Deployment patterns
Use these patterns in your deployments.
High availability
When you deploy DS servers into a highly available directory service, you are implementing the primary use case for which DS software is designed:
-
Data replication lets you eliminate single points of failure.
When using replication, keep in mind the trade off, described in Consistency and Availability.
-
DS upgrade capabilities let you perform rolling upgrades without ever taking the whole service offline.
-
If desired, DS proxy capabilities help you provide a single point of entry for directory applications, hiding the fact that individual servers do go offline.
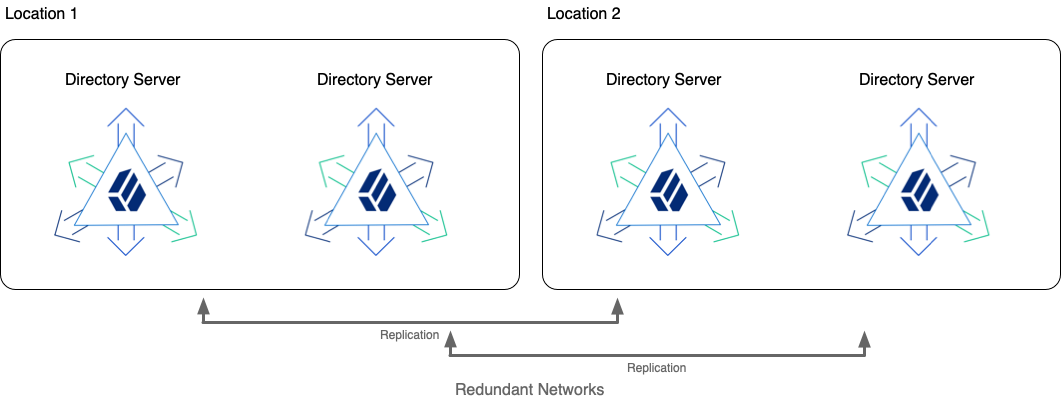
You build a highly available directory service by using redundant servers in multiple locations. If possible, use redundant networks within and between locations to limit network partitions.
When you install or upgrade a highly available directory service, bring component servers online in the following order:
-
Standalone Replication Servers
If you have a large DS service with standalone replication servers, they provide the foundation for high availability. They communicate change messages to directory server replicas, and they also let other servers discover available replicas.
-
Directory Servers
Directory server replicas ultimately respond to client application requests. They hold an eventually convergent copy of the directory data. They require a replication service to communicate with other replicas about changes to their copy of the directory data.
-
Directory Proxy Servers
If you use DS directory proxy servers for a unified view of the service, they discover DS replicas by querying the replication service. They forward requests to the replicas, and responses to the client applications.
In addition to redundant server components, avoiding downtime depends on being able operationally to recover quickly and effectively. Prepare and test your plans. Even if disaster strikes, you will be able to repair the service promptly.
Plan how you store backup files both onsite and offsite. Make sure you have safe copies of the master keys that let directory servers decrypt encrypted data. For details, see Backup and restore.
When defining disaster recovery plans, consider at least the following situations:
-
The entire service is down.
It is important to distinguish whether the situation is temporary and easily recoverable, or permanent and requires implementation of disaster recovery plans.
If an accident, such as a sudden power cut at a single-site deployment, brought all the servers down temporarily, restart them when the power returns. As described in Server Recovery, directory servers might have to replay their transaction logs before they are ready. However, this operation happens automatically when you restart the server.
In a disaster, the entire service could go offline permanently. Be prepared to rebuild the entire service. For details, refer to Disaster recovery.
-
Part of the service is down.
Failover client applications to servers still in operation, and restart or rebuild servers that are down.
You can configure directory proxy servers to fail over automatically, and to retry requests for certain types of failure. For details, see LDAP proxy.
-
The network is temporarily down between servers.
By default, you do not need to take immediate action for a temporary network outage. As long as client applications can still communicate with local servers, replication is designed to catch up when the network connections are reestablished.
By default, when a directory server replica cannot communicate with a replication server, the
isolation-policysetting prevents the directory server replica from accepting updates.In any case, if the network is partitioned longer than the replication purge delay (default: 3 days), then replication will have purged older data, and might not be able to catch up. For longer network outages, you will have to reinitialize replication.
