Install a Multi-Node Deployment
This section presents instructions on deploying Autonomous Identity in a multi-node deployment. Multi-node deployments are configured in production environments, providing performant throughput by distributing the processing load across servers and supporting failover redundancy.
Like single-node deployment, ForgeRock provides a Deployer Pro script to pull a Docker image from
ForgeRock’s Google Cloud Registry repository with the microservices and analytics needed for the system.
The deployer also uses the node IP addresses specified in your hosts file to set up an overlay network and your nodes.
| The procedures are similar to multinode deployments using older Autonomous Identity release, except that you must install and configure the dependent software packages (for example, Apache Cassandra/MongoDB, Apache Spark and Livy, OpenSearch and OpenSearch Dashboards, and Docker) prior to running Autonomous Identity. |
Prerequisites
Deploy Autonomous Identity on a multi-node target on Redhat Linux Enterprise 8 or CentOS Stream 8. The following are prerequisites:
-
Operating System. The target machine requires Redhat Linux Enterprise 8 or CentOS Stream 8. The deployer machine can use any operating system as long as Docker is installed. For this chapter, we use Redhat Linux Enterprise 8 as its base operating system.
If you are upgrading Autonomous Identity on a RHEL 7/CentOS 7, the upgrade to 2022.11 uses RHEL 7/CentOS 7 only. For new and clean installations, Autonomous Identity requires RHEL 8 or CentOS Stream 8 only. -
Default Shell. The default shell for the
autoiduser must bebash. -
Subnet Requirements. We recommend deploying your multi-node machines within the same subnet. Ports must be open for the installation to succeed. Each instance should be able to communicate to the other instances.
If any hosts used for the Docker cluster (docker-managers, docker-workers) have an IP address in the range of 10.0.x.x, they will conflict with the Swarm network. As a result, the services in the cluster will not connect to the Cassandra database or Elasticsearch backend.
The Docker cluster hosts must be in a subnet that provides IP addresses 10.10.1.x or higher.
-
Deployment Requirements. Autonomous Identity provides a
deployer.shscript that downloads and installs the necessary Docker images. To download the deployment images, you must first obtain a registry key to log into the ForgeRock Google Cloud Registry. The registry key is only available to ForgeRock Autonomous Identity customers. For specific instructions on obtaining the registry key, refer to How To Configure Service Credentials (Push Auth, Docker) in Backstage. -
Filesystem Requirements. Autonomous Identity requires a shared filesystem accessible from the Spark main, Spark worker, analytics hosts, and application layer. The shared filesystem should be mounted at the same mount directory on all of those hosts. If the mount directory for the shared filesystem is different from the default,
/data, update the/autoid-config/vars.ymlfile to point to the correct directories:analytics_data_dir: /data analytics_conf_dif: /data/conf
-
Architecture Requirements. Make sure that the Spark main is on a separate node from the Spark workers.
-
Database Requirements. Decide which database you are using: Apache Cassandra or MongoDB. The configuration procedure is slightly different for each database.
-
Deployment Best-Practice. The example combines the OpenSearch data and OpenSearch Dashboards nodes. For best performance in production, dedicate a separate node to OpenSearch, data nodes, and OpenSearch Dashboards.
-
IPv4 Forwarding. Many high-security environments run their CentOS-based systems with IPv4 forwarding disabled. However, Docker Swarm does not work with a disabled IPv4 forward setting. In such environments, make sure to enable IPv4 forwarding in the file
/etc/sysctl.conf:net.ipv4.ip_forward=1
| We recommend that your deployer team have someone with Cassandra expertise. This guide is not sufficient to troubleshoot any issues that may arise. |
Set Up the Nodes
Set up three virtual machines.
-
Create a Redhat Linux Enterprise 8 or CentOS Stream 8 virtual machine: N2 4 core and 16 GB. Verify your operating system.
sudo cat /etc/centos-release
For multinode deployments, there is a known issue with RHEL 8/CentOS Stream 8 and overlay network configurations. Refer to Known Issues in 2022.11.0. -
Set the user for the target node to
autoid. In this example, create userautoid:sudo adduser autoid sudo passwd autoid echo "autoid ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/autoid sudo usermod -aG wheel autoid su - autoid
-
Optional. Install yum-utils package on the deployer machine. yum-utils is a utilities manager for the Yum RPM package repository. The repository compresses software packages for Linux distributions.
sudo yum install -y yum-utils
-
Install the following packages needed in the Autonomous Identity deployment:
-
Java 11. For example,
sudo dnf install java-11-openjdk-devel. -
wget. For example,
sudo dnf install wget. -
unzip. For example,
sudo dnf install unzip. -
elinks. For example,
sudo yum install -y elinks. -
Python 3.8.13. Refer to https://docs.python.org/release/3.8.13/.
