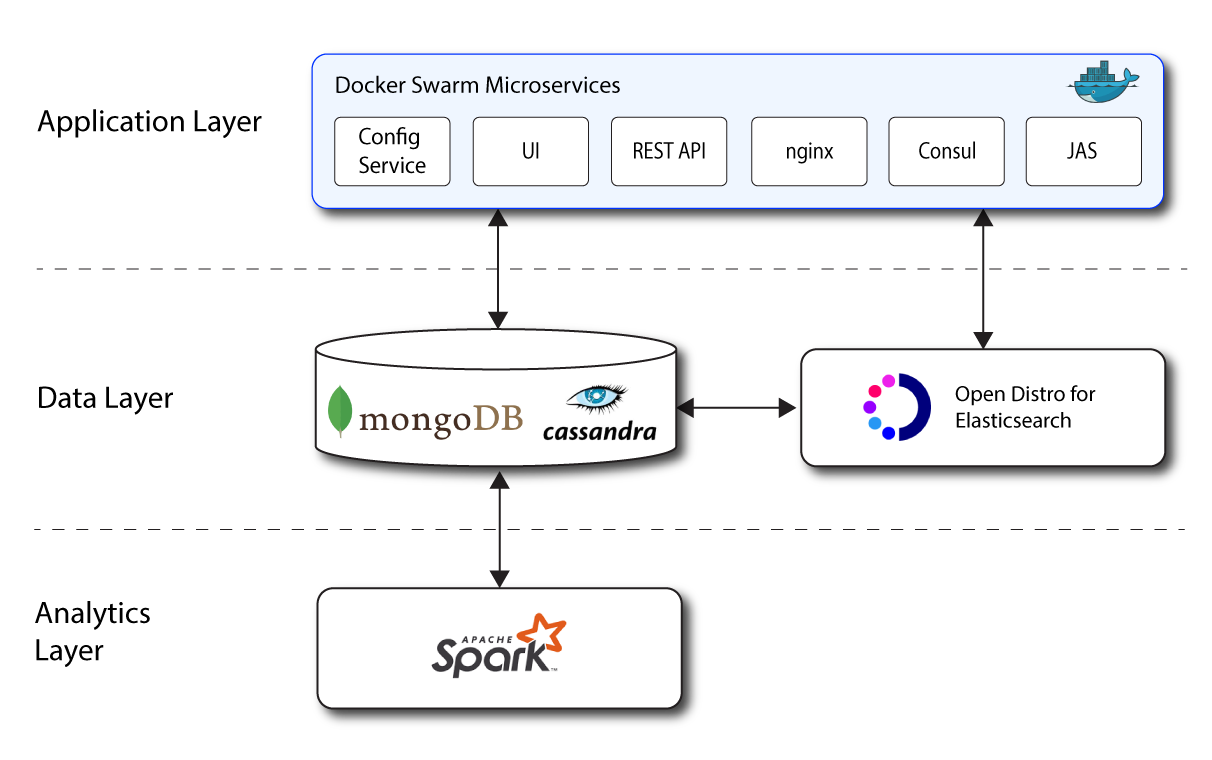
Architecture in Brief
Autonomous Identity’s flexible architecture can deploy in any number of ways: single-node or multi-node configurations across on-prem, cloud, hybrid, or multi-cloud environments. The Autonomous Identity architecture has a simple three-layer conceptual model:
-
Application Layer. Autonomous Identity implements a flexible Docker Swarm microservices architecture, where multiple applications run together in containers. The microservices component provides flexible configuration and end-user interaction to the deployment. The microservices components are the following:
-
Autonomous Identity UI. Autonomous Identity supports a dynamic UI that displays the entitlements, confidence scores, and recommendations.
-
Autonomous Identity API. Autonomous Identity provides an API that can access endpoints using REST. This allows easy scripting and programming for your system.
-
Self-Service Tool. The self-service tool lets users reset their Autonomous Identity passwords.
-
Backend Repository. The backend repository stores Autonomous Identity user information.
-
Configuration Service. Autonomous Identity supports a configuration service that allows you to set parameters for your system and processes.
-
Nginx. Nginx is a popular HTTP server and reverse proxy for routing HTTPS traffic.
-
Hashicorp Consul. Consul is a third-party system for service discovery and configuration.
-
Apache Livy. Autonomous Identity supports Apache Livy to provide a RESTful interface to Apache Spark.
-
Java API Service. Autonomous Identity supports the Java API Service for RESTful interface to the Cassandra or MongoDB database.
-
-
Data Layer. Autonomous Identity supports Apache Cassandra NoSQL and MongoDB databases to serve predictions, confidence scores, and prediction data to the end user. Apache Cassandra is a distributed and linearly scalable database with no single point of failure. MongoDB is a schema-free, distributed database that uses JSON-like documents as data objects. Java API Service (JAS) provides a REST interface to the databases.
Autonomous Identity also implements Open Distro for Elasticsearch and Kibana to improve search performance for its entitlement data. Elastic Persistent Search supports scalable writes and reads.
-
Analytics and Administration Layer. Autonomous Identity uses a multi-source Apache Spark analytics engine to generate the predictions and confidence scores. Apache Spark is a distributed, cluster-computing framework for AI machine learning for large datasets. Autonomous Identity runs the analytics jobs directly from the Spark master over Apache Livy REST interface.
Figure 1: A Simple Conceptual Image of the Autonomous Identity Architecture