When defining procedures to rebuild a service that is permanently offline, the order of operations is the same as during an upgrade:
-
Redirect client applications to a location where the service is still running.
If the proxy layer is still running, directory proxy servers can automatically fail requests over to remote servers that are still running.
-
Rebuild replication servers.
-
Rebuild directory servers.
-
Rebuild directory proxy servers.
High scalability
A high-scale directory service is one that requires high performance. For example, very high throughput or very low response times, or both. Or, it has a large data set, such as 100 million entries. When building a high-scale directory, the fundamental question is whether to scale up or scale out.
Scaling up means deploying more powerful server systems. Scaling out means deploying many more server systems.
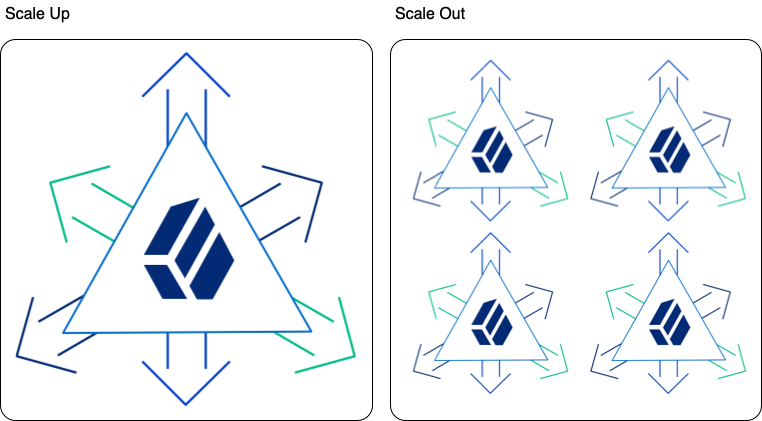
| Scaling Up | Scaling Out | |
|---|---|---|
Why Choose…? |
|
|
Advantages |
|
|
Disadvantages |
|
|
Plan to scale
Before building a test directory service, start sizing systems by considering service level objectives (SLOs) and directory data.
Define SLOs as described in Performance Requirements. Once you have defined the SLOs, model directory client traffic to test them using your own tools, or the tools described in Performance Tests.
Estimate the disk space needed for each server. This depends on the traffic you modelled to meet SLOs, and on directory data that represents what you expect in production:
-
Import a known fraction of the expected initial data with the server configured for production.
For help, see Generate Test Data. Make sure you adapt the template for your data. Do not rely only on the default template for the
makeldifcommand. -
Check the size of the database.
Divide by the fraction used in the previous step to estimate the total starting database size.
-
Multiply the result to account for replication metadata.
To estimate the volume of replication metadata, set up replication with multiple servers as expected in production, and run the estimated production load that corresponds to the data you used. Keep the load running until the replication purge delay. After the purge delay, measure the size of the databases on a directory server, and the size of the changelog database on a replication server. Assuming the load is representative of the production load including expected peaks and normal traffic, additional space used since the LDIF import should reflect expected growth due to replication metadata.
-
Multiply the result to account for the overall growth that you expect for the directory service during the lifetime of the current architecture.
-
To complete the estimate, add 2 GB for default access log files, and space for any backups or LDIF exports you expect to store on local disk.
For a directory server, make sure the system has enough RAM available to cache the database.
By default, database files are stored under the /path/to/opendj/db directory.
Ideally, the RAM available to the server should be at least 1.5 to 2 times the total size of the database files on disk.
Scale up
When scaling up on appropriately powerful server systems, each system must have the resources to run a high-scale DS server. As described in Scaling Replication, a directory server replica is only required to absorb its share of the full read load. But each replica must be able to absorb the full write load for the service.
Make sure that the estimates you arrived at in Plan to scale remain within the capabilities of each server and system.
In addition to the recommendations in Hardware, and the tips in Performance Settings, consider the following points to avoid resource contention:
-
For best performance, use dedicated servers.
-
Run as few additional system services as possible.
-
Run standalone replication servers, directory servers, and directory proxy servers on separate systems.
-
In addition to using fast disks with good IOPS, put logs, databases, and backup files on separate disk subsystems.
-
Keep resource limitations for client applications to acceptable minimums.
