Clustered reconciliation
In a clustered deployment, you can configure reconciliation jobs to be distributed across multiple nodes in the cluster. Clustered reconciliation is configured per mapping and can improve reconciliation performance, particularly for very large data sets.
Clustered reconciliation uses the paged reconciliation mechanism and the scheduler service to divide the source data set into pages, and then to schedule reconciliation "sub-jobs" per page, distributing these sub-jobs across the nodes in the cluster.
Regular (non-clustered) reconciliation has two phases—a source phase and a target phase. Clustered reconciliation effectively has three phases:
- Source page phase
-
During this phase, reconciliation sub-jobs are scheduled in succession, page by page. Each source page job does the following:
-
Executes a source query using the paging cookie from the invocation context.
-
Schedules the next source page job.
-
Performs the reconciliation of the source IDs returned by the query.
-
Writes statistics summary information which is aggregated so that you can obtain the status of the complete reconciliation run by performing a GET on the
reconendpoint. -
On completion, writes the
repo_id,source_id, andtarget_idto the repository.
-
- Source phase completion check
-
This phase is scheduled when the source query returns null. This check runs, and continues to reschedule itself, as long as source page jobs are running. When the completion check determines that all the source page jobs are complete, it schedules the target phase.
- Target phase
-
This phase queries the target IDs, then removes all of the IDs that correspond to the
repo_id,source_id, andtarget_idwritten by the source pages. The remaining target IDs are used to run the target phase, taking into account all records on the target system that were not correlated to a source ID during the source phase sub-jobs.
Configure clustered reconciliation for a mapping
To specify that the reconciliation for a specific mapping should be distributed across a cluster, add the clusteredSourceReconEnabled property to the mapping and set it to true. For example:
{
"mappings" : [
{
"name" : "systemLdapAccounts_managedUser",
"source" : "system/ldap/account",
"target" : "managed/user",
"clusteredSourceReconEnabled" : true,
...
}|
When clustered reconciliation is enabled, source query paging is enabled automatically, regardless of the value that you set for the |
By default, the number of records per page is 10000. You can also enable target query paging with the reconTargetQueryPaging property (defaults to false). To change the query page sizes, set the reconSourceQueryPageSize and reconTargetQueryPageSize properties.
The following example enables target query paging and changes the target and source query page sizes:
{
"mappings" : [
{
"name" : "systemLdapAccounts_managedUser",
"source" : "system/ldap/account",
"target" : "managed/user",
"clusteredSourceReconEnabled" : true,
"reconTargetQueryPaging" : true,
"reconSourceQueryPageSize" : 12000,
"reconTargetQueryPageSize" : 12000,
...
}To set these properties using the admin UI, click Configure > Mappings, select the mapping to change, and click the Advanced tab.
Clustered reconciliation has the following limitations:
-
A complete non-clustered reconciliation run is synchronous with the single reconciliation invocation.
By contrast, a clustered reconciliation is asynchronous. In a clustered reconciliation, the first execution is synchronous only with the reconciliation of the first page. This job also schedules the subsequent pages of the clustered reconciliation to run on other cluster nodes. When you schedule a clustered reconciliation or call the operation over REST, do not set
waitForCompletiontotrue, because you cannot wait for the operation to complete before the next operation starts.Because this first execution does not encompass the entire reconciliation operation for that mapping, you cannot rely on the Quartz
concurrentExecutionproperty to prevent two reconciliation operations from running concurrently. If you use Quartz to schedule clustered reconciliations (as described in Configure Scheduled Synchronization), make sure that the interval between scheduled operations exceeds the known run of the entire clustered reconciliation. The run-length of a specific clustered reconciliation can vary. You must therefore build in appropriate buffer times between schedules, or use a scheduled script that performs a GET on therecon/endpoint, and dispatches the next reconciliation on a mapping only when the previous reconciliation run has completed. -
Clustered reconciliations can recover missing source pages (for example, if a cluster goes offline during a clustered reconciliation run), except when used with a connector using server-side logic to handle paging that returns a static paging cookie.
Clustered reconciliation progress
The sourceProcessedByNode property indicates how many records are processed by each node. You can verify the load distribution per node by running a GET on the recon endpoint, for example:
curl \
--header "X-OpenIDM-Username: openidm-admin" \
--header "X-OpenIDM-Password: openidm-admin" \
--header "Accept-API-Version: resource=1.0" \
--request GET \
"http://localhost:8080/openidm/recon"
...