-
-
Repeat this procedure for the other nodes.
Install third-party components
Set up a machine with the required third-party software dependencies. Refer to: Install third-party components.
Set Up SSH on the Deployer
-
On the deployer machine, change to the
~/.sshdirectory.cd ~/.ssh
-
Run
ssh-keygento generate an RSA keypair, and then click Enter. You can use the default filename.Do not add a key passphrase as it results in a build error. ssh-keygen -t rsa -C "autoid"
The public and private rsa key pair is stored in
home-directory/.ssh/id_rsaandhome-directory/.ssh/id_rsa.pub. -
Copy the SSH key to the
autoid-configdirectory.cp id_rsa ~/autoid-config
-
Change the privileges to the file.
chmod 400 ~/autoid-config/id_rsa
-
Copy your public SSH key,
id_rsa.pub, to each of your nodes.If your target system does not have an ~/.ssh/authorized_keys, create it usingsudo mkdir -p ~/.ssh, thensudo touch ~/.ssh/authorized_keys.For this example, copy the SSH key to each node:
ssh-copy-id -i id_rsa.pub autoid@<Node IP Address>
-
On the deployer machine, test your SSH connection to each target machine. This is a critical step. Make sure the connection works before proceeding with the installation.
For example, SSH to first node:
ssh -i id_rsa autoid@<Node 1 IP Address> Last login: Sat Oct 3 03:02:40 2020
-
If you can successfully SSH to each machine, set the privileges on your
~/.sshand~/.ssh/authorized_keys.chmod 700 ~/.ssh && chmod 600 ~/.ssh/authorized_keys
-
Enter Exit to end your SSH session.
-
Repeat steps 5–8 again for each node.
Set Up a shared data folder
The Docker main and worker nodes plus the analytics main and worker nodes require a shared data directory, typically, /data.
There are numerous ways to set up a shared directory, the following procedure is just one example and sets up an NFS server on the analytics master.
-
On the Analytics Spark Main node, install
nfs-utils. This step may require that you run the install with root privileges, such assudoor equivalent.sudo yum install -y nfs-utils
-
Create the
/datadirectory.mkdir -p /data
-
Change the permissions on the
/datadirectory.chmod -R 755 /data chown nfsnobody:nfsnobody /data
-
Start the services and enable them to start at boot.
systemctl enable rpcbind systemctl enable nfs-server systemctl enable nfs-lock systemctl enable nfs-idmap systemctl start rpcbind systemctl start nfs-server systemctl start nfs-lock systemctl start nfs-idmap
-
Define the sharing points in the
/etc/exportsfile.vi /etc/exports /data <Remote IP Address 1>(rw,sync,no_root_squash,no_all_squash) /data <Remote IP Address 2>(rw,sync,no_root_squash,no_all_squash)
If you change the domain name and target environment, you need to also change the certificates to reflect the new changes. For more information, refer to Customize Domains.
-
Start the NFS service.
systemctl restart nfs-server
-
Add the NFS service to the
firewall-cmdpublic zone service:firewall-cmd --permanent --zone=public --add-service=nfs firewall-cmd --permanent --zone=public --add-service=mountd firewall-cmd --permanent --zone=public --add-service=rpc-bind firewall-cmd --reload
-
On each spark worker node, run the following:
-
Install
nfs-utils:yum install -y nfs-utils
-
Create the NFS directory mount points:
mkdir -p /data
-
Mount the NFS shared directory:
mount -t nfs <NFS Server IP>:/data /data
-
Test the new shared directory by creating a small text file. On an analytics worker node, run the following, and then check for the presence of the test file on the other servers:
cd /data touch test
-
Install Autonomous Identity
Make sure you have the following prerequisites:
-
IP address of machines running OpenSearch, MongoDB, or Cassandra.