-
Schedule backups and maintenance for minimum service impact.
Scale out
When scaling out onto multiple server systems, you must find a usable way to distribute or shard the data into separate replication domains. In some cases, each replication domain holds a branch of the DIT with a similar amount of traffic, and an equivalent amount of data. Entries could then be distributed based on location or network or some other attribute. Branches could join at a base DN that brings all the entries together in the same logical view.
Separate at least the directory server replicas in each replication domain, so that they share only minimal and top-level entries. To achieve this, use subtree replication, which is briefly described in Subtree Replication. Each replica can hold minimal and top-level entries in one database backend, but its primary database backend holds only the branch it shares with others in the domain.
If the data to scale out is all under a single DN, consider using a DS proxy server layer to perform the data distribution, as described in Data Distribution.
When building a scaled-out architecture, be sure to consider the following questions:
-
How will you distribute the data to allow the service to scale naturally, for example, by adding a replication domain?
-
How will you manage what are essentially multiple directory services?
All of your operations, from backup and recovery to routine monitoring, must take the branch data into account, always distinguishing between replication domains.
-
How will you automate operations?
-
How will you simplify access to the service?
Consider using DS proxy servers for a single point of entry, as described in Single Point of Access.
Data sovereignty
In many countries, how you store and process user accounts and profile information is subject to regulations and restrictions that protect users' privacy. Data sovereignty legislation is beyond the scope of this document. However, DS servers do include features to help you build services in compliance with data sovereignty requirements:
-
Data replication
-
Subtree replication
-
Fractional replication
The deployments patterns described below address questions of data storage. When planning your deployment, also consider how client applications access and process directory data. By correctly configuring access controls, as described in Access control, you can restrict network access by hostname or IP address, but not generally by physical location of a mobile client application, for example.
Consider developing a dedicated service layer to manage policies that define what clients can access and process based on their location. If your deployment calls for more dynamic access management, use DS together with ForgeRock Access Management software.
Replication and data sovereignty
Data replication is critical to a high-scale, highly available directory service. For deployments where data protection is also critical, you must, however, make sure you do not replicate data outside locations where you can guarantee compliance with local regulations.
As described in Deploying Replication, replication messages flow from directory servers through replication servers to other directory servers. Replication messages contain data that has changed, including data governed by privacy regulations:
-
For details on replicating data that must not leave a given location, see Subtree replication.
-
For details on replicating only part of the data set outside a given location, see Fractional replication.
Subtree replication
As described in Replication Per Base DN, the primary unit of replication is the base DN. Subtree replication refers to putting different subtrees (branches) in separate backends, and then replicating those subtrees only to specified servers. For example, you can ensure that the data replicates only to locations where you can guarantee compliance with the regulations in force.
For subtree replication, the RDN of the subtree base DN identifies the subtree. This leads to a hierarchical directory layout. The directory service retains the logical view of a flatter layout, because the branches all join at a top-level base DN.
The following example shows an LDIF outline for a directory service with top-level and local backends:
-
The
userDatabackend holds top-level entries, which do not directly reference users in a particular region. -
The
region1backend holds entries under theou=Region 1,dc=example,dc=combase DN. -
The
region2backend holds entries under theou=Region 2,dc=example,dc=combase DN.
The example uses nested groups to avoid referencing local accounts at the top level, but still allowing users to belong to top-level groups:
# %<--- Start of LDIF for userData --->%
# Base entries are stored in the userData backend:
dn: dc=example,dc=com # Base DN of userData backend
...
dn: ou=groups,dc=example,dc=com # Stored in userData backend
...
dn: ou=Top-level Group,ou=groups,dc=example,dc=com
...
member: ou=R1 Group,ou=groups,ou=Region 1,dc=example,dc=com
member: ou=R2 Group,ou=groups,ou=Region 2,dc=example,dc=com
dn: ou=people,dc=example,dc=com # Stored in userData backend
...