"started": "2017-05-11T10:04:59.563Z",
"ended": "",
"duration": 342237,
"sourceProcessedByNode": {
"node2": 21500,
"node1": 22000
}
}
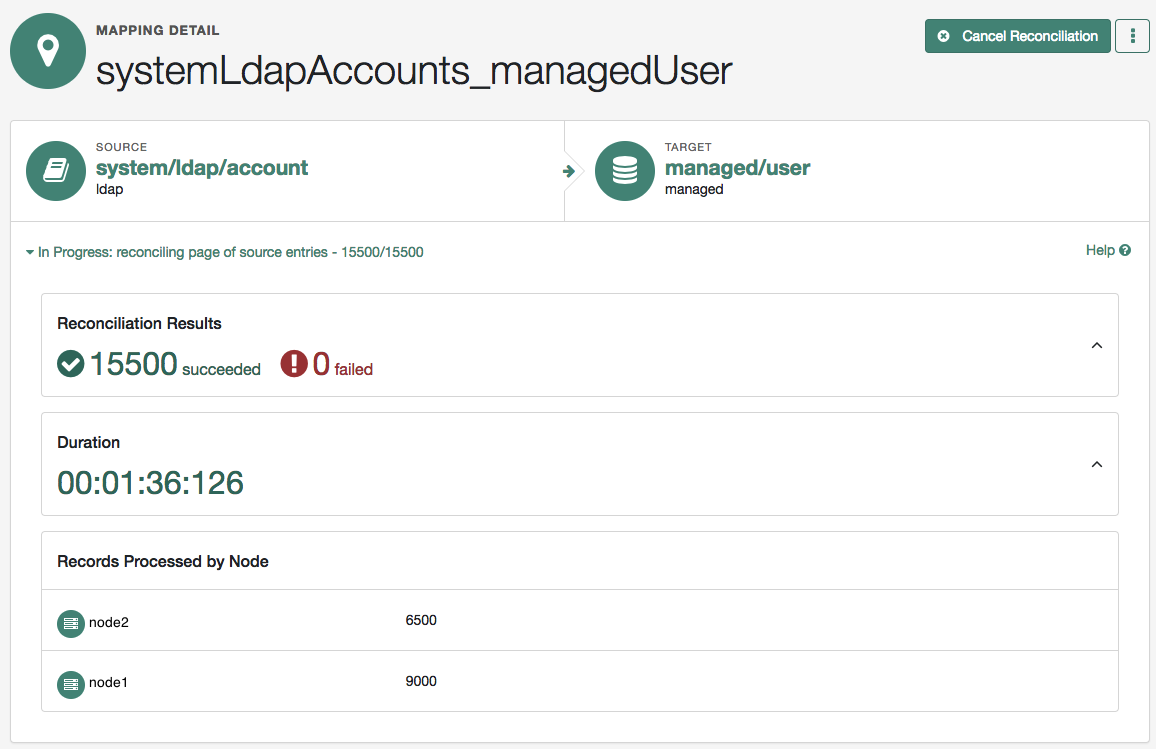
You can also display the nodes responsible for each source page in the admin UI. Click on the relevant mapping and expand the In Progress or Reconciliation Results item. The following image shows a clustered reconciliation in progress. The details include the number of records that have been processed, the current duration of the reconciliation, and the load distribution, per node:
Cancel a clustered reconciliation
You cancel a clustered reconciliation in the same way as a non-clustered reconciliation, for example:
curl \
--header "X-OpenIDM-Username: openidm-admin" \
--header "X-OpenIDM-Password: openidm-admin" \
--header "Accept-API-Version: resource=1.0" \
--request POST \
"http://localhost:8080/openidm/recon/90892122-5ceb-4bbe-86f7-94272df834ad-406025?_action=cancel"
{
"_id": "90892122-5ceb-4bbe-86f7-94272df834ad-406025",
"action": "cancel",
"status": "INITIATED"
}
When the cancellation has completed, a query on that reconciliation ID will show the state and stage of the reconciliation as follows:
{
"_id": "90892122-5ceb-4bbe-86f7-94272df834ad-406025",
"mapping": "systemLdapAccounts_managedUser",
"state": "CANCELED",
"stage": "COMPLETED_CANCELED",
"stageDescription": "reconciliation aborted.",
"progress": {
"source": {
"existing": {
"processed": 23500,
"total": "23500"
}
},
"target": {
"existing": {
"processed": 23498,
"total": "?"
},
...
}In a clustered environment, all reconciliation operations are considered to be "cluster-friendly". This means that even if a mapping is configured as "clusteredSourceReconEnabled" : false, you can view the in progress operation on any node in the cluster, even if that node is not currently processing the reconciliation. You can also cancel a reconciliation in progress from any node in the cluster.