-
The Autonomous Identity user should have permission to write to
/opt/autoidon all machines -
To download the deployment images for the install, you still need your registry key to log into the ForgeRock Google Cloud Registry to download the artifacts.
-
Make sure you have the proper OpenSearch certificates with the exact names for both pem and JKS files copied to
~/autoid-config/certs/elastic:-
esnode.pem
-
esnode-key.pem
-
root-ca.pem
-
elastic-client-keystore.jks
-
elastic-server-truststore.jks
-
-
Make sure you have the proper MongoDB certificates with exact names for both pem and JKS files copied to
~/autoid-config/certs/mongo:-
mongo-client-keystore.jks
-
mongo-server-truststore.jks
-
mongodb.pem
-
rootCA.pem
-
-
Make sure you have the proper Cassandra certificates with exact names for both pem and JKS files copied to ~/autoid-config/certs/cassandra:
-
Zoran-cassandra-client-cer.pem
-
Zoran-cassandra-client-keystore.jks
-
Zoran-cassandra-server-cer.pem
-
zoran-cassandra-server-keystore.jks
-
Zoran-cassandra-client-key.pem
-
Zoran-cassandra-client-truststore.jks
-
Zoran-cassandra-server-key.pem
-
Zoran-cassandra-server-truststore.jks
-
-
Create the
autoid-configdirectory.mkdir autoid-config
-
Change to the directory.
cd autoid-config
-
Log in to the ForgeRock Google Cloud Registry using the registry key. The registry key is only available to ForgeRock Autonomous Identity customers. For specific instructions on obtaining the registry key, refer to How To Configure Service Credentials (Push Auth, Docker) in Backstage.
docker login -u _json_key -p "$(cat autoid_registry_key.json)" https://gcr.io/forgerock-autoid
The following output is displayed:
Login Succeeded
-
Run the create-template command to generate the
deployer.shscript wrapper and configuration files. Note that the command sets the configuration directory on the target node to/config. The--userparameter eliminates the need to usesudowhile editing the hosts file and other configuration files.docker run --user=$(id -u) -v ~/autoid-config:/config -it gcr.io/forgerock-autoid/deployer-pro:2022.11.0 create-template
-
Create a certificate directory for elastic.
mkdir -p autoid-config/certs/elastic
-
Copy the OpenSearch certificates and JKS files to
autoid-config/certs/elastic. -
Create a certificate directory for MongoDB.
mkdir -p autoid-config/certs/mongo
-
Copy the MongoDB certificates and JKS files to
autoid-config/certs/mongo. -
Create a certificate directory for Cassandra.
mkdir -p autoid-config/certs/cassandra
-
Copy the Cassandra certificates and JKS files to
autoid-config/certs/cassandra. -
Update the
hostsfile with the IP addresses of the machines. Thehostsfile must include the IP addresses for Docker nodes, Spark main/livy, and the MongoDB master. While the deployer pro does not install or configure the MongoDB main server, the entry is required to run the MongoDB CLI to seed the Autonomous Identity schema.[docker-managers] [docker-workers] [docker:children] docker-managers docker-workers [spark-master-livy] [cassandra-seeds] #For replica sets, add the IPs of all Cassandra nodes [mongo_master] # Add the MongoDB main node in the cluster deployment # For example: 10.142.15.248 mongodb_master=True [odfe-master-node] # Add only the main node in the cluster deployment
-
Update the
vars.ymlfile:-
Set
db_driver_typetomongoorcassandra. -
Set
elastic_host,elastic_port, andelastic_userproperties. -
Set
kibana_host. -
Set the Apache livy install directory.
-
Ensure the
elastic_user,elastic_port, andmongo_partare correctly configured. -
Update the
vault.ymlpasswords for elastic and mongo to refect your installation. -
Set the Cassandra-related parameters in the
vars.ymlfile. Default values are:cassandra: enable_ssl: "true" contact_points: 10.142.15.248 # comma separated values in case of replication set port: 9042 username: zoran_dba cassandra_keystore_password: "Acc#1234" cassandra_truststore_password: "Acc#1234" ssl_client_key_file: "zoran-cassandra-client-key.pem" ssl_client_cert_file: "zoran-cassandra-client-cer.pem" ssl_ca_file: "zoran-cassandra-server-cer.pem" server_truststore_jks: "zoran-cassandra-server-truststore.jks" client_truststore_jks: "zoran-cassandra-client-truststore.jks" client_keystore_jks: "zoran-cassandra-client-keystore.jks"
-
-
Download images:
./deployer.sh download-images
-
Install Apache Livy.