# %<--- End of LDIF for userData --->%
# %<--- Start of LDIF for Region 1 --->%
# Subtree entries are stored in a country or region-specific backend.
dn: ou=Region 1,dc=example,dc=com # Base DN of region1 backend
...
dn: ou=groups,ou=Region 1,dc=example,dc=com # Stored in region1 backend
...
dn: ou=R1 Group,ou=groups,ou=Region 1,dc=example,dc=com
...
member: uid=aqeprfEUXIEuMa7M,ou=people,ou=Region 1,dc=example,dc=com
...
dn: ou=people,ou=Region 1,dc=example,dc=com # Stored in region1 backend
...
dn: uid=aqeprfEUXIEuMa7M,ou=people,ou=Region 1,dc=example,dc=com
uid: aqeprfEUXIEuMa7M
...
# %<--- End of LDIF for Region 1 --->%
# %<--- Start of LDIF for Region 2 --->%
dn: ou=Region 2,dc=example,dc=com # Base DN of region2 backend
...
dn: ou=groups,ou=Region 2,dc=example,dc=com # Stored in region2 backend
...
dn: ou=groups,ou=R2 Group,ou=Region 2,dc=example,dc=com
...
member: uid=8EvlfE0rRa3rgbX0,ou=people,ou=Region 2,dc=example,dc=com
...
dn: ou=people,ou=Region 2,dc=example,dc=com # Stored in region2 backend
...
dn: uid=8EvlfE0rRa3rgbX0,ou=people,ou=Region 2,dc=example,dc=com
uid: 8EvlfE0rRa3rgbX0
...
# %<--- End of LDIF for Region 2 --->%The deployment for this example has the following characteristics:
-
The LDIF is split at the comments about where to cut the file:
# %<--- Start|End of LDIF for ... --->% -
All locations share the LDIF for
dc=example,dc=com, but the data is not replicated.If DS replicates
dc=example,dc=com, it replicates all data for that base DN, which includes all the data from all regions.Instead, minimize the shared entries, and manually synchronize changes across all locations.
-
The local LDIF files are constituted and managed only in their regions:
-
Region 1 data is only replicated to servers in region 1.
-
Region 2 data is only replicated to servers in region 2.
-
-
The directory service only processes information for users in their locations according to local regulations.

In a variation on the deployment shown above, consider a deployment with the following constraints:
-
Region 1 regulations allow region 1 user data to be replicated to region 2.
You choose to replicate the region 1 base DN in both regions for availability.
-
Region 2 regulations do not allow region 2 user data to be replicated to region 1.
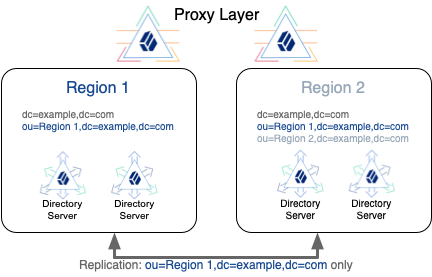
When you use subtree replication in this way, client applications can continue to read and update directory data as they normally would. Directory servers only return data that is locally available.
For additional information, see Subtree Replication, and Split Data.
Fractional replication
In some deployments, regulations let you replicate some user attributes. For example, consider a deployment where data sovereignty regulations in one region let you replicate UIDs and class of service levels everywhere, but do not let personally identifiable information leave the user’s location.
Consider the following entry where you replicate only the uid and classOfService attributes
outside the user’s region:
dn: uid=aqeprfEUXIEuMa7M,ou=people,ou=Region 1,dc=example,dc=com
objectClass: top
objectClass: cos
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: posixAccount
cn: Babs Jensen
cn: Barbara Jensen
facsimiletelephonenumber: +1 408 555 1992
gidNumber: 1000
givenname: Barbara
homeDirectory: /home/bjensen
l: Region 1
mail: bjensen@example.com
manager: uid=2jD5NanzOZGjMmcz,ou=people,ou=Region 1,dc=example,dc=com
ou: People
ou: Product Development
preferredLanguage: en, ko;q=0.8
roomnumber: 0209
sn: Jensen
telephonenumber: +1 408 555 1862
uidNumber: 1076
userpassword: {PBKDF2-HMAC-SHA256}10000:<hash>
# Outside the user's region, you replicate only these attributes:
uid: aqeprfEUXIEuMa7M
classOfService: bronzeTo let you replicate only a portion of each entry, DS servers implement fractional replication. You configure fractional replication by updating the directory server configuration to specify which attributes to include or exclude in change messages from replication servers to the directory server replica.
