Schedules
Guide to configuring schedules and scanning tasks.
This guide covers schedules and scanning tasks.
Schedule tasks and events
The scheduler service lets you schedule reconciliation and synchronization tasks.
The service depends on the Quartz Scheduler (bundled with IDM), and supports Quartz simple triggers and cron triggers. Use the trigger type that suits your scheduling requirements. For more information, refer to the Quartz documentation on SimpleTriggers and CronTriggers.
In addition to the fine-grained scheduling facility, you can perform a scheduled batch scan for a specified date in IDM data, and then automatically run a task when this date is reached. For more information, refer to Scan data to trigger tasks.
Configure the scheduler service
There is a distinction between the configuration of the scheduler service, and the configuration of individually scheduled tasks and events (which execute based off of the configurations of the scheduler service). The scheduler configuration has the following format, and configures the Quartz Scheduler:
{
"threadPool" : {
"threadCount" : 10
},
"scheduler" : {
"executePersistentSchedules" : {
"$bool" : "&{openidm.scheduler.execute.persistent.schedules}"
}
}
}-
threadCountspecifies the maximum number of threads that are available for running scheduled tasks concurrently. -
executePersistentScheduleslets you disable persistent schedules for a specific node. If this parameter is set tofalse, the Scheduler Service will support the management of persistent schedules (CRUD operations) but it will not run any persistent schedules. The value of this property can be a string or boolean. Its default value istrue. -
advancedProperties(optional) lets you configure additional properties for the Quartz Scheduler.
For details of all the configurable properties for the Quartz Scheduler, refer to the Quartz Scheduler Configuration Reference.
Configure schedules
You can schedule tasks and events using:
Each schedule configuration has the following format:
{
"enabled" : boolean,
"persisted" : boolean,
"recoverable" : boolean,
"concurrentExecution" : boolean,
"type" : "simple | cron",
"repeatInterval" : (optional) integer,
"repeatCount" : (optional) integer,
"startTime" : "(optional) time",
"endTime" : "(optional) time",
"schedule" : "cron expression",
"misfirePolicy" : "optional, string",
"invokeService" : "service identifier",
"invokeContext" : "service specific context info",
"invokeLogLevel" : "(optional) level"
}Schedule configuration properties
The schedule configuration properties are defined as follows:
enabled-
Set to
trueto enable the schedule. When this property isfalse, IDM considers the schedule configuration dormant, and does not allow it to be triggered or launched.If you want to retain a schedule configuration, but do not want it used, set
enabledtofalsefor task and event schedulers, instead of changing the configuration orcronexpressions. persisted(optional)-
Specifies whether the schedule state should be persisted or stored only in RAM. Boolean (
trueorfalse),falseby default.If the schedule is stored only in RAM, the schedule will be lost when IDM is restarted.
recoverable(optional)-
Specifies whether jobs that have failed mid-execution (as a result of a JVM crash or otherwise unexpected termination) should be recovered. Boolean (
trueorfalse),falseby default. concurrentExecution-
Specifies whether multiple instances of the same schedule can run concurrently. Boolean (
trueorfalse),falseby default. Multiple instances of the same schedule cannot run concurrently by default. This setting prevents a new scheduled task from being launched before the same previously launched task has completed. For example, under normal circumstances you would want a liveSync operation to complete before the same operation was launched again. To enable multiple schedules to run concurrently, set this parameter totrue. The behavior of missed scheduled tasks is governed by the misfire policy. type-
The trigger type, either
simpleorcron.To decide which trigger type to use, refer to the Quartz documentation on SimpleTriggers and CronTriggers.
repeatCount-
Used only for simple triggers (
"type" : "simple").The number of times the schedule must be repeated. The repeat count can be
0, a positive integer, or-1. A value of-1indicates that the schedule should repeat indefinitely.If you do not specify a repeat count, the value defaults to
-1. repeatInterval-
Used only for simple triggers (
"type" : "simple").Specifies the interval, in milliseconds, between trigger firings. The repeat interval must be zero or a positive long value. If you set the repeat interval to zero, the scheduler will trigger
repeatCountfirings concurrently (or as close to concurrently as possible).If you do not specify a repeat interval, the value defaults to 0.
startTime(optional)-
This parameter starts the schedule at some time in the future. If the parameter is omitted, empty, or set to a time in the past, the task or event is scheduled to start immediately.
Use ISO 8601 format to specify times and dates (
yyyy-MM-dd’T’HH:mm:ss).To specify a time zone, include the time zone at the end of the
startTime, in the format+|-hh:mm; for example2017-10-31T15:53:00+05:00. If you specify both astartTimeand anendTime, they must have the same time zone. endTime(optional)-
Specifies when the schedule must end, in ISO 8601 format (
yyyy-MM-dd’T’HH:mm:ss+|-hh:mm. schedule-
Used only for cron triggers (
"type" : "cron").Takes
cronexpression syntax. For more information, refer to the CronTrigger Tutorial and Lesson 6: CronTrigger.
misfirePolicy-
For persistent schedules, this optional parameter specifies the behavior if the scheduled task is missed, for some reason. Possible values are as follows:
-
fireAndProceed. The first run of a missed schedule is immediately launched when the server is back online. Subsequent runs are discarded. After this, the normal schedule is resumed. -
doNothing. All missed schedules are discarded and the normal schedule is resumed when the server is back online.
-
invokeService-
Defines the type of scheduled event or action. The value of this parameter can be one of the following:
-
syncfor reconciliation. -
provisionerfor liveSync. -
scriptto call some other scheduled operation defined in a script. -
taskScannerto define a scheduled task that queries a set of objects. For more information, refer to Scan data to trigger tasks.