-
The official release of Apache Livy does not support Apache Spark 3.3.1. Use the zip file located at
autoid-config/apache-livy/apache-livy-0.8.0-incubating-SNAPSHOT-bin.zipto install Apache Livy on the Spark-Livy machine. -
For Livy configuration, refer to https://livy.apache.org/get-started/.
-
-
On the Spark-Livy machine, run the following commands to install the python package dependencies:
-
Change to the
/opt/autoiddirectory:cd /opt/autoid
-
Create a
requirements.txtfile with the following content:six==1.11 certifi==2019.11.28 python-dateutil==2.8.1 jsonschema==3.2.0 cassandra-driver numpy==1.19.5 pyarrow==0.16.0 wrapt==1.11.0 PyYAML==5.4 requests pymongo pandas==1.0.5 tabulate openpyxl
-
Install the requirements file:
pip3 install -r requirements.txt
-
-
Make sure that the
/opt/autoiddirectory exists and that it is both readable and writable. -
Run the deployer script:
./deployer.sh run
-
On the Spark-Livy machine, run the following commands to install the Python egg file:
-
Install the egg file:
sudo /usr/local/bin/pip3.8 install setuptools==46.00 cd /opt/autoid/eggs sudo /usr/local/bin/easy_install-3.8 autoid_analytics-2021.3-py3.6.egg
-
Source the
.bashrcfile:source ~/.bashrc
-
Restart Spark and Livy.
./spark/sbin/stop-all.sh ./livy/bin/livy-server stop ./spark/sbin/start-all.sh ./livy/bin/livy-server start
-
Set the Cassandra Replication Factor
Once Cassandra has been deployed, you need to set the replication factor to match the number of nodes on your system. This ensures that each record is stored in each of the nodes. In the event one node is lost, the remaining node can continue to serve content even if the cluster itself is running with reduced redundancy.
You can define replication on a per keyspace-basis as follows:
-
Start the Cassandra shell,
cqlsh, and define theautoidkeyspace. Change the replication factor to match the number of seed nodes. The default admin user for Cassandra iszoran_dba.bin/cqlsh -u zoran_dba zoran_dba@cqlsh> desc keyspace autoid; CREATE KEYSPACE autoid WITH replication = {'class':'SimpleStrategy','replication_factor':'2'} AND durable_writes=true; CREATE TABLE autoid.user_access_decisions_history( user text, entitlement text, date_created timestamp, … -
Restart Cassandra on this node.
-
Repeat these steps on the other Cassandra seed node(s).
Resolve Hostname
After installing Autonomous Identity, set up the hostname resolution for your deployment.
-
Configure your DNS servers to access Autonomous Identity dashboard on the target node. The following domain names must resolve to the IP address of the target node:
<target-environment>-ui.<domain-name>
-
If DNS cannot resolve target node hostname, edit it locally on the machine that you want to access Autonomous Identity using a browser.
Open a text editor and add an entry in the
/etc/hosts(Linux/Unix) file orC:\Windows\System32\drivers\etc\hosts(Windows) for the target node.For multi-node, use the Docker Manager node as your target.
<Docker Mgr Node Public IP Address> <target-environment>-ui.<domain-name>
For example:
<IP Address> autoid-ui.forgerock.com
-
If you set up a custom domain name and target environment, add the entries in
/etc/hosts. For example:<IP Address> myid-ui.abc.com
For more information on customizing your domain name, see Customize Domains.
Access the Dashboard
-
Open a browser. If you set up your own url, use it for your login.