The replication server must remain located with the directory server replicas that hold full entries which include all attributes. The replication server can receive updates from these replicas, and from replicas that hold fractional entries. Each replication server must therefore remain within the location where the full entries are processed. Otherwise, replication messages describing changes to protected attributes would be sent outside the location where the full entries are processed.
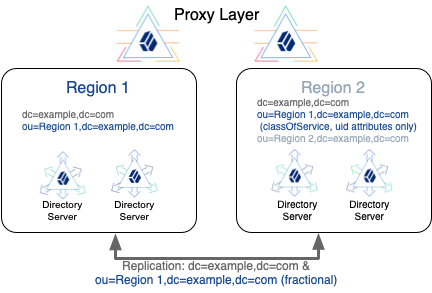
To leave schema checking enabled on the replicas that receive fractional updates, portions of entries
that are replicated must themselves be complete entries.
In other words, in the example above, the entry’s structural object class
would have to allow classOfService and uid.
This would require editing the schema, and the objectClass values of the entries.
For details, see LDAP schema.
For additional information, see Fractional Replication.
Interoperability
Common use cases involve interoperability with other directory software.
| Use Case | See… |
|---|---|
More than one directory service |
|
Credentials in another directory service |
|
Must sync changes across directory services |
|
Web clients need alternate data views |
Proxy layer
Adding a directory proxy layer can help you deploy alongside an existing directory service. The proxy layer lets you provide a single entry point to both new and old directory services.
You configure a directory proxy server to connect to servers in each directory. DS proxy servers can discover DS directory servers by connecting to DS replication servers. For other directories, you must statically enumerate the directory server to contact. DS proxy servers work with any LDAP directory server that supports the standard proxied authorization control defined in RFC 4370.
Each DS proxy server forwards client requests to the directory service based on the target DN of the operation. As long as the base DNs for each directory service differ, the proxy layer can provide a single entry point to multiple directory services.
For details, see Single Point of Access.
Pass-through authentication
For cases where an existing directory service holds authentication credentials, DS servers provide a feature called pass-through authentication.
With pass-through authentication, the DS server effectively redirects LDAP bind operations to a remote LDAP directory service. If the DS and remote user accounts do not have the same DN, you configure the DS server to automatically map local entries to the remote entries. Pass-through authentication can cache passwords if necessary for higher performance with frequent authentication.
For details, see Pass-Through Authentication.
Data synchronization and migration
You may need to continually synchronize changes across multiple services, or to migrate data from an existing directory service.
For ongoing data synchronization across multiple services, consider ForgeRock Identity Management software or a similar solution. ForgeRock Identity Management software supports configurable data reconciliation and synchronization at high scale, and with multiple data sources, including directory services.
For one-time upgrade and data migration to DS software, the appropriate upgrade and migration depends on your deployment:
-
Offline Migration
When downtime is acceptable, you can synchronize data, then migrate applications to the DS service and retire the old service.
Depending on the volume of data, you might export LDIF from the old service and import LDIF into the DS service during the downtime period. In this case, stop the old service at the beginning of the downtime period to avoid losing changes.
If the old service has too much data to fit the export/import operation into the downtime period, you can perform an export/import operation before the downtime starts, but you must then implement ongoing data synchronization from the old service to the DS service. Assuming you can keep the new DS service updated with the latest changes, the DS service will be ready to use. You can stop the old service after migrating the last client application.
-
Online Migration
When downtime is not acceptable, both services continue running concurrently. You must be able to synchronize data, possibly in both directions. ForgeRock Identity Management software supports bi-directional data synchronization.
Once you have bi-directional synchronization operating correctly, migrate applications from the old service to the DS service. You can stop the old service after migrating the last client application.
Alternative views
Not all directory clients expect the same directory data. Clients might even expect completely different identity objects.
DS servers expose the same LDAP data view to all directory clients. (You can adjust this behavior somewhat for update operations, as described in Change Incoming Updates.)
The RESTful views of directory data for HTTP clients are fully configurable, however. By developing alternative REST to LDAP mappings and exposing multiple APIs, or different versions of the same API, you can present directory data in different ways to different applications. For details, see Configure HTTP User APIs, and REST to LDAP reference.