute must not be indexed.
As expected, the mobile attribute does not appear in the list of indexes for the backend:
$ dsconfig \
list-backend-indexes \
--backend-name dsEvaluation \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-prompt
Backend Index : index-type ...
---------------------------:------------------------...
aci : presence ...
cn : equality, substring ...
ds-certificate-fingerprint : equality ...
ds-certificate-subject-dn : equality ...
ds-sync-conflict : equality ...
ds-sync-hist : ordering ...
entryUUID : equality ...
givenName : equality, substring ...
json : equality ...
jsonToken : equality ...
mail : equality, substring ...
manager : equality, extensible ...
member : equality ...
oauth2Token : equality ...
objectClass : big-equality, equality ...
sn : equality, substring ...
telephoneNumber : equality, substring ...
uid : equality ...
uniqueMember : equality ...If the filter were more complex,
you could use run the search with the debugsearchindex attribute to determine why it is unindexed.
You notice that telephoneNumber has equality and substring indexes,
and decide to add the same for the mobile attribute.
Adding a new index means adding the configuration for the index, and then building the index.
An index is specific to a given server, so you do this for each DS replica.
For example:
$ dsconfig \
create-backend-index \
--backend-name dsEvaluation \
--index-name mobile \
--type generic \
--set index-type:equality \
--set index-type:substring \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--no-prompt
$ rebuild-index \
--index mobile \
--hostname localhost \
--port 4444 \
--bindDN uid=admin \
--bindPassword password \
--baseDN dc=example,dc=com \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pinHow the fix looks to the administrator
Once the index is built, you check that the search is now indexed by looking at the debugsearchindex output:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=admin \
--bindPassword password \
--baseDN dc=example,dc=com \
"(mobile=14120300042)" \
debugsearchindex | sed -n -e "s/^debugsearchindex: //p"
{
"baseDn": "dc=example,dc=com",
"scope": "sub",
"filter": "(mobile=14120300042)",
"maxCandidateSize": 100000,
"strategies": [{
"name": "BaseObjectSearchStrategy",
"diagnostic": "not applicable"
}, {
"name": "VlvSearchStrategy",
"diagnostic": "not applicable"
}, {
"name": "AttributeIndexSearchStrategy",
"filter": {
"query": "ANY_OF",
"rank": "EXACT_MATCH",
"filter": "(mobile=14120300042)",
"subQueries": [{
"query": "EXACT_MATCH",
"rank": "EXACT_MATCH",
"filter": "(mobile=14120300042)",
"index": "mobile.telephoneNumberMatch",
"key": "14120300042",
"diagnostic": "indexed",
"candidates": 1
}, {
"query": "MATCH_ALL",
"rank": "MATCH_ALL",
"filter": "(mobile=14120300042)",
"index": "mobile.presence",
"diagnostic": "skipped"
}],
"diagnostic": "indexed",
"candidates": 1
},
"diagnostic": "indexed",
"candidates": 1
}],
"final": 1
}You tell the application owner to try searching on mobile numbers now that you have indexed the attribute.
How the fix looks to the application
The client application now sees that the search works:
$ ldapsearch \
--hostname localhost \
--port 1636 \
--useSsl \
--usePkcs12TrustStore /path/to/opendj/config/keystore \
--trustStorePassword:file /path/to/opendj/config/keystore.pin \
--bindDN uid=user.1,ou=people,dc=example,dc=com \
--bindPassword password \
--baseDN dc=example,dc=com \
"(mobile=14120300042)" cn
dn: uid=user.0,ou=People,dc=example,dc=com
cn: Aaccf AmarMore to do?
Must you do anything more?
What about index-entry-limit settings, for example?
Stop the server, and run the backendstat show-index-status command:
$ stop-ds --quiet
$ backendstat show-index-status --backendID dsEvaluation --baseDN dc=example,dc=com
Index Name ... Over Entry Limit Mean ...
------------------------------------------...---------------------------...--
...
mobile.telephoneNumberMatch ... 0 4000 1 ...
mobile.telephoneNumberSubstringsMatch:6 ... 10 4000 2 ...
...
Index: mobile.telephoneNumberSubstringsMatch:6
Over index-entry-limit keys: [0] [1] [2] [3] [4] [5] [6] [7] [8] [9]
...Notice that the equality index mobile.telephoneNumberMatch
has no keys whose entry ID lists are over the limit, and the average number of values is 1.
This is what you would expect.
Each mobile number belongs to a single user.
DS uses this index for exact match search filters like (mobile=14120300042).
Notice also that the substring index mobile.telephoneNumberSubstringsMatch:6 has
10 keys whose lists are over the (default) limit of 4000 values.
These are the keys for substrings that match only a single digit of a mobile number.
For example, a search for all users whose mobile telephone number starts with 1 uses the filter (mobile=1*).
This search would be unindexed.
Should you raise the index-entry-limit for this substring index?
Probably not, no.
The filter (mobile=1*) matches all mobile numbers for the United States and Canada, for example.
Someone running this search is not looking up a user’s name by their mobile phone number.
They are scanning the directory database, even if it is not intentional.
If you raise the index-entry-limit setting to prevent any Over index-entry-limit keys,
the server must update enormous entry ID lists for these keys whenever a mobile attribute value changes.
The impact on write performance could be a bad tradeoff.
If possible, suggest that the LDAP application refrains from searching until the user has provided enough digits of the mobile number to match, or that it prompts the user for more digits when it encounters an unindexed search.
If you cannot change the application,
it might be acceptable that searches for a single mobile telephone digit simply fail.
That might be a better tradeoff than impacting write performance due to a very high index-entry-limit setting.