Prepare Spark Environment
Apache Spark requires configuration for optimal performance. The key task is to properly tune the Spark server’s memory and executors per core. You must also enable the Spark History logs and configure the SSL connections to the Spark server.
Determine the Optimal Core and Memory Configuration
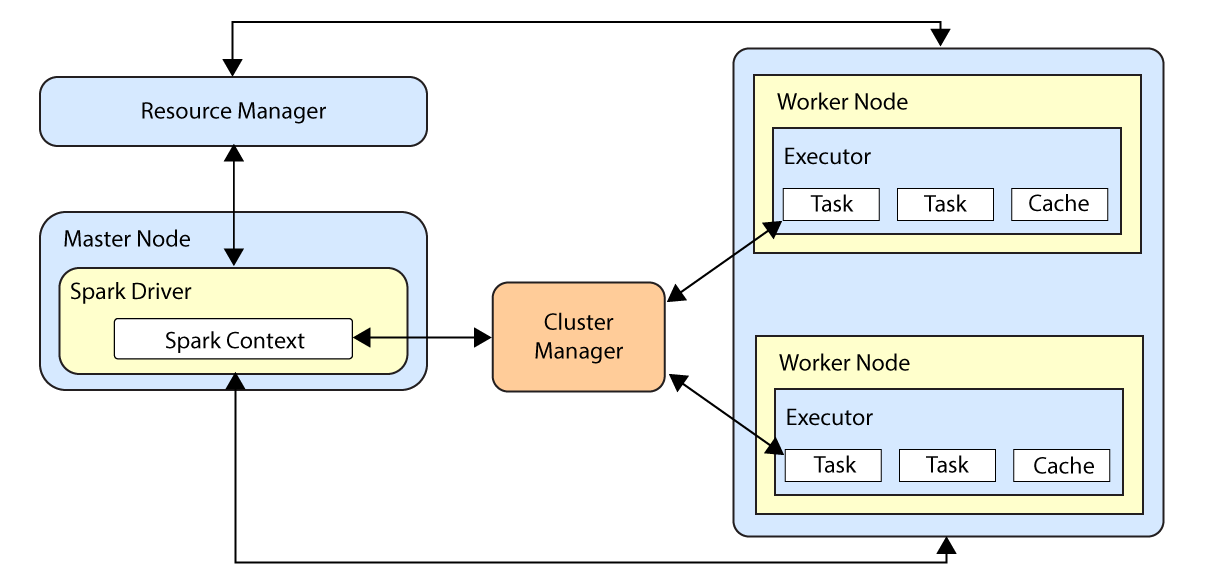
The analytics engine requires tuning prior to processing the entitlements data. Spark distributes its dataset into partitions to allow parallel processing. Each partition runs a executor, which is a JVM process that is launched in a worker node and processes a unit of work called a task on a portion of the dataset.
There are three main tuning parameters that you must configure in the analytics_init_config.yml
file for optimal performance:
-
Number of Executor Cores. Indicates the maximum number of tasks that an executor can run at a time. In Spark, this property is set using the
--executor-coresflag. On the target node, specify this property using thespark.executor.coresparameter. -
Number of Executors. Indicates the number of executors the application allocates in the cluster. In Spark, this property is set using the
--num-executorsflag. On the Analytics container, you specify this property using thespark.total.coresparameter. -
Amount of Memory Allocated to Each Executor. Indicates the amount of memory allocated to the JVM heap memory for each executor. In Spark, this property is set using the
--executor-memory. On the target node, you specify this property using thespark.executor.memoryparameter.
Before configuring these parameters, consider these points:
-
Running Too Much Memory or Too Few Executors. In general, running executors with too much memory (for example, +64GB/executor) often results in excessive garbage collection delays. Running with too few executors (for example, 1 executor/core) does not benefit from caching as it cannot run multiple tasks in a single JVM. This will not leave enough memory for the resource manager.
-
Maximum Overhead Memory. The total amount of memory requested by a resource manager per Spark executor is the sum of the executor memory plus memory overhead. The memory overhead is needed for JVM heap and resource manager processes.
-
One Executor for the App Manager. One executor should be assigned to the application manager and the rest for task processing.
-
Number of Cores. One core should be dedicated to the driver and resource manager application. For example, if the node has 8 cores, 7 of them are available for the executors; one for the driver and resource manager.
The choice is relative to the size of the cluster. The number of executors is then a ratio between the number of cores available for executors and the number of cores per executor times the number of nodes on the cluster.