-
invokeContext-
Specifies contextual information, depending on the type of scheduled event (the value of the
invokeServiceparameter).The following example invokes reconciliation:
{ "invokeService": "sync", "invokeContext": { "action": "reconcile", "mapping": "systemLdapAccount_managedUser" } }The following example invokes a liveSync operation:
{ "invokeService": "provisioner", "invokeContext": { "action": "liveSync", "source": "system/ldap/__ACCOUNT__" } }For scheduled liveSync tasks, the
sourceproperty follows IDM’s convention for a pointer to an external resource object and takes the formsystem/resource-name/object-type.The following example invokes a script, which prints the node ID performing the scheduled job and the time to the console.
{ "enabled" : true, "type": "simple", "repeatInterval": 3600000, "persisted" : true, "concurrentExecution" : false, "invokeService": "script", "invokeContext": { "script" : { "type" : "text/javascript", "source" : "java.lang.System.out.println('Job executing on ' + identityServer.getProperty('openidm.node.id') + ' at: ' + java.lang.System.currentTimeMillis());" } } }These are sample configurations only. Your schedule configuration will differ according to your specific requirements.
invokeLogLevel(optional)-
Specifies the level at which the invocation will be logged. Particularly for schedules that run very frequently, such as liveSync, the scheduled task can generate significant output to the log file, and you should adjust the log level accordingly. The default schedule log level is
info. The value can be set to any one of the SLF4J log levels:-
trace -
debug -
info -
warn -
error -
fatal
-
Manage schedules using REST
The scheduler service is exposed under the /openidm/scheduler context path. Within this context path, the defined scheduled jobs are accessible at /openidm/scheduler/job. A job is the actual task that is run. Each job contains a trigger that starts the job. The trigger defines the schedule according to which the job is executed. You can read and query the existing triggers on the /openidm/scheduler/trigger context path.
The following examples show how schedules are validated, created, read, queried, updated, and deleted, over REST, by using the scheduler service.
|
When you configure schedules over REST, changes made to the schedules are not pushed back into the configuration service. Managing schedules by using the |
Validate cron trigger expressions
Schedules are defined using Quartz cron or simple triggers. If you use a cron trigger, you can validate your cron expression by sending the expression as a JSON object to the scheduler context path:
curl \ --header "Authorization: Bearer <token>" \ --header "Content-Type: application/json" \ --header "Accept-API-Version: resource=2.0" \ --request POST \ --data '{ "cronExpression": "0 0/1 * * * ?" }' \ "https://<tenant-env-fqdn>/openidm/scheduler/job?_action=validateQuartzCronExpression" { "valid": true }
Define a schedule
To define a new schedule, send a PUT or POST request to the scheduler/job context path with the details of the schedule in the JSON payload. A PUT request lets you specify the ID of the schedule. A POST request assigns an ID automatically.
The following example uses a PUT request to create a schedule that fires a script every second. The example assumes the script exists in the specified location. The schedule configuration is as described in Configure Schedules:
curl \ --header "Authorization: Bearer <token>" \ --header "Content-Type: application/json" \ --header "Accept-API-Version: resource=2.0" \ --request PUT \ --data \ '{ "enabled": true, "type": "cron", "schedule": "0/1 * * * * ?", "persisted": true, "misfirePolicy": "fireAndProceed", "invokeService": "script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } } }' \ "https://<tenant-env-fqdn>/openidm/scheduler/job/testlog-schedule" { "_id": "testlog-schedule", "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": "0/1 * * * * ?", "repeatInterval": 0, "repeatCount": 0, "type": "cron", "invokeService": "org.forgerock.openidm.script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "triggers": [ { "calendar": null, "group": "scheduler-service-group", "jobKey": "scheduler-service-group.testlog-schedule", "name": "trigger-testlog-schedule", "nodeId": null, "previousState": null, "serialized": { "type": "CronTriggerImpl", "calendarName": null, "cronEx": { "cronExpression": "0/1 * * * * ?", "timeZone": "Etc/UTC" }, "description": null, "endTime": null, "fireInstanceId": null, "group": "scheduler-service-group", "jobDataMap": { "scheduler.invokeService": "org.forgerock.openidm.script", "scheduler.config-name": "scheduler-testlog-schedule", "scheduler.invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "schedule.config": { "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": "0/1 * * * * ?", "repeatInterval": 0, "repeatCount": 0, "type": "cron", "invokeService": "org.forgerock.openidm.script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "configAlias": null }, "scheduler.invokeLogLevel": "info" }, "jobGroup": "scheduler-service-group", "jobName": "testlog-schedule", "misfireInstruction": 1, "name": "trigger-testlog-schedule", "nextFireTime": 1680204234000, "previousFireTime": null, "priority": 5, "startTime": 1680204234000, "volatility": false }, "state": "NORMAL", "_rev": "2cf55cac-ce2b-4ef8-a4a2-6f98a803bc07-4600", "_id": "scheduler-service-group.trigger-testlog-schedule" } ], "previousRunDate": "2023-03-30T19:22:54.000Z", "nextRunDate": "2023-03-30T19:23:54.000Z" }