-
Log in as a test user.
test user: bob.rodgers@forgerock.com password: <password>
Check Apache Cassandra
-
Make sure Cassandra is running in cluster mode. For example
/opt/autoid/apache-cassandra-3.11.2/bin/nodetool status
Check MongoDB
-
Make sure MongoDB is running. For example:
mongo --tls \ --host <Host IP> \ --tlsCAFile /opt/autoid/mongo/certs/rootCA.pem \ --tlsAllowInvalidCertificates \ --tlsCertificateKeyFile /opt/autoid/mongo/certs/mongodb.pem
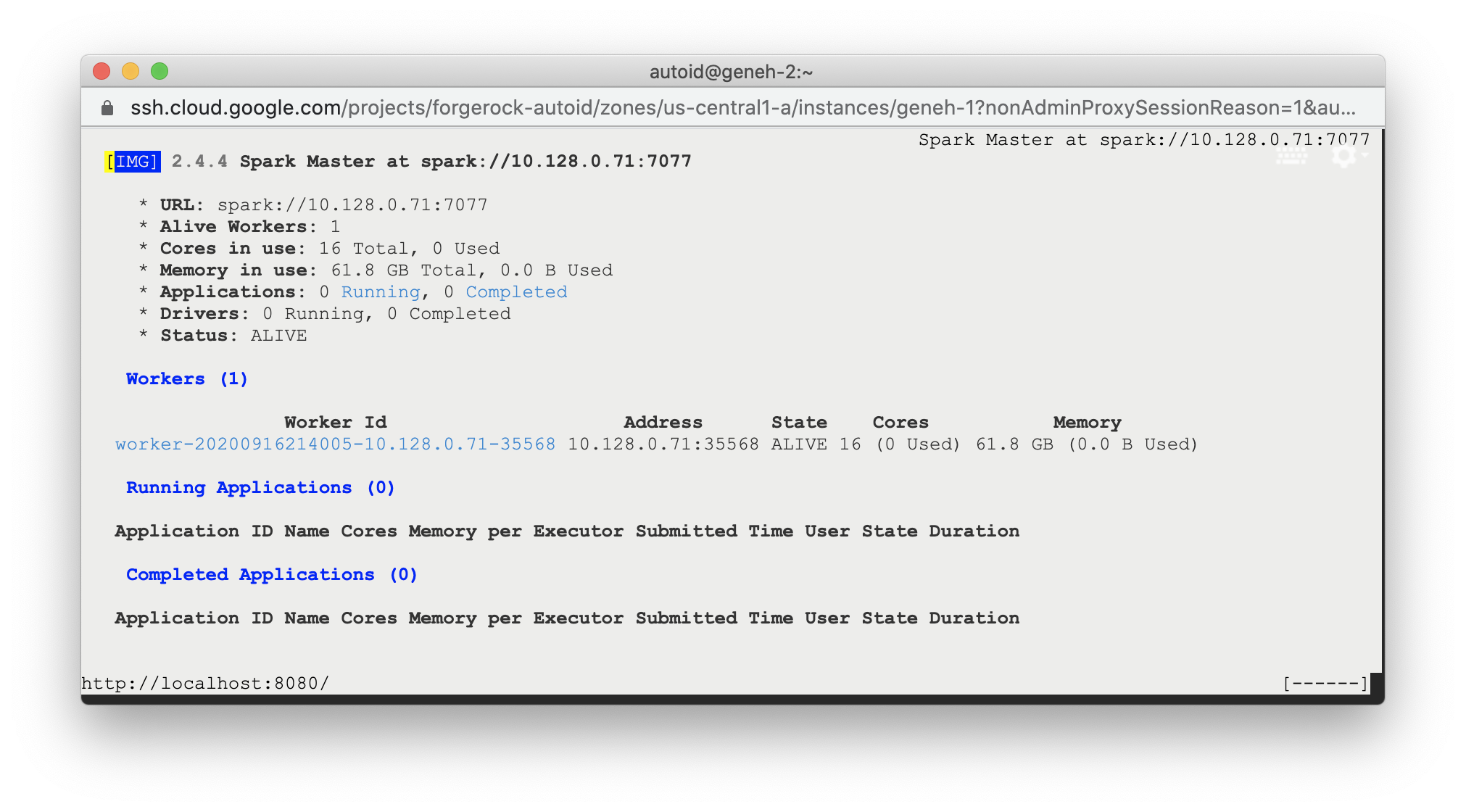
Check Apache Spark
-
SSH to the target node and open Spark dashboard using the bundled text-mode web browser
elinks http://localhost:8080
Spark Master status should display as ALIVE and worker(s) with State ALIVE.
Click to See an Example of the Spark Dashboard
Start the Analytics
If the previous installation steps all succeeded, you must now prepare your data’s entity definitions, data sources, and attribute mappings prior to running your analytics jobs. These step are required and are critical for a successful analytics process.
For more information, see Set Entity Definitions.