For optimal performance, run a maximum of 5 cores per executor for good I/O throughput. Minimum number of cores should be 3 cores per executor.
-
Executor Memory. Allocate 7 to 10% of memory to the application manager and executor overhead. For example, if you have a cluster of 96 GB of RAM, you should distribute up to 86GB to the executors.
Let’s look at an example. If you have the following cluster configuration:
-
6 nodes
-
16 cores per node
-
64GB RAM per node
If we have 16 cores per node, leave one core to the Spark application, then we will have 15 cores available per node. The total number of available cores in the cluster will be 15 x 6= 90. The number of available executors is the total cores divided by the number of cores per executor (90/5 = 18). We leave one executor to the application manager; thus, 18 - 1 = 17 executors. Number of executors per node = 17/6 ~ 3. The memory per executor = 64GB/3 = 21 GB. 7 to 10% of the memory must be allocated to heap overhead. Let’s use 7%. Then, executor memory will be 21 - 3 (that is, 7% x 21) = 18GB.
-
Number of Executor Cores = 5
-
Number of Executors = 17
-
Executor Memory = 18GB RAM
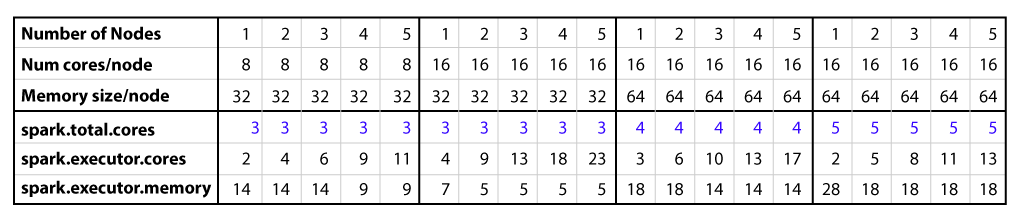
The table below show example Spark executor memory and core combinations for different node configurations:
These Spark values are set in the analytics_init_config.yml
file.
Configure Spark History
For proper maintenance of the analytics machine, the Spark history server must be enabled to record executor logs. You can enable the logging mechanism and history by add the following lines to the Spark configuration file, located at $SPARK_HOME/conf/spark-defaults.conf
.
-
Open the
$SPARK_HOME/conf/spark-defaults.conffile. If the file does not exist, careate one from the sample file provided in theconfdirectory. -
Add the following lines to the file with a text editor.
spark.eventLog.enabled true spark.evenLog.dir file:///tmp/spark-events # the dir is arbitrary spark.history.fs.logDirectory file:///tmp/spark-events
-
Start the Spark History server if installed. The Spark History server is accessible on port 18080 on the master server.
$SPARK_HOME/sbin/start-history-server.sh
|
You can also access the Spark History server using the REST API at |
Configure Spark SSL
You can configure SSL connection to all Spark interfaces by setting the configuration file, analytics_init_config.yml
file. For additional information, see the Spark documentation.
Run the following commands to configure SSL;
-
Generate SSL keys. The keys can be self-signed or public CA-signed certificates.
-
Write an Authentication filter class in Java that implements the Java Filter interface. The interface determines how the credentials are handled. Compile the class to a jar file.
-
Copy the artifact to
$SPARK_HOME/jarsdirectory on all nodes. -
Update the Spark configuration to enable SSL and set up SSL namespace parameters. Update the Spark configurations on all nodes to enable SSL, indicating the keys and authentication filter to use. Make the changes to the configuration file as follows:
# Enable SSL spark.ssl.enabled true spark.ui.https.enabled true spark.ssl.fs.enabled true # Add public/private SSL keys spark.ssl.keyPassword Acc#1234 spark.ssl.keyStore /opt/autoid/certs/zoran-cassandra-client-keystore.jks spark.ssl.keyStorePassword Acc#1234 spark.ssl.trustStore /opt/autoid/certs/zoran-cassandra-server-trustStore.jks spark.ssl.trustStorePassword Acc#1234 spark.ssl.protocol TLSv1.2 # 'com.autoid.spark' is the package in the jar file and # 'BasicAuthFilter' is the class that contains the filter class # Advanced filter implementat would not have parameters to reduce the blast radius spark.ui.filters com.autoid.spark.BasicAuthFilter spark.com.autoid.spark.BasicAuthFilter.params user=user,password=password
-
Restart the Spark services for the new configurations to take effect.