|
The previous output includes the |
The following example uses a POST request to create an identical schedule to the one created in the previous example, but with a server-assigned ID:
curl \ --header "Authorization: Bearer <token>" \ --header "Content-Type: application/json" \ --header "Accept-API-Version: resource=2.0" \ --request POST \ --data \ '{ "enabled": true, "type": "cron", "schedule": "0/1 * * * * ?", "persisted": true, "misfirePolicy": "fireAndProceed", "invokeService": "script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } } }' \ "https://<tenant-env-fqdn>/openidm/scheduler/job?_action=create" { "_id": "71fd1b5f-5ebc-4c94-89ac-dbc8e05138d3", "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": "0/1 * * * * ?", "repeatInterval": 0, "repeatCount": 0, "type": "cron", "invokeService": "org.forgerock.openidm.script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "triggers": [ { "calendar": null, "group": "scheduler-service-group", "jobKey": "scheduler-service-group.71fd1b5f-5ebc-4c94-89ac-dbc8e05138d3", "name": "trigger-71fd1b5f-5ebc-4c94-89ac-dbc8e05138d3", "nodeId": "idm-57855cff6c-l8jrb", "previousState": null, "serialized": { "type": "CronTriggerImpl", "calendarName": null, "cronEx": { "cronExpression": "0/1 * * * * ?", "timeZone": "Etc/UTC" }, "description": null, "endTime": null, "fireInstanceId": "idm-57855cff6c-l8jrb_1680180846805", "group": "scheduler-service-group", "jobDataMap": { "scheduler.invokeService": "org.forgerock.openidm.script", "scheduler.config-name": "scheduler-71fd1b5f-5ebc-4c94-89ac-dbc8e05138d3", "scheduler.invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "schedule.config": { "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": "0/1 * * * * ?", "repeatInterval": 0, "repeatCount": 0, "type": "cron", "invokeService": "org.forgerock.openidm.script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "configAlias": null }, "scheduler.invokeLogLevel": "info" }, "jobGroup": "scheduler-service-group", "jobName": "71fd1b5f-5ebc-4c94-89ac-dbc8e05138d3", "misfireInstruction": 1, "name": "trigger-71fd1b5f-5ebc-4c94-89ac-dbc8e05138d3", "nextFireTime": 1680204679000, "previousFireTime": null, "priority": 5, "startTime": 1680204679000, "volatility": false }, "state": "NORMAL", "_rev": "2cf55cac-ce2b-4ef8-a4a2-6f98a803bc07-5927", "_id": "scheduler-service-group.trigger-71fd1b5f-5ebc-4c94-89ac-dbc8e05138d3" } ], "previousRunDate": "2023-03-30T19:30:19.000Z", "nextRunDate": "2023-03-30T19:31:19.000Z" }
The output includes the generated _id of the schedule, in this case:
"_id": "b12e4a77-a626-4a38-a1dc-8edc7498ca1c"
View scheduled job details
The following example displays the details of the schedule created in the previous example. Specify the job ID in the URL:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/scheduler/job/testlog-schedule" { "_id": "testlog-schedule", "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": "0/1 * * * * ?", "repeatInterval": 0, "repeatCount": 0, "type": "cron", "invokeService": "org.forgerock.openidm.script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "triggers": [ { "calendar": null, "group": "scheduler-service-group", "jobKey": "scheduler-service-group.testlog-schedule", "name": "trigger-testlog-schedule", "nodeId": "idm-57855cff6c-l8jrb", "previousState": null, "serialized": { "type": "CronTriggerImpl", "calendarName": null, "cronEx": { "cronExpression": "0/1 * * * * ?", "timeZone": "Etc/UTC" }, "description": null, "endTime": null, "fireInstanceId": "idm-57855cff6c-l8jrb_1680180847170", "group": "scheduler-service-group", "jobDataMap": { "scheduler.invokeService": "org.forgerock.openidm.script", "scheduler.config-name": "scheduler-testlog-schedule", "scheduler.invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "schedule.config": { "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": "0/1 * * * * ?", "repeatInterval": 0, "repeatCount": 0, "type": "cron", "invokeService": "org.forgerock.openidm.script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "configAlias": null }, "scheduler.invokeLogLevel": "info" }, "jobGroup": "scheduler-service-group", "jobName": "testlog-schedule", "misfireInstruction": 1, "name": "trigger-testlog-schedule", "nextFireTime": 1680205063000, "previousFireTime": 1680205062000, "priority": 5, "startTime": 1680205024000, "volatility": false }, "state": "NORMAL", "_rev": "2cf55cac-ce2b-4ef8-a4a2-6f98a803bc07-7099", "_id": "scheduler-service-group.trigger-testlog-schedule" } ], "previousRunDate": "2023-03-30T19:37:42.000Z", "nextRunDate": "2023-03-30T19:37:43.000Z" }
Query scheduled jobs
You can query defined and running scheduled jobs using a regular query filter.
The following query returns the IDs of all defined schedules:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/scheduler/job?_queryFilter=true&_fields=_id" { "result": [ { "_id": "reconcile_systemLdapAccounts_managedUser" }, { "_id": "testlog-schedule" } ] ... }
The following query returns the IDs, enabled status, and next run date of all defined schedules:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/scheduler/job?_queryFilter=true&_fields=_id,enabled,nextRunDate" { "result": [ { "_id": "reconcile_systemLdapAccounts_managedUser", "enabled": false, "nextRunDate": null }, { "_id": "testlog-schedule", "enabled": true, "nextRunDate": "2019-10-09T09:43:17.000Z" } ] ... }
Update a schedule
To update a schedule definition, use a PUT request and update all the static properties of the object.
