Enhance implicit sync and liveSync
You can propagate changes to and from Advanced Identity Cloud and external systems through implicit synchronization and liveSync. These refer to the automatic synchronization of changes from and to the managed objects (such as users or roles) repository. For more information, refer to Synchronization types.
The following topics describe the mechanisms for configuring these automatic synchronization mechanisms.
| Before you modify sync configuration settings, mappings and connectors must be configured. For more information, refer to resource mappings and sync connectors. |
Disable automatic synchronization operations
By default, all mappings are automatically synchronized. A change to a managed object is automatically synchronized to all resources for which the managed object is configured as a source. If liveSync is enabled for a system, changes to an object on that system are automatically propagated to the managed object repository.
To prevent automatic synchronization for a specific mapping, set the enableSync property of that mapping to false. In the following example, implicit synchronization is disabled. This means that changes to objects in the internal repository are not automatically propagated to the LDAP directory. To propagate changes to the LDAP directory, reconciliation must be launched manually:
{
"mappings" : [
{
"name" : "managedUser_systemLdapAccounts",
"source" : "managed/realm-name_user",
"target" : "system/ldap/account",
"enableSync" : false,
...
}If enableSync is set to false for a mapping from a system resource to managed/realm-name_user (for example "systemLdapAccounts_managedUser"), liveSync is disabled for that mapping.
|
To disable automatic synchronization from the IDM admin UI:
|
Configure the liveSync retry policy
If a liveSync operation fails, IDM reattempts the change an infinite number of times until the change is successful. This behavior can increase data consistency in the case of transient failures (for example, when the connection to the database is temporarily lost). However, in situations where the cause of the failure is permanent (for example, if the change does not meet certain policy requirements) the change will never succeed, regardless of the number of attempts. In this case, the infinite retry behavior can effectively block subsequent liveSync operations from starting.
To avoid this, you can configure a liveSync retry policy to specify the number of times a failed modification should be reattempted, and what should happen if the modification is unsuccessful after the specified number of attempts.
Ultimately, a scheduled reconciliation operation forces consistency; however, to prevent repeated retries that block liveSync, restrict the number of times you attempt the same modification. You can then specify what happens to failed liveSync changes.
The failed modification can be stored in a dead letter queue , discarded, or reapplied. Alternatively, an administrator can be notified of the failure by email or by some other means. This behavior can be scripted. The default configuration in the samples provided with IDM is to retry a failed modification five times, and then to log and ignore the failure.
You configure the liveSync retry policy in the connector configuration. The sample connector configurations have a retry policy defined as follows:
"syncFailureHandler" : {
"maxRetries" : 5,
"postRetryAction" : "logged-ignore"
},maxRetries-
Specifies the number of attempts that IDM should make to process the failed modification.
The value of this property must be a positive integer, or
-1. A value of zero indicates that failed modifications should not be reattempted. In this case, the post-retry action is executed immediately when a liveSync operation fails. A value of-1(or omitting themaxRetriesproperty, or the entiresyncFailureHandlerfrom the configuration) indicates that failed modifications should be retried an infinite number of times. In this case, no post retry action is executed.The default retry policy relies on the scheduler, or whatever invokes liveSync. Therefore, if retries are enabled and a liveSync modification fails, IDM will retry the modification the next time that liveSync is invoked.
postRetryAction-
Indicates what should happen if the maximum number of retries has been reached (or if
maxRetrieshas been set to zero). The post-retry action can be one of the following:-
logged-ignoreIDM should ignore the failed modification, and log its occurrence.
-
dead-letter-queueIDM should save the details of the failed modification in a table in the repository (accessible over REST at
repo/synchronisation/deadLetterQueue/provisioner-name). -
scriptSpecifies a custom script that should be executed when the maximum number of retries has been reached. For information about using custom scripts in the configuration, refer to scripting functions. In addition to the regular objects described in that section, the following objects are available in the script scope:
syncFailure-
Provides details about the failed record. The structure of the
syncFailureobject is as follows:"syncFailure" : { "token" : the ID of the token, "systemIdentifier" : a string identifier that matches the "name" property in the connector configuration, "objectType" : the object type being synced, one of the keys in the "objectTypes" property in the connector configuration, "uid" : the UID of the object (for example uid=joe,ou=People,dc=example,dc=com), "failedRecord", the record that failed to synchronize },To access these fields, include
syncFailure.fieldnamein your script. failureCause-
Provides the exception that caused the original liveSync failure.
failureHandlers-
Two synchronization failure handlers are provided by default:
-
loggedIgnoreindicates that the failure should be logged, after which no further action should be taken. -
deadLetterQueueindicates that the failed record should be written to a specific table in the repository, where further action can be taken.
-
To invoke one of the internal failure handlers from your script, use a call similar to the following (shown here for JavaScript):
failureHandlers.deadLetterQueue.invoke(syncFailure, failureCause); -
The following liveSync retry policy configuration specifies a maximum of four retries before the failed modification is sent to the dead letter queue:
...
"syncFailureHandler" : {
"maxRetries" : 4,
"postRetryAction" : dead-letter-queue
},
...In the case of a failed modification, a message similar to the following is output to the logs:
INFO: sync retries = 1/4, retrying
IDM reattempts the modification the specified number of times. If the modification is still unsuccessful, a message similar to the following is logged:
INFO: sync retries = 4/4, retries exhausted
Jul 19, 2013 11:59:30 AM
org.forgerock.openidm.provisioner.openicf.syncfailure.DeadLetterQueueHandler invoke
INFO: uid=jdoe,ou=people,dc=example,dc=com saved to dead letter queueThe log message indicates the entry for which the modification failed (uid=jdoe, in this example).
You can view the failed modification in the dead letter queue, over the REST interface, as follows:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/repo/synchronisation/deadLetterQueue/ldap?_queryFilter=true&_fields=_id" { "result": [ { "_id": "4", "_rev": "000000001298f6a6" } ], ... }
To view the details of a specific failed modification, include its ID in the URL:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/repo/synchronisation/deadLetterQueue/ldap/4" { "objectType": "account", "systemIdentifier": "ldap", "failureCause": "org.forgerock.openidm.sync.SynchronizationException: org.forgerock.openidm.objset.ConflictException: org.forgerock.openidm.sync.SynchronizationException: org.forgerock.openidm.script.ScriptException: ReferenceError: \"bad\" is not defined. (PropertyMapping/mappings/0/properties/3/condition#1)", "token": 4, "failedRecord": "complete record, in xml format" "uid": "uid=jdoe,ou=people,dc=example,dc=com", "_rev": "000000001298f6a6", "_id": "4" }
|
The |
Improve reliability with queued synchronization
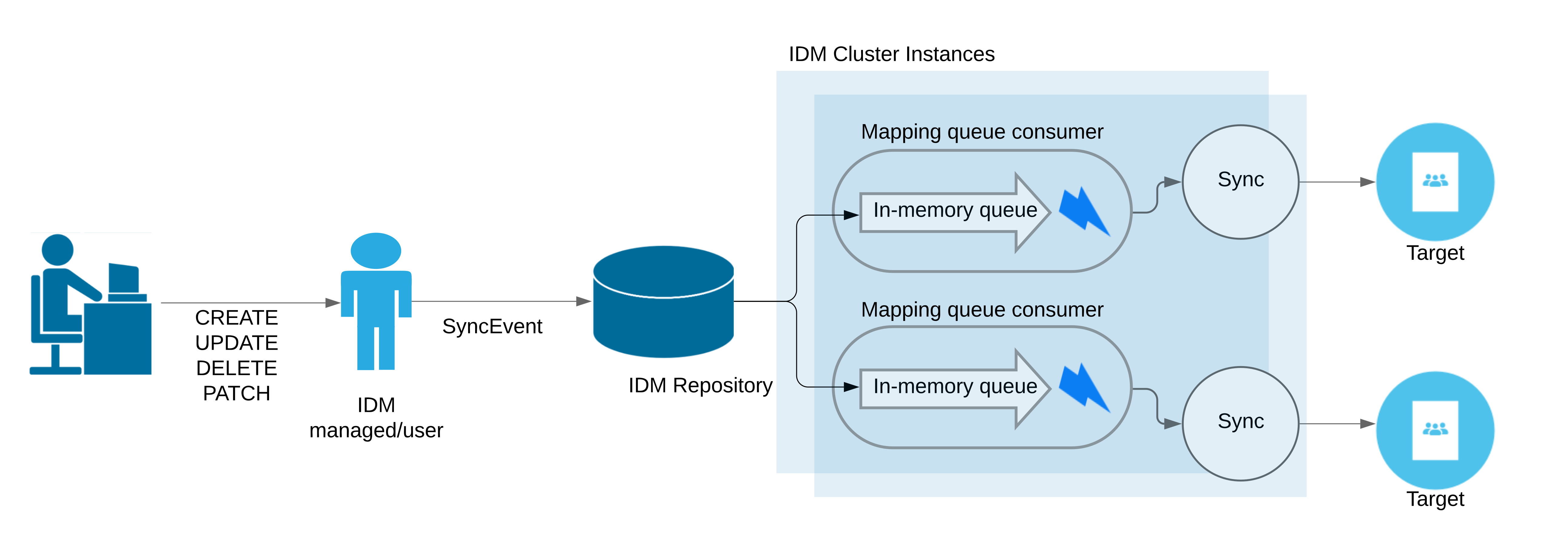
By default, IDM implicitly synchronizes managed object changes out to all resources for which the managed object is configured as a source. If there are several targets that must be synchronized, these targets are synchronized one at a time, one after the other. If any of the targets is remote or has a high latency, the implicit synchronization operations can take some time, delaying the successful return of the managed object change.
To decouple the managed object changes from the corresponding synchronizations, you can configure queued synchronization, which persists implicit synchronization events to the IDM repository. Queued events are then read from the repository and executed according to the queued synchronization configuration.
Because synchronization operations are performed in parallel, queued synchronization can improve performance if you have several fast, reliable targets. However, queued synchronization is also useful when your targets are slow or unreliable, because the managed object changes can complete before all targets have been synchronized.
The following illustration shows how synchronization operations are added to a local, in-memory queue. Note that this queue is distinct from the repository queue for synchronization events:
Configure queued synchronization
Queued synchronization is disabled by default. To enable it, add a queuedSync object to your mapping, as follows:
{
"mappings" : [
{
"name" : "managedUser_systemLdapAccounts",
"source" : "managed/realm-name_user",
"target" : "system/ldap/account",
"links" : "systemLdapAccounts_managedUser",
"queuedSync" : {
"enabled" : true,
"pageSize" : 100,
"pollingInterval" : 1000,
"maxQueueSize" : 20000,
"maxRetries" : 5,
"retryDelay" : 1000,
"postRetryAction" : "logged-ignore"
},
...
}
]
}
|
The queuedSync object has the following configuration:
enabled-
Specifies whether queued synchronization is enabled for that mapping. Boolean,
true, orfalse. pageSize(integer)-
Specifies the maximum number of events to retrieve from the repository queue within a single polling interval. The default is
100events. pollingInterval(integer)-
Specifies the repository queue polling interval, in milliseconds. The default is
1000ms. maxQueueSize(integer)-
Specifies the maximum number of synchronization events that can be accepted into the in-memory queue. The default is
20000events. maxRetries(integer)-
The number of retries to perform before invoking the
postRetryaction. Most sample configurations set the maximum number of retries to5. To set an infinite number of retries, either omit themaxRetriesproperty, or set it to a negative value, such as-1. retryDelay(integer)-
In the event of a failed queued synchronization operation, this parameter specifies the number of milliseconds to delay before attempting the operation again. The default is
1000ms. postRetryAction-
The action to perform after the retries have been exhausted. Possible options are
logged-ignore,dead-letter-queue, andscript. These options are described in Configure the LiveSync Retry Policy. The default action islogged-ignore.
|
Retries occur synchronously to the failure. For example, if the |
Tune queued synchronization
Queued synchronization employs a single worker thread. While implicit synchronization operations are being generated, that worker thread should always be occupied. The occupation of the worker thread is a function of the pageSize, the pollingInterval, the latency of the poll request, and the latency of each synchronization operation for the mapping.
For example, assume that a poll takes 500 milliseconds to complete. Your system must provide operations to the worker thread at approximately the same rate at which the thread can consume events (based on the page size, poll frequency, and poll latency). Operation consumption is a function of the notifyaction.execution for that particular mapping. If the system does not provide operations fast enough, implicit synchronization will not occur as optimally as it could. If the system provides operations too quickly, the operations in the queue could exceed the default maximum of 20000. If the maxQueueSize is reached, additional synchronization events will result in a RejectedExecutionException.
Depending on your hardware and workload, you might need to adjust the default pageSize, pollingInterval, and maxQueueSize.
Monitor the queued synchronization metrics; specifically, the rejected-executions, and adjust the maxQueueSize accordingly. Set a large enough maxQueueSize to prevent slow mappings and heavy loads from causing newly-submitted synchronization events to be rejected.
Monitor the synchronization latency using the sync.queue.mapping-name.poll-pending-events metric.
Manage the synchronization queue
You can manage queued synchronization events over the REST interface, at the openidm/sync/queue endpoint. The following examples show the operations that are supported on this endpoint:
List all events in the synchronization queue:
curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/sync/queue?_queryFilter=true" { "result": [ { "_id": "03e6ab3b-9e5f-43ac-a7a7-a889c5556955", "_rev": "0000000034dba395", "mapping": "managedUser_systemLdapAccounts", "resourceId": "e6533cfe-81ad-4fe8-8104-55e17bd9a1a9", "syncAction": "notifyCreate", "state": "PENDING", "resourceCollection": "managed/realm-name_user", "nodeId": null, "createDate": "2018-11-12T07:45:00.072Z" }, { "_id": "ed940f4b-ce80-4a7f-9690-1ad33ad309e6", "_rev": "000000007878a376", "mapping": "managedUser_systemLdapAccounts", "resourceId": "28b1bd90-f647-4ba9-8722-b51319f68613", "syncAction": "notifyCreate", "state": "PENDING", "resourceCollection": "managed/realm-name_user", "nodeId": null, "createDate": "2018-11-12T07:45:00.150Z" }, { "_id": "f5af2eed-d83f-4b70-8001-8bc86075134f", "_rev": "00000000099aa321", "mapping": "managedUser_systemLdapAccounts", "resourceId": "d2691a45-0a10-4f51-aa2a-b6854b2f8086", "syncAction": "notifyCreate", "state": "PENDING", "resourceCollection": "managed/realm-name_user", "nodeId": null, "createDate": "2018-11-12T07:45:00.276Z" }, ... ], "resultCount": 8, "pagedResultsCookie": null, "totalPagedResultsPolicy": "NONE", "totalPagedResults": -1, "remainingPagedResults": -1 }
Query the queued synchronization events based on the following properties:
-
mapping—the mapping associated with this event. For example:curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/sync/queue?_queryFilter=mapping+eq+'managedUser_systemLdapAccount'"
-
nodeId—the ID of the node that has acquired this event. -
resourceId—the source object resource ID. -
resourceCollection—the source object resource collection. -
_id—the ID of this sync event. -
state—the state of the synchronization event. For example:curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/sync/queue?_queryFilter=state+eq+'PENDING'"
The
stateof a queued synchronization event is one of the following:PENDING—the event is waiting to be processed.
ACQUIRED—the event is being processed by a node. -
remainingRetries—the number of retries available for this synchronization event before it is abandoned. For more information about how synchronization events are retried, refer to Configure the LiveSync Retry Policy. For example:curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/sync/queue?_queryFilter=remainingRetries+lt+2"
-
syncAction—the synchronization action that initiated this event. Possible synchronization actions arenotifyCreate,notifyUpdate, andnotifyDelete. For example:curl \ --header "Authorization: Bearer <token>" \ --header "Accept-API-Version: resource=1.0" \ --request GET \ "https://<tenant-env-fqdn>/openidm/sync/queue?_queryFilter=syncAction+eq+'notifyCreate'"
-
createDate—the date that the event was created.
Recover mappings when nodes are down
Synchronization events for mappings with queued synchronization enabled are processed by a single cluster node. While a node is present in the cluster, that node holds a lock on the specific mapping. The node can release or reacquire the mapping lock if a balancing event occurs (refer to Balance Mapping Locks Across Nodes). However, the mapping lock is held across all events on that mapping. In a stable running cluster, a single node will hold the lock for a mapping indefinitely.
It is possible a node goes down or is removed from the cluster while holding a mapping lock on operations in the synchronization queue. To prevent these operations from being lost, the queued synchronization facility includes a recovery monitor that checks for any orphaned mappings in the cluster.
A mapping is considered orphaned in the following cases:
-
No active node holds a lock on the mapping.
-
The node that holds a lock on the mapping has an instance state of
STATE_DOWN. -
The node that holds a lock on the mapping does not exist in the cluster.
The recovery monitor periodically checks for orphaned mappings. When all orphaned mappings are recovered, it attempts to initialize new queue consumers.
The recovery monitor is enabled by default and executes every 300 seconds. To change the default behavior for a mapping, add the following to the mapping configuration and change the parameters as required:
{
"mappings" : [...],
"queueRecovery" : {
"enabled" : true,
"recoveryInterval" : 300
}
}|
If a queued synchronization job has already been claimed by a node, and that node is shut down, IDM notifies the entire cluster of the shutdown. This lets a different node pick up the job in progress. The recovery monitor takes over jobs in a synchronization queue that have not been fully processed by an available cluster node, so no job should be lost. If you have configured queued synchronization for one or more mappings, do not use the |
Balance mapping locks across nodes
Queued synchronization mapping locks are balanced equitably across cluster nodes. At a specified interval, each node attempts to release and acquire mapping locks based on the number of running cluster nodes. When new cluster nodes come online, existing nodes release sufficient mapping locks for new nodes to pick them up, resulting in an equitable distribution of locks.
Lock balancing is enabled by default, and the interval at which nodes attempt to balance locks in the queue is five seconds.
To change the default configuration, add a queueBalancing object to your mapping and set the following parameters:
{
"mappings" : [...],
"queueBalancing" : {
"enabled" : true,
"balanceInterval" : 5
}
}Synchronization failure compensation
| It is recommended that you first attempt to Improve reliability with queued synchronization before you configure synchronization failure compensation. |
If implicit synchronization fails for a target resource (for example, due to a policy validation failure on the target or the target being unavailable), the synchronization operation stops at that point. In this scenario, a record might be changed in the repository and in the targets on which synchronization was successful but not on the failed target or on any targets that would have been synchronized after the failure. This can result in disparate data sets across resources. Although a reconciliation operation would bring all targets back in sync, reconciliation can be expensive with large data sets.
| If synchronization failure compensation is not accounted for, any issues with connections to an external resource can result in out-of-sync data stores. |
You can configure synchronization failure compensation to:
-
Prevent data sets from becoming out of sync by reverting the implicit synchronization operation if it is not completely successful across all configured mappings.
-
Ensure all resources are synchronized successfully or that the original change is rolled back. This mechanism uses an
onSyncscript hook in the managed object configuration.The
onSynchook calls a script that prevents partial synchronization by reverting a partial change in the event that all resources are not synchronized.
Synchronization failure onSync inline script
(function() {
var _ = require("lib/lodash.js");
if (syncResults.success) {
logger.debug("sync was a success; no compensation necessary");
return;
}
if (request !== null
&& request.additionalParameters !== null
&& request.additionalParameters.compensating === "true") {
logger.debug("already compensating, returning");
return;
}
logger.debug("compensating for " + resourceName);
var params = { "compensating" : true };
switch (syncResults.action) {
case "notifyCreate":
try {
openidm.delete(resourceName.toString(), newObject._rev, params);
} catch (e) {
logger.warn("Was not able to delete {} from compensation script. Exception: {}", resourceName.toString(), e);
}
break;
case "notifyUpdate":
try {
openidm.update(resourceName.toString(), newObject._rev, oldObject, params);
} catch (e) {
logger.warn("Was not able to update {} from compensation script. Exception: {}", resourceName.toString(), e);
}
break;
case "notifyDelete":
try {
openidm.create(resourceName.parent().toString(), resourceName.leaf().toString(), oldObject, params);
} catch (e) {
logger.warn("Was not able to create {} from compensation script. Exception: {}", resourceName.toString(), e);
}
break;
}
logger.debug(resourceName + " sync failure compensation complete");
// throw the error that caused the sync failure
var firstFailure = _.find(syncResults.syncDetails,
function (r) {
return r.result === "FAILED" && r.cause !== undefined;
});
if (firstFailure !== null) {
throw firstFailure.cause;
}
}());With this script:
-
A change to a managed object triggers an implicit synchronization for each configured mapping, in the order in which the mappings are defined. If synchronization is successful for all configured mappings, IDM exits from the script.
If synchronization fails for a particular resource, the
onSynchook invokes inline script. script, which attempts to revert the original change by performing another update to the managed object. This change triggers another implicit synchronization operation to all external resources for which mappings are configured. -
If the synchronization operation fails again, the script is triggered a second time. This time, however, the script recognizes that the change was originally called as a result of a compensation and aborts. IDM logs warning messages related to the sync action (
notifyCreate,notifyUpdate,notifyDelete), along with the error that caused the sync failure. -
Any such errors result in each data store retaining the information it had before implicit synchronization started. This information is stored temporarily in the
oldObjectvariable.