This example disables the testlog schedule created in the previous example by setting "enabled":false:
curl \ --header "Authorization: Bearer <token>" \ --header "Content-Type: application/json" \ --header "Accept-API-Version: resource=2.0" \ --request PUT \ --data \ '{ "enabled": false, "type": "cron", "schedule": "0/1 * * * * ?", "persisted": true, "misfirePolicy": "fireAndProceed", "invokeService": "script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } } }' \ "https://<tenant-env-fqdn>/openidm/scheduler/job/testlog-schedule" { "_id": "testlog-schedule", "enabled": false, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": "0/1 * * * * ?", "repeatInterval": 0, "repeatCount": 0, "type": "cron", "invokeService": "org.forgerock.openidm.script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "triggers": [], "previousRunDate": null, "nextRunDate": null }
When you disable a schedule, all triggers are removed, and the nextRunDate is set to null. If you re-enable the schedule, a new trigger is generated, and the nextRunDate is recalculated.
List running scheduled jobs
This example returns a list of the jobs that are currently executing. The list lets you decide whether to wait for a specific job to complete before shutting down a server.
|
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request POST \ "https://<tenant-env-fqdn>/openidm/scheduler/job?_action=listCurrentlyExecutingJobs" [ { "enabled": true, "persisted": true, "misfirePolicy": "fireAndProceed", "type": "simple", "repeatInterval": 3600000, "repeatCount": -1, "invokeService": "org.forgerock.openidm.sync", "invokeContext": { "action": "reconcile", "mapping": "systemLdapAccounts_managedUser" }, "invokeLogLevel": "info", "timeZone": null, "startTime": null, "endTime": null, "concurrentExecution": false } ]
Trigger a schedule manually
For testing purposes, and for certain administrative tasks, you can trigger a scheduled task manually, outside of its specified schedule. A scheduled task must be enabled before it can be triggered.
This command triggers the testlog-schedule job created previously:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request POST \ "https://<tenant-env-fqdn>/openidm/scheduler/job/testlog-schedule?_action=trigger" { "success": true }
|
This action is available only from version 2.0 of the scheduler API onwards. |
Pause and resume a scheduled job
Instead of deleting and recreating scheduled jobs, you can pause and resume them if necessary. This command pauses the testlog-schedule job:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request POST \ "https://<tenant-env-fqdn>/openidm/scheduler/job/testlog-schedule?_action=pause" { "success": true }
This command resumes the testlog-schedule job:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request POST \ "https://<tenant-env-fqdn>/openidm/scheduler/job/testlog-schedule?_action=resume" { "success": true }
|
These actions are available only from version 2.0 of the scheduler API onwards. |
Query schedule triggers
When a scheduled job is created, a trigger for that job is created automatically and is included in the schedule definition. The trigger is essentially what causes the job to be started. You can read all the triggers that have been generated on a system with the following query on the openidm/scheduler/trigger context path:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/scheduler/trigger?_queryFilter=true" { "result": [ { "_id": "scheduler-service-group.trigger-testlog-schedule", "_rev": "00000000db3523f1", "calendar": null, "group": "scheduler-service-group", "jobKey": "scheduler-service-group.testlog-schedule", "name": "trigger-testlog-schedule", "nodeId": "node1", "previousState": null, "serialized": { ... }, "state": "NORMAL" } ] }
The trigger object contents are:
_id-
The ID of the trigger, which is based on the schedule ID. The trigger ID is made up of the group name, followed by
trigger-prepended to the schedule ID:group.trigger-schedule-id. For example, if the schedule ID wastestlog-schedule, then the trigger ID would bescheduler-service-group.trigger-testlog-schedule. _rev-
The revision of the trigger object. This property is reserved for internal use and specifies the revision of the object in the repository. This is the same value that is exposed as the object’s ETag through the REST API. The content of this property is not defined. No consumer should make any assumptions of its content beyond equivalence comparison.
previousState-
The previous state of the trigger, before its current state. For a description of Quartz trigger states, refer to the Quartz API documentation.
name-
The trigger name, which matches the ID of the schedule that created the trigger, with
trigger-added:trigger-schedule-id. state-
The current state of the trigger. For a description of Quartz trigger states, refer to the Quartz API documentation.
nodeId-
The ID of the node that has acquired the trigger, useful in a clustered deployment. If the trigger has not been acquired by a node yet, this will return
null. calendar-
This is a part of the Quartz implementation, but is not currently supported by IDM. This will always return
null. serialized-
The JSON serialization of the trigger class.
group-
The name of the group that the trigger is in, always
scheduler-service-group. jobKey-
The name of the job associated with the trigger:
group.schedule-id.
To read the contents of a specific trigger, send a GET request to the trigger ID; for example:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/scheduler/trigger/scheduler-service-group.trigger-testlog-schedule" { "_id": "scheduler-service-group.trigger-testlog-schedule", "_rev": "00000000cd1723dd", "calendar": null, "group": "scheduler-service-group", "jobKey": "scheduler-service-group.testlog-schedule", "name": "trigger-testlog-schedule", "nodeId": "node1", "previousState": null, "serialized": { ... }, "state": "NORMAL" }
To view the triggers that have been acquired, send a GET request to the scheduler, with a _queryFilter of nodeId. For example:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/scheduler/trigger?_queryFilter=(nodeId+pr)"
To view the triggers that have not yet been acquired by any node, send a GET request to the scheduler, with a _queryFilter to list the triggers with a null nodeId. For example:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/scheduler/trigger?_queryFilter=%21(nodeId+pr)"
Delete a schedule
To delete a schedule, send a DELETE request to the schedule ID. For example:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=2.0" \ --request DELETE \ "https://<tenant-env-fqdn>/openidm/scheduler/job/testlog-schedule" { "_id": "testlog-schedule", "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": "0/1 * * * * ?", "repeatInterval": 0, "repeatCount": 0, "type": "cron", "invokeService": "org.forgerock.openidm.script", "invokeContext": { "script": { "type": "text/javascript", "source": "logger.info('Testing schedules!');" } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "triggers": [ { "calendar": null, "group": "scheduler-service-group", "jobKey": "scheduler-service-group.testlog-schedule", "name": "trigger-testlog-schedule", "nodeId": "idm-57855cff6c-l8jrb", "previousState": null, "serialized": { "type": "CronTriggerImpl", "calendarName": null, "cronEx": { "cronExpression": "0/1 * * * * ?", "timeZone": "Etc/UTC" }, "description": null, "endTime": null, "fireInstanceId": "idm-57855cff6c-l8jrb_1680180847387", "group": "scheduler-service-group", "jobDataMap": {}, "jobGroup": "scheduler-service-group", "jobName": "testlog-schedule", "misfireInstruction": 1, "name": "trigger-testlog-schedule", "nextFireTime": 1680205354000, "previousFireTime": 1680205353000, "priority": 5, "startTime": 1680205240000, "volatility": false }, "state": "NORMAL", "_rev": "2cf55cac-ce2b-4ef8-a4a2-6f98a803bc07-7809", "_id": "scheduler-service-group.trigger-testlog-schedule" } ], "previousRunDate": "2023-03-30T19:42:33.000Z", "nextRunDate": "2023-03-30T19:42:34.000Z" }
The DELETE request returns the entire JSON object.
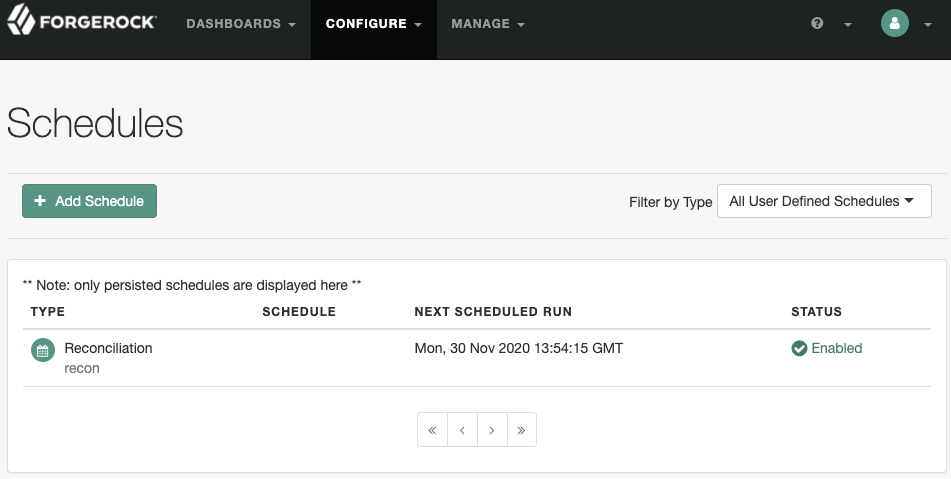
Manage schedules using the IDM admin UI
To manage schedules via the IDM admin UI:
-
In the Identity Cloud admin UI, go to Native Consoles > Identity Management.
-
From the IDM admin UI, click Configure > Schedules.
Add, remove, and change schedules here. By default, only persisted schedules are shown in the Schedules list. To show non-persisted (in memory) schedules, select Filter by Type > In Memory.
Schedules and daylight savings time
The scheduler service supports Quartz cron triggers and simple triggers. Cron triggers schedule jobs to fire at specific times with respect to a calendar (rather than every N milliseconds). This scheduling can cause issues when clocks change for daylight savings time (DST) if the trigger time falls around the clock change time in your specific time zone.
Depending on the trigger schedule, and on the daylight event, the trigger might be skipped or might appear not to fire for a short period. This interruption can be particularly problematic for liveSync where schedules execute continuously. In this case, the time change (for example, from 02:00 back to 01:00) causes an hour break between each liveSync execution.
To prevent DST from having an impact on your schedules, use simple triggers instead of cron triggers.
Persistent schedules
By default, scheduling information (such as schedule state, and the details of the schedule run) is stored in RAM. This means that such information is lost when the server is rebooted. The schedule configuration is not lost when the server is shut down, and normal scheduling continues when the server is restarted. However, there are no details of missed schedule runs that should have occurred during the period the server was unavailable.
You can configure schedules to be persistent, which means that the scheduling information is stored in the internal repository, rather than in RAM. With persistent schedules, scheduling information is retained when the server is shut down. Any previously scheduled jobs can be rescheduled automatically when the server is restarted.
To configure persistent schedules, set persisted to true in the schedule configuration.
If the server is down when a scheduled task was set to occur, one or more runs of that schedule might be missed. To specify what action should be taken if schedules are missed, set the misfirePolicy in the schedule configuration file. The misfirePolicy determines what IDM should do if scheduled tasks are missed. Possible values are as follows:
fireAndProceed-
The first run of a missed schedule is immediately implemented when the server is back online. Subsequent runs are discarded. After this, the normal schedule is resumed.
doNothing-
All missed schedules are discarded and the normal schedule is resumed when the server is back online.
Schedule examples
The following example shows a schedule for reconciliation that is not enabled. When the schedule is enabled ("enabled" : true,), reconciliation runs every 30 minutes (1800000 milliseconds), and repeats indefinitely:
{
"enabled": false,
"persisted": true,
"type": "simple",
"repeatInterval": 1800000,
"invokeService": "sync",
"invokeContext": {
"action": "reconcile",
"mapping": "systemLdapAccounts_managedUser"
}
}The following example shows a schedule for liveSync enabled to run every 15 seconds, repeating indefinitely. Note that the schedule is persisted; that is, stored in the repository rather than in memory. If one or more liveSync runs are missed, as a result of the server being unavailable, the first run of the liveSync operation is implemented when the server is back online. Subsequent runs are discarded. After this, the normal schedule is resumed:
{
"enabled": true,
"persisted": true,
"misfirePolicy" : "fireAndProceed",
"type": "simple",
"repeatInterval": 15000,
"invokeService": "provisioner",
"invokeContext": {
"action": "liveSync",
"source": "system/ldap/account"
}
}Scan data to trigger tasks
In addition to the fine-grained scheduling facility, IDM provides a task scanning mechanism. The task scanner lets you scan a set of properties with a complex query filter, at a scheduled interval, and then launches a script on the objects returned by the query.
For example, the task scanner can scan all managed/realm-name_user objects for a specific date, and invoke a script that launches a task on the user object when that date is reached.
The task scanner runs a scheduled task that queries a managed object, then launches a script based on the query results. Scanning tasks are configured in the same way as standard scheduled tasks, as part of the schedule configuration, with the invokeService parameter set to taskscanner. The invokeContext parameter defines the scan details, and the task that should be launched when the specified condition is triggered.
Create a new scanning task
The following example defines a scheduled scanning task that triggers a sunset script:
|
The following example uses one of the available array fields in IDM, The fields It is recommended to create tasks via REST as the IDM admin UI does not allow for complex query filters. |
{
"enabled" : true,
"type" : "simple",
"repeatInterval" : 3600000,
"persisted": true,
"concurrentExecution" : false,
"invokeService" : "taskscanner",
"invokeContext" : {
"waitForCompletion" : false,
"numberOfThreads" : 5,
"scan" : {
"_queryFilter" : "/frIndexedMultivalued1/date lt \"${Time.now}\") AND !(/frIndexedMultivalued1/task-completed pr",
"object" : "managed/realm-name_user",
"taskState" : {
"started" : "/frIndexedMultivalued1/task-started",
"completed" : "/frIndexedMultivalued1/task-completed"
},
"recovery" : {
"timeout" : "10m"
}
},
"task" : {
"script" : {
"type" : "text/javascript",
"source" : "var patch = [{ \"operation\" : \"replace\", \"field\" : \"/active\", \"value\" : false }, { \"operation\" : \"replace\", \"field\" : \"/accountStatus\", \"value\" : \"inactive\" }];\n\nlogger.debug(\"Performing Task on {} ({})\", input.mail, objectID);\n\nopenidm.patch(objectID, null, patch); true;"
}
}
}
}The schedule configuration calls an inline script. The sample script marks all user objects that match the specified conditions as inactive. You can use this sample script to trigger a specific workflow, or any other task associated with the sunset process.
The task will only execute on users who have a valid frIndexedMultivalued1/date field. You can add a frIndexedMultivalued1/date field to user entries over REST. To make the field visible in the IDM admin UI, you must add it to your managed object configuration by making the property searchable (for more information, refer to Property configuration properties).
This example command adds a frIndexedMultivalued1/date field to bjensen's entry, over REST:
curl \ --header "Content-Type: application/json" \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request POST \ --data '[{ "operation" : "add", "field" : "frIndexedMultivalued1/date", "value" : "2019-12-20T12:00:00Z" }]' \ "https://<tenant-env-fqdn>/openidm/managed/realm-name_user?_action=patch&_queryFilter=userName+eq+'bjensen'"
The remaining properties in the schedule configuration are as follows:
The invokeContext parameter takes the following properties:
waitForCompletion(optional)-
This property specifies whether the task should be performed synchronously. Tasks are performed asynchronously by default (with
waitForCompletionset to false). A task ID (such as{"_id":"354ec41f-c781-4b61-85ac-93c28c180e46"}) is returned immediately. If this property is set to true, tasks are performed synchronously, and the ID is not returned until all tasks have completed. maxRecords(optional)-
The maximum number of records that can be processed. This property is not set by default so the number of records is unlimited. If a maximum number of records is specified, that number will be spread evenly over the number of threads.
numberOfThreads(optional)-
By default, the task scanner runs in a multi-threaded manner; that is, numerous threads are dedicated to the same scanning task run. Multi-threading generally improves the performance of the task scanner. The default number of threads for a single scanning task is 10. To change this default, set the
numberOfThreadsproperty. The sample configuration sets the default number of threads to 5. scan-
The details of the scan. The following properties are defined:
_queryFilter-
The query filter that identifies the entries for which this task should be run.
The query filter provided in the sample schedule configuration (
/sunset/date lt \"${Time.now}\") AND !(/sunset/task-completed pr) identifies managed users whosesunset/dateproperty is before the current date and for whom the sunset task has not yet completed.The sample query supports time-based conditions, with the time specified in ISO 8601 format (Zulu time). You can write any query to target the set of entries that you want to scan.
For time-based queries, it’s possible to use the
${Time.now}macro object (which fetches the current time). You can also specify any date/time in relation to the current time, using the+or-operator, and a duration modifier. For example: changing the sample query to${Time.now + 1d}would return all user objects whose/sunset/dateis the following day (current time plus one day). Note: you must include space characters around the operator (+or-). The duration modifier supports the following unit specifiers:-
ssecond -
mminute -
hhour -
dday -
Mmonth -
yyear
-
object-
Defines the managed object type against which the query should be performed, as defined in the
managed.jsonfile. taskState-
Indicates the names of the fields in which the start message, and the completed message are stored. These fields are used to track the status of the task.
started-
specifies the field that stores the timestamp for when the task begins.
completed-
specifies the field that stores the timestamp for when the task completes its operation. The
completedfield is present as soon as the task has started, but its value isnulluntil the task has completed.
recovery(optional)-
Specifies a configurable
timeout, after which the task scanner process ends. For clustered IDM instances, there might be more than one task scanner running at a time. A task cannot be launched by two task scanners at the same time. When one task scanner "claims" a task, it indicates that the task has been started. That task is then unavailable to be claimed by another task scanner and remains unavailable until the end of the task is indicated. In the event that the first task scanner does not complete the task by the specified timeout, for whatever reason, a second task scanner can pick up the task.
task-
Provides details of the task that is performed. Usually, the task is invoked by a script, whose details are defined in the
scriptproperty:type-
The script type.
IDM supports
"text/javascript". source-
The inline script to execute.
|
For more information about using functions in scripts, refer to scripting functions. |
Manage scanning tasks
You can trigger, cancel, or list the existing scanning tasks in IDM.
You can manage scanning tasks in IDM using:
Manage scanning tasks using REST
You can trigger, cancel, and monitor scanning tasks over the REST interface, using the REST endpoint openidm/taskscanner.
Create a scanning task
The following command defines a scanning task named sunsetTask:
curl \ --header "Authorization: Bearer <token>" \ --header "Content-type: application/json" \ --header "Accept-API-Version: resource=2.0" \ --request PUT \ --data '{ "enabled" : true, "type" : "simple", "repeatInterval" : 3600000, "persisted": true, "concurrentExecution" : false, "invokeService" : "taskscanner", "invokeContext" : { "waitForCompletion" : false, "numberOfThreads" : 5, "scan" : { "_queryFilter" : "/sunset/date lt \"$\{Time.now}\") AND !($\{taskState.completed} pr", "object" : "managed/realm-name_user", "taskState" : { "started" : "/sunset/task-started", "completed" : "/sunset/task-completed" }, "recovery" : { "timeout" : "10m" } }, "task" : { "script" : { "type" : "text/javascript", "source" : "var patch = [{ \"operation\" : \"replace\", \"field\" : \"/active\", \"value\" : false }, { \"operation\" : \"replace\", \"field\" : \"/accountStatus\", \"value\" : \"inactive\" }];\n\nlogger.debug(\"Performing Sunset Task on {} ({})\", input.mail, objectID);\n\nopenidm.patch(objectID, null, patch); true;" } } } }' \ "https://<tenant-env-fqdn>/openidm/scheduler/job/sunsetTask" { "_id": "sunsetTask", "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": null, "repeatInterval": 3600000, "repeatCount": -1, "type": "simple", "invokeService": "org.forgerock.openidm.taskscanner", "invokeContext": { "waitForCompletion": false, "numberOfThreads": 5, "scan": { "_queryFilter": "/sunset/date lt \"$\{Time.now}\") AND !($\{taskState.completed} pr", "object": "managed/realm-name_user", "taskState": { "started": "/sunset/task-started", "completed": "/sunset/task-completed" }, "recovery": { "timeout": "10m" } }, "task": { "script": { "type": "text/javascript", "source" : "var patch = [{ \"operation\" : \"replace\", \"field\" : \"/active\", \"value\" : false }, { \"operation\" : \"replace\", \"field\" : \"/accountStatus\", \"value\" : \"inactive\" }];\n\nlogger.debug(\"Performing Sunset Task on {} ({})\", input.mail, objectID);\n\nopenidm.patch(objectID, null, patch); true;" } } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false, "triggers": [ { "calendar": null, "group": "scheduler-service-group", "jobKey": "scheduler-service-group.sunsetTask", "name": "trigger-sunsetTask", "nodeId": null, "previousState": null, "serialized": { "type": "SimpleTriggerImpl", "calendarName": null, "complete": false, "description": null, "endTime": null, "fireInstanceId": null, "group": "scheduler-service-group", "jobDataMap": { "scheduler.invokeService": "org.forgerock.openidm.taskscanner", "scheduler.config-name": "scheduler-sunsetTask", "scheduler.invokeContext": { "waitForCompletion": false, "numberOfThreads": 5, "scan": { "_queryFilter": "/sunset/date lt \"$\{Time.now}\") AND !($\{taskState.completed} pr", "object": "managed/realm-name_user", "taskState": { "started": "/sunset/task-started", "completed": "/sunset/task-completed" }, "recovery": { "timeout": "10m" } }, "task": { "script": { "type": "text/javascript", "source" : "var patch = [{ \"operation\" : \"replace\", \"field\" : \"/active\", \"value\" : false }, { \"operation\" : \"replace\", \"field\" : \"/accountStatus\", \"value\" : \"inactive\" }];\n\nlogger.debug(\"Performing Sunset Task on {} ({})\", input.mail, objectID);\n\nopenidm.patch(objectID, null, patch); true;" } } }, "schedule.config": { "enabled": true, "persisted": true, "recoverable": false, "misfirePolicy": "fireAndProceed", "schedule": null, "repeatInterval": 3600000, "repeatCount": -1, "type": "simple", "invokeService": "org.forgerock.openidm.taskscanner", "invokeContext": { "waitForCompletion": false, "numberOfThreads": 5, "scan": { "_queryFilter": "/sunset/date lt \"$\{Time.now}\") AND !($\{taskState.completed} pr", "object": "managed/realm-name_user", "taskState": { "started": "/sunset/task-started", "completed": "/sunset/task-completed" }, "recovery": { "timeout": "10m" } }, "task": { "script": { "type": "text/javascript", "source" : "var patch = [{ \"operation\" : \"replace\", \"field\" : \"/active\", \"value\" : false }, { \"operation\" : \"replace\", \"field\" : \"/accountStatus\", \"value\" : \"inactive\" }];\n\nlogger.debug(\"Performing Sunset Task on {} ({})\", input.mail, objectID);\n\nopenidm.patch(objectID, null, patch); true;" } } }, "invokeLogLevel": "info", "startTime": null, "endTime": null, "concurrentExecution": false }, "scheduler.invokeLogLevel": "info" }, "jobGroup": "scheduler-service-group", "jobName": "sunsetTask", "misfireInstruction": 1, "name": "trigger-sunsetTask", "nextFireTime": 1570618094818, "previousFireTime": null, "priority": 5, "repeatCount": -1, "repeatInterval": 3600000, "startTime": 1570618094818, "timesTriggered": 0, "volatility": false }, "state": "NORMAL", "_rev": "000000006751ccf1", "_id": "scheduler-service-group.trigger-sunsetTask" } ], "previousRunDate": null, "nextRunDate": "2019-10-09T10:48:14.818Z" }
Trigger a scanning task
To trigger a scanning task over REST, use the execute action and specify the name of the task (effectively the scheduled job name). To obtain a list of task names, you can query the /openidm/scheduler/job endpoint. Note, however, that not all jobs are scanning tasks. Only those jobs that have which have the correct task scanner invokeContext can be triggered in this way.
The following example triggers the sunsetTask defined in the previous example:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request POST \ "https://<tenant-env-fqdn>/openidm/taskscanner?_action=execute&name=sunsetTask" { "_id": "9f2564c8-193c-4871-8869-6080f374b1bd-2073" }
The following example triggers a task named taskscan_sunset:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request POST \ "https://<tenant-env-fqdn>/openidm/taskscanner?_action=execute&name=taskscan_sunset" { "_id": "8d7742f0-5245-41cf-89a5-de32fc50e326-3323" }
By default, a scanning task ID is returned immediately when the task is initiated. Clients can make subsequent calls to the task scanner service, using this task ID to query its state and to call operations on it.
To have the scanning task complete before the ID is returned, set the waitForCompletion property to true in the task definition file.
Cancel a scanning task
To cancel a scanning task that is in progress, send a REST call with the cancel action, specifying the task ID. The following call cancels the scanning task initiated in the previous example:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request POST \ "https://<tenant-env-fqdn>/openidm/taskscanner/9f2564c8-193c-4871-8869-6080f374b1bd-2073?_action=cancel" { "_id":"9f2564c8-193c-4871-8869-6080f374b1bd-2073", "status":"SUCCESS" }
|
You cannot cancel a scanning task that has already completed. |
List the scanning tasks
To retrieve a list of scanning tasks, query the openidm/taskscanner context path. The following example displays all scanning tasks, regardless of their state:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/taskscanner?_queryFilter=true" { "result": [ { "_id": "9f2564c8-193c-4871-8869-6080f374b1bd-2073", "name": "schedule/taskscan_sunset", "progress": { "state": "COMPLETED", "processed": 0, "total": 0, "successes": 0, "failures": 0 }, "started": "2017-12-19T11:45:53.433Z", "ended": "2017-12-19T11:45:53.438Z" }, { "_id": "b32aafe5-b484-4d00-89ff-83554341f321-9970", "name": "schedule/taskscan_sunset", "progress": { "state": "ACTIVE", "processed": 80, "total": 980, "successes": 80, "failures": 0 }, "started": "2017-12-19T16:41:04.185Z", "ended": null } ] ... }
Each scanning task has the following properties:
_id-
The unique ID of that task instance.
name-
The name of the scanning task, determined by the name of the schedule configuration file or over REST when the task is executed.
started-
The time at which the scanning task started.
ended-
The time at which the scanning task ended.
progress-
The progress of the scanning task, summarised in the following fields:
failuresThe number of records not able to be processed.
successesThe number of records processed successfully.
totalThe total number of records.
processedThe number of processed records.
stateThe current state of the task,
INITIALIZED,ACTIVE,COMPLETED,CANCELLED, orERROR.
The number of processed tasks whose details are retained is governed by the openidm.taskscanner.maxcompletedruns property in the conf/system.properties file. By default, the last 100 completed tasks are retained.
Manage scanning tasks using the IDM admin UI
The task scanner queries a set of managed objects, then executes a script on the objects returned in the query result. The scanner then sets a field on a specific managed object property to indicate the state of the task. Before you start, you must set up this object type property on the managed user object.
In the example that follows, the task scanner queries managed user objects and returns objects whose sunset property holds a date that is prior to the current date. The scanner then sets the state of the task in the task-completed field of the user’s sunset property.
-
To access the IDM admin UI from the IDM console, click Native Consoles > Identity Management > Configure > Schedules > Add Schedule.
-
Enable the schedule, and set the times that the task should run.
-
Under Perform Action, select Execute a script on objects returned by a query (Task Scanner).
-
Select the managed object on which the query should be run; in this case,
user. -
Build the query that will be run against the managed user objects.
The following query returns all managed users whose
sunsetdate is prior to the current date (${Time.now}) and for whom thesunsettask has not already completed (${taskState.completed} pr):((/sunset/date lt \"${Time.now}\") AND !(${taskState.completed} pr)) -
In the Object Property Field, enter the property whose values will determine the state of the task; in this case,
sunset. -
In the Script field, enter an inline script.
The sample task scanner runs the following script on the managed users returned by the previous query:
var patch = [{ "operation" : "replace", "field" : "/active", "value" : false },{ "operation" : "replace", "field" : "/accountStatus", "value" : "inactive" }]; openidm.patch(objectID, null, patch);This script essentially deactivates the accounts of users returned by the query by setting the value of their
activeproperty tofalse. -
Configure the advanced properties of the schedule described in Configure